
DRUGONE
人工智能(AI)将在未来几年对科学产生深远影响。然而,对于某一学科领域的专家来说,如何在浩瀚的 AI 文献与快速发展的技术之间找到方向并不容易。作为在植物生物学、神经科学和物理学等不同领域应用 AI 的研究人员,他们也曾面临类似问题。本文总结了研究人员在学习过程中的一些关键体会。
过去几十年,所有科学学科都因计算方法的进步而发生转变,AI 方法正逐渐走到前台。例如,深度学习模型 AlphaFold 推动了蛋白质三维结构预测的突破,使研究人员能够深入理解蛋白质功能,从而推动靶向药物递送。另一个例子是深度强化学习模型被用于控制聚变反应中的等离子体不稳定性,使得聚变首次实现了净能量增益。除此之外,大型语言模型(LLMs)也已被引入科学研究,例如帮助生成神经科学模型或进行理论物理学的分析计算。
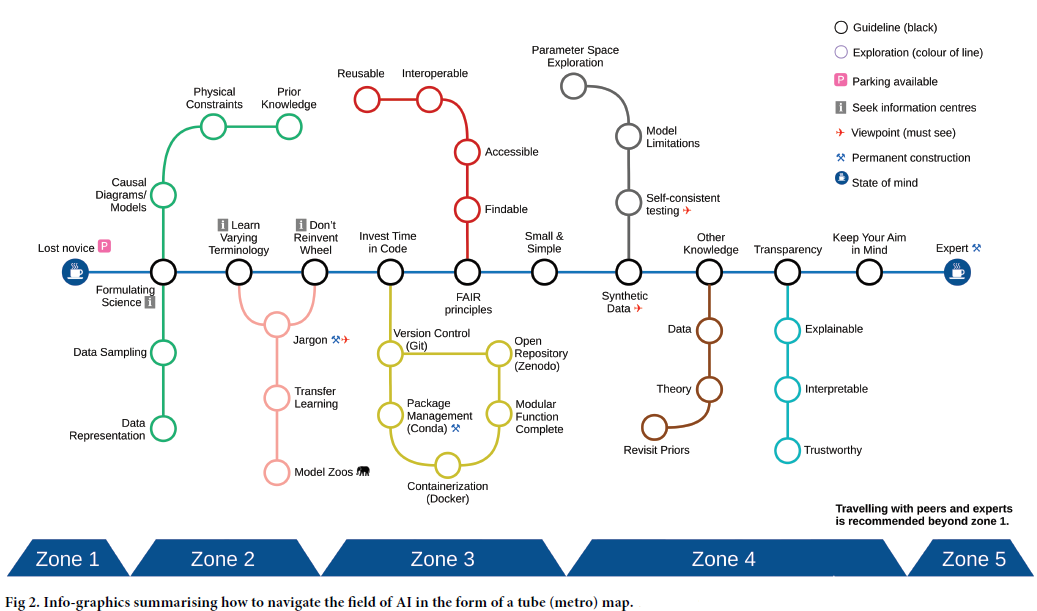
本文主要面向具有一定编程经验、希望在各自学科中应用 AI 方法的早期 STEM 研究人员。因此,研究人员在阐述规则时避免了过多技术细节,而是配以词汇表与教学性说明,帮助读者深入理解并将规则应用到实践中。即使是已有丰富经验的研究人员,也可将这些规则作为教学框架。研究人员希望,无论专业水平如何,读者都能从本文中获益,并在探索 AI 的不同阶段重新审视这些原则。
本文中的“AI”一词采用广义定义,涵盖从统计方法到机器学习、深度学习在内的多种算法。规则的安排遵循科学探索的流程:首先是如何提出科学问题与选择合适的算法;接着是编程实践相关的规则;最后是涉及可解释性、稳健性与伦理考量的部分。
规则 1:明确你的科学问题
在将 AI 应用于科学之前,研究人员需要先界定清晰、客观的科学问题,思考 AI 是否真的能帮助回答这些问题。数据类型和范围直接影响算法的选择。一些 AI 方法需要大量数据,因此需要先判断数据规模与目标是否匹配。
此外,应在使用具体算法前,充分理解并清洗、准备数据。不同的问题可能对应监督学习、无监督学习,或贝叶斯统计与因果推断等方法。无论选择哪条路径,都必须思考模型的质量评估方式,并明确哪些性能指标真正有意义。
规则 2:掌握领域内外的术语
AI 领域术语繁多且跨学科差异显著。相同的技术可能在不同学科有不同名称,而同一个词在不同语境下也可能有多重含义。掌握领域内外的术语有助于研究人员更有效地交流、阅读文献,并拓展跨领域的思维。
除了常规的课程与论文,研讨会与读书小组也能帮助研究人员在沉浸式环境中习得术语。这种与同伴共同学习的方式能提高责任感与学习效率。
规则 3:不要重复造轮子
许多高质量的开源包与现成模型可供直接使用,减少了从零开始实现算法的必要。研究人员应积极借鉴跨学科的方法与解决方案,探索模型库与基础模型,以便在现有成果的基础上继续推进工作。这不仅能节省时间,还可能促成跨领域合作。
对于实验学科的研究人员而言,无法承担大规模数据采集和计算开销时,可以利用迁移学习与数据增强等方法,让先进模型更容易应用。
规则 4:投入时间管理代码
维护代码是确保研究质量与可重复性的关键。研究人员应使用版本控制工具(如 Git)来跟踪变化与协作,建立虚拟环境(如 Conda 或 Docker)以记录依赖版本。代码应模块化、文档清晰,并定期更新。通过竞赛、开源贡献和课程学习,不断提升编程能力。
规则 5:牢记 FAIR 原则
AI 模型要在科学研究中真正有用,必须遵循可查找(Findable)、可获取(Accessible)、可互操作(Interoperable)、可复用(Reusable)的 FAIR 原则。这意味着代码、数据、模型权重尽可能开源,以便他人能够验证、复现和扩展。研究人员还可借助项目管理与 MLOps 工具来提高透明度和复现性。
规则 6:从小而简单的模型开始
虽然最前沿的方法令人向往,但在很多场景下,简单模型已足够高效、可解释且更易实施。研究人员应先建立基线模型作为参考,再逐步尝试复杂模型。比如,在分类任务中,先尝试非深度学习方法,再逐步引入神经网络。与此同时,应避免一次性解决所有问题,而是先聚焦于关键趋势或整体特征。
规则 7:从合成数据入手
当模型效果不佳时,问题可能来自算法,也可能源于数据不足。为区分两者,研究人员可先在合成数据上验证模型。合成数据的优势在于其可控性与透明性,可用于测试模型在不同噪声水平和样本规模下的表现。数据增强也是常用手段,可通过旋转、裁剪、反射等操作扩展训练集,减少过拟合。
规则 8:将先验知识融入模型
虽然机器学习能够直接从数据中学习,但融入物理规律、对称性、逻辑规则或知识图谱等先验知识,能增强模型的稳健性与泛化能力。这样不仅能减少数据需求,还能提高预测的可信度。对于因果推断等方法,先验知识往往是模型设计的起点。
规则 9:追求可解释、可理解与可信赖的 AI
在能源、医疗、金融等关键领域,AI 模型的透明性与可解释性至关重要。方法包括解释输入特征对结果的贡献、可视化神经网络内部激活模式等。尽管可解释性研究不断发展,但仍存在歧义和局限。提升可解释性不仅是伦理需求,也有助于提高可重复性与诊断模型异常。
规则 10:牢记你的科研目标
AI 是强大的工具,但研究人员不能沉迷于模型优化而忽视科学本身。科学严谨性、结果可解释性与真实应用价值应始终优先于单纯的性能指标。研究人员需关注模型在不同数据分布下的泛化能力,并重视不确定性的量化。这些因素决定了 AI 在科学研究中的可靠性与实用性。
讨论
AI 正迅速改变科学研究,但它也可能带来“理解的幻觉”,阻碍真正的科学进步。研究人员需要以批判性心态看待方法与结果的稳健性,避免盲目追随潮流。虽然本文未能涵盖所有挑战,但研究人员希望这十条规则能为探索 AI 的科学工作者提供有益指导,帮助他们更好地应对复杂的未来。
整理 | DrugOne团队
参考资料
Crilly A, Malivert A, Jørgensen ACS, Heaney CE, Vera Gonzalez GI, Ghosh M, et al. (2025) Ten simple rules for navigating AI in science. PLoS Comput Biol 21(7): e1013259. https://doi.org/10.1371/journal.pcbi.1013259

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢