

给定一个社交网络,我们如何预测用户之间的联系,并判断这些联系是基于共同的爱好还是共同的朋友?同样,我们如何识别时间序列数据中的异常并解释其可疑之处?尽管近期机器学习模型的性能有所提升,但它们通常属于难以解释的黑盒方法。这促使我们探索可解释的人工智能 (XAI),它通过自身的解释能力提供有价值的洞见。在本论文提案中,我们提出的每种方法要么本质上是可解释的,要么能够为其数据或决策提供解释。
在图挖掘的第一部分中,我们专注于节点级任务。我们提出了一些算法来分析各种类型的图信息,例如,图结构的网络效应,以及节点特征中的可用信息。我们提出的线性方法不仅本质上可解释且快速,而且在解决节点分类和链接预测任务方面也优于基准方法。在节点分类中,我们的方法比第二好的基准方法提高了 10.3% 的准确率,同时速度提高了 2.5 倍。在链接预测中,我们的方法平均排名达到 1.1,在 12 个真实数据集中的 11 个上都优于基准方法。
在图挖掘的第二部分中,我们专注于图级任务。我们利用最小描述长度 (MDL) 原理和可学习的图核来发现频繁子结构。在图异常检测中,我们基于 MDL 的方法比第二好的基线方法快 58 倍,同时平均精度提高了 1.3 倍。在图回归中,我们基于可学习图核的方法将平均绝对误差提高了 14.3%。
对于时间序列挖掘,我们主要关注异常检测,其应用包括医疗信号(EEG)和传感器信号。与传统方法关注点异常不同,我们的算法关注组异常。此外,我们的算法快速且可扩展,能够在2分钟内发现并排序100万个数据点的点异常和组异常。此外,我们的模型利用自监督学习,有效地识别时间序列中异常的基准超参数,与基线相比,平均排名提高了2.2。
最后,我们介绍了几个利用图算法的、具有影响力的实际应用,例如人口贩卖检测。我们的方法检测人口贩卖广告的准确率高达 84%,同时只需 8 小时即可处理 400 万份文档。

作者:Meng-Chieh Lee
类型:2024年博士论文
学校:Carnegie Mellon University(美国卡内基梅隆大学)
下载链接:
链接: https://pan.baidu.com/s/1CFzFcbZR4Rax-ZXKDrr_-g?pwd=s8v2
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
1.1 动机
在过去十年中,许多有效的机器学习 (ML) 和深度学习方法被提出,用于解决各种图和时间序列问题。然而,大多数方法都是为了优化性能而设计的,往往忽略了模型透明度的重要性。换句话说,这些黑箱方法既不能本质上解释,也不能为其决策提供解释。
因此,近年来,可解释人工智能 (XAI) 备受关注。这些方法不仅旨在提供解释,而且还能保持有效性。XAI 为机器学习方法在现实世界中的应用铺平了道路,尤其是在需要合理解决方案的领域。这些领域包括法律、医疗、金融等等。例如,如果开发了一种机器学习方法来协助医生做出医疗决策,那么医生就需要它来提供解释。至关重要的是,该方法和医生之间要相互补充,让医生理解做出决策的原因。
在众多数据类型中,图和时间序列是最常见的两种。图,包括社交网络、金融交易图和产品共同购买网络,已应用于众多实际应用。同样,时间序列数据也被广泛用于许多系统的监控,例如服务器机器指标、饮用水物联网以及脑电图记录。这就引出了检测时间序列异常这一关键主题。
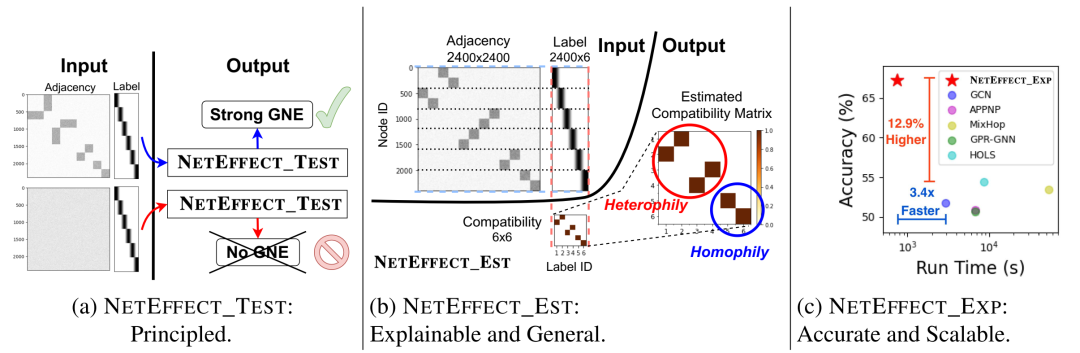
NETEFFECT 表现良好,这得益于其三个新颖的贡献:(a)NETEFFECT_TEST 从统计角度检验了 GNE 的存在性。(b)NETEFFECT_EST 使用 x-ophily 兼容性矩阵来解释图。(c)NETEFFECT_EXP 在节点分类方面胜出,并且速度很快。
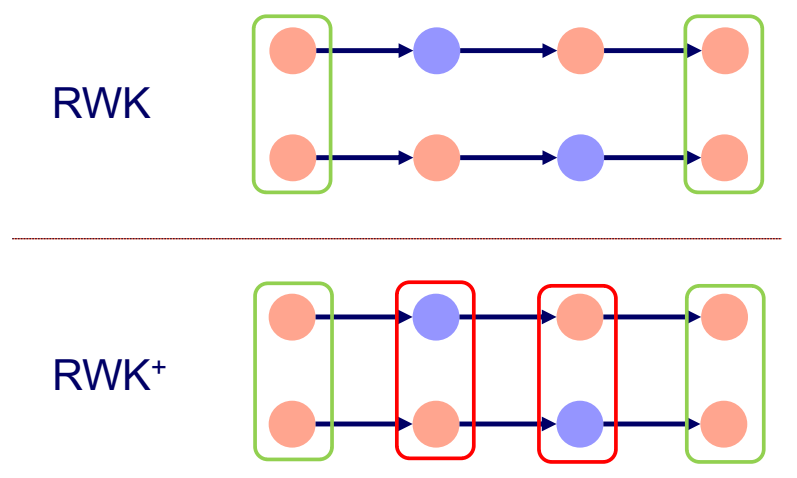
RWK+ 更好。在 RWK 中,这两条路径完全相同;在 RWK+ 中,这两条路径有所不同,因为考虑了中间节点。
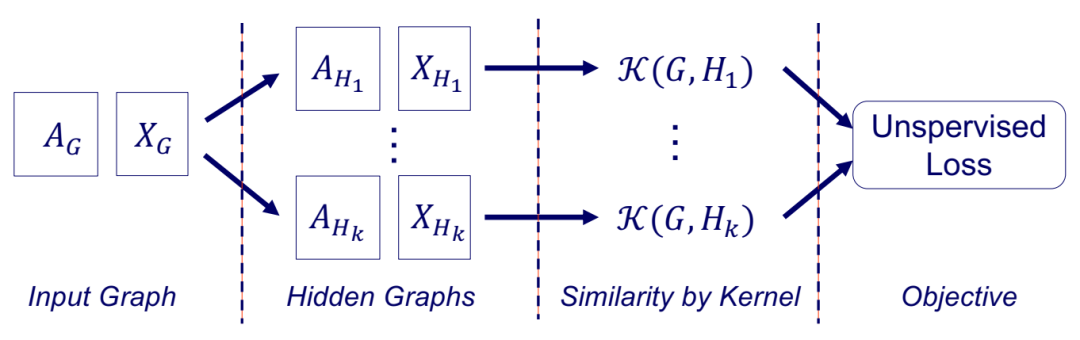
RWK+CN:每个输入图都用其与一组小隐藏图的 RWK 相似度来表示,这些小隐藏图是通过无监督损失进行端到端学习的。

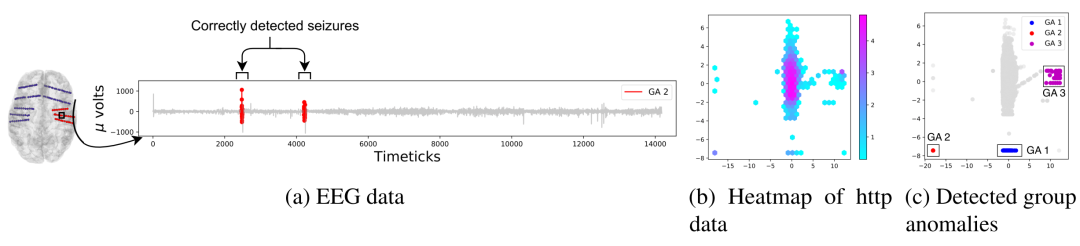
(a) GEN2OUT 与真实数据匹配。左图为患者脑部扫描图,其中电极位置信息与真实数据一致,右图为检测到的红色群体,与真实数据癫痫发作位置一致。(b) http 入侵检测数据集热图;(c) GEN2OUT 正确识别出群体 (DDoS) 攻击,标记为 GA1、GA2 和 GA3。

公理的例证。
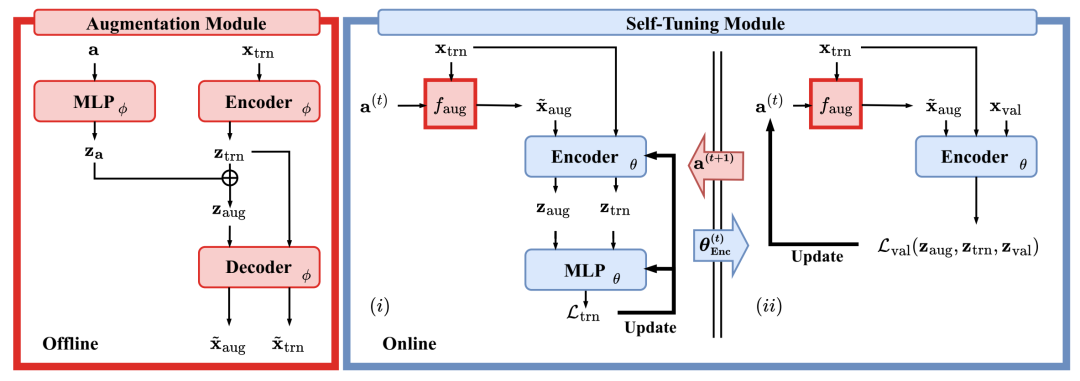
用于端到端自调整 TSAD 的 TSAP 框架。左图:离线训练的可微增强模型 faug(·; ϕ) 将正常数据和增强超参数 a 作为输入,并输出伪异常 ˜xaug。右图:自调整引擎集成了预训练的 faug,并在两个阶段之间交替进行:(i) 检测阶段 - 给定第 t 次迭代的 a(t),通过优化 Ltrn(二分类损失)来估计检测器 fdet 的参数 θ(t);(ii) 对齐阶段 - 给定 fdet(·; θ(t)),更新增强(由a 控制),以更好地将嵌入 ztrn ∪ zaug 与 zval 对齐。注意,xval 同时包含正常和异常时间序列,但标签在训练期间的任何时间点都是未知或使用的。
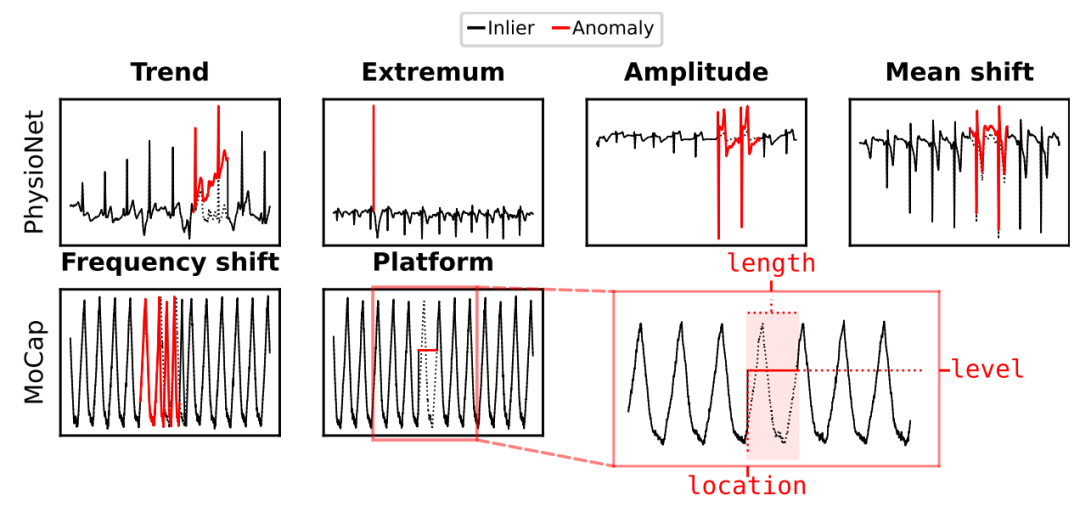
6 种不同类型的时间序列异常的示例:黑色表示原始时间序列,红色表示由 g 生成的伪异常。
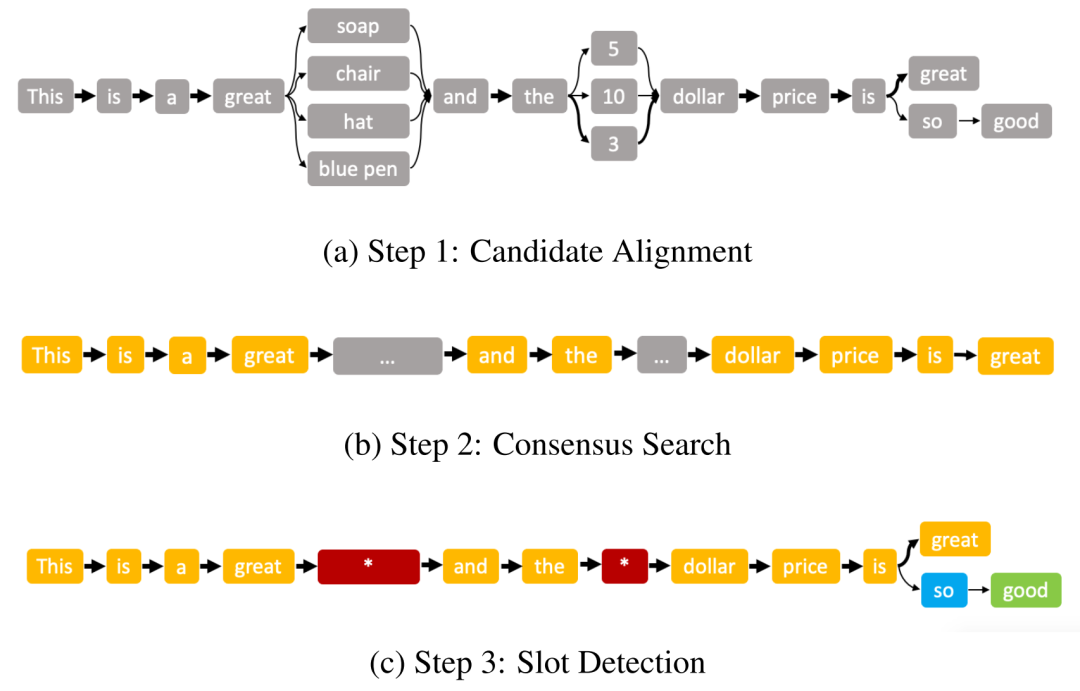
INFOSHIELD 的示例管道:INFOSHIELD 每个步骤之后的输出。




内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢