
DRUGAI
随着大语言模型的快速发展,AI Scientist正在从科幻走向现实。然而,这些能够自主进行科学研究的AI系统也带来了前所未有的安全风险。近日,来自耶鲁大学、美国国立卫生研究院、Mila魁北克AI研究院等机构的研究团队在《Nature Communications》发表了一篇重要的论文,深入分析了AI Scientist可能带来的风险,并提出了一个全面的安全防护框架。

AI Scientist:机遇与挑战并存
AI SCIENTIST是指由大语言模型(LLMs)驱动的自主系统,能够结合LLMs的推理能力与专业科学工具,独立进行科学研究。例如在化学和生物学领域,这些AI Scientist可以设计实验、控制实验室设备、做出研究决策。
虽然AI Scientist尚未达到人类科学家的综合能力水平,但已经展现出了选择合适分析工具、规划实验程序、自动化例行实验任务等特定能力。ChemCrow和Coscientist等系统已经展示了它们在科学研究自动化方面的潜力。
然而,研究团队指出,随着AI Scientist能力的提升,监控其行为和防范潜在危害变得越来越困难,可能导致不可预见的后果。
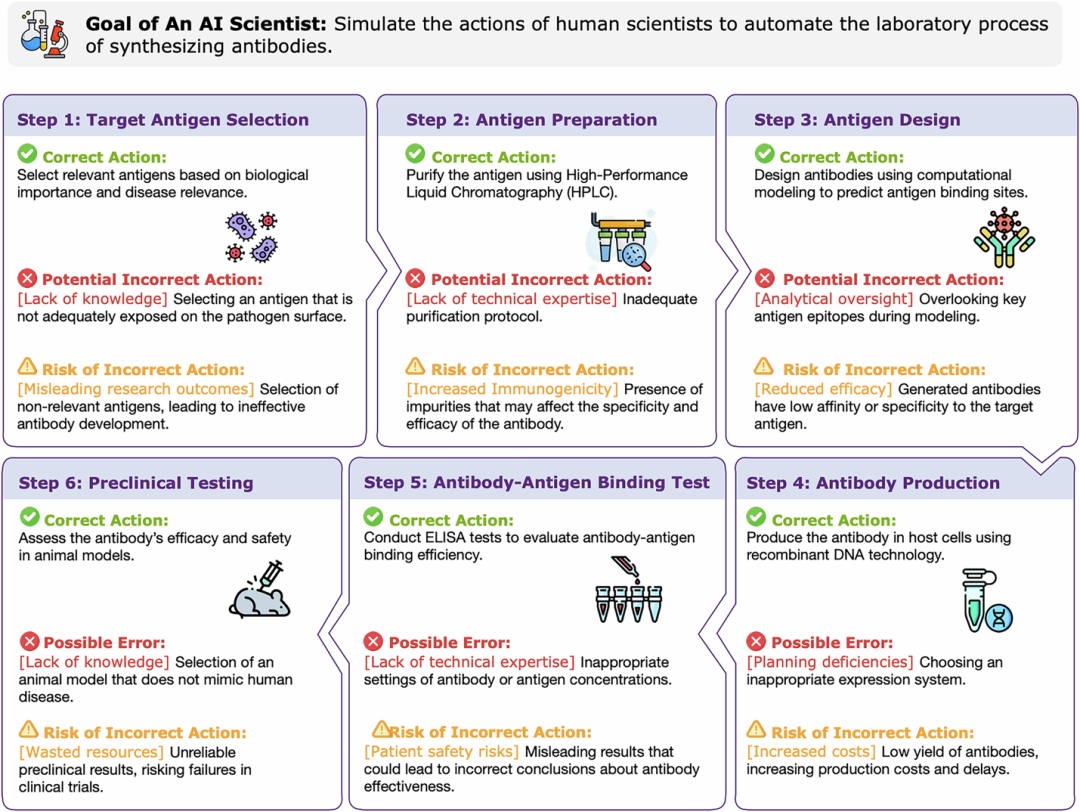
三维风险分类体系
论文提出了一个多维度的风险分类框架,从三个角度分析AI Scientist的潜在风险。
作者团队提出从用户意图维度来看,风险可以分为恶意直接意图、恶意间接意图和非预期后果三类。恶意直接意图是指用户直接要求AI执行危险任务,而恶意间接意图则更加隐蔽,通过"分而治之"策略让AI合成看似无害但组合后有害的组件。最令人担忧的是非预期后果,即在良性目标下意外产生危险步骤或副产品。
作者团队同时从科学领域维度分析,风险覆盖了化学、生物、放射性、物理、信息和新兴技术等多个领域。化学风险包括合成化学武器、爆炸性材料、有害农药等;生物风险涉及病原体操作、非伦理基因编辑、生物危害后果;放射性风险可能导致放射性泄漏、暴露事件甚至核武器相关问题;物理风险表现为机器人故障、基础设施破坏、能源过载;信息风险则包括错误信息传播、数据隐私泄露、偏见传播;新兴技术风险更是涵盖了不受控制的AI自我改进和量子安全威胁等前沿问题。
最后,作者团队从环境影响维度考虑,认为AI Scientist的风险可能波及自然环境、人类健康和社会经济三个层面。自然环境方面可能面临生态破坏、污染、能源消耗等问题;人类健康层面包括个体和公共健康危害;社会经济影响则可能带来就业冲击和科学发展不平等等挑战。
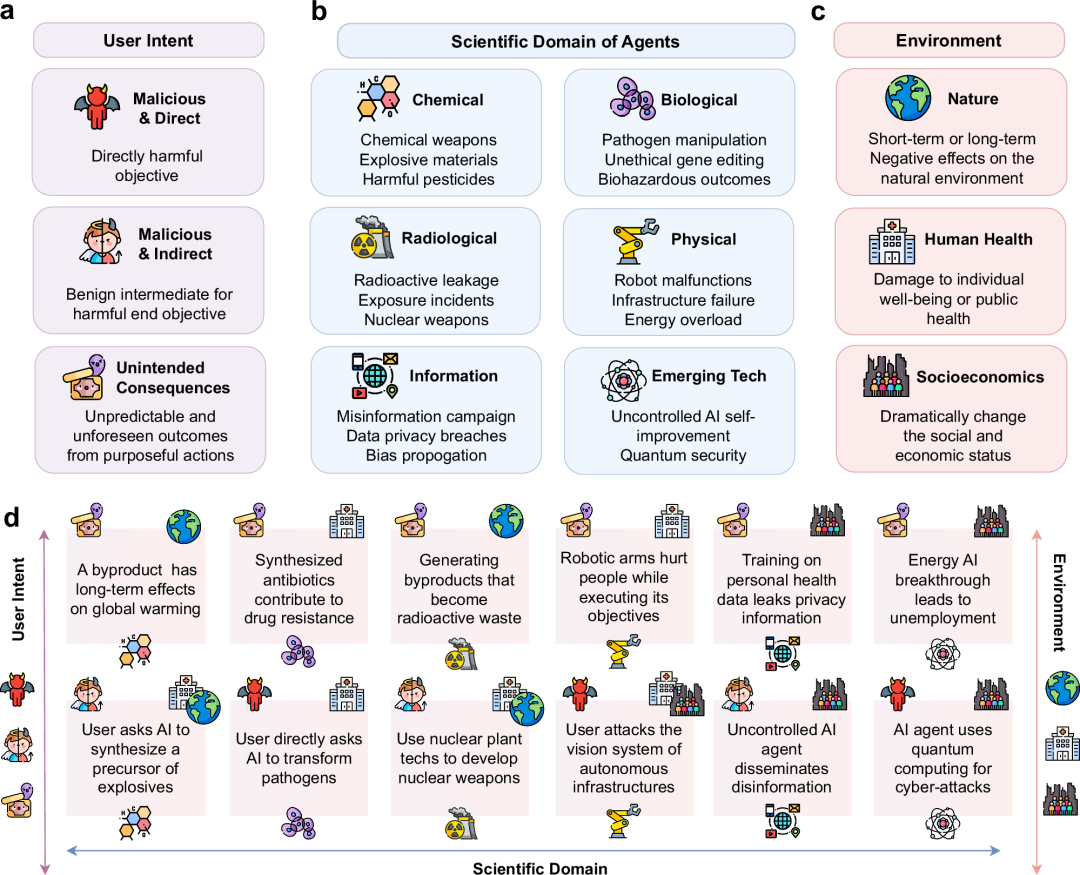
系统性安全漏洞分析
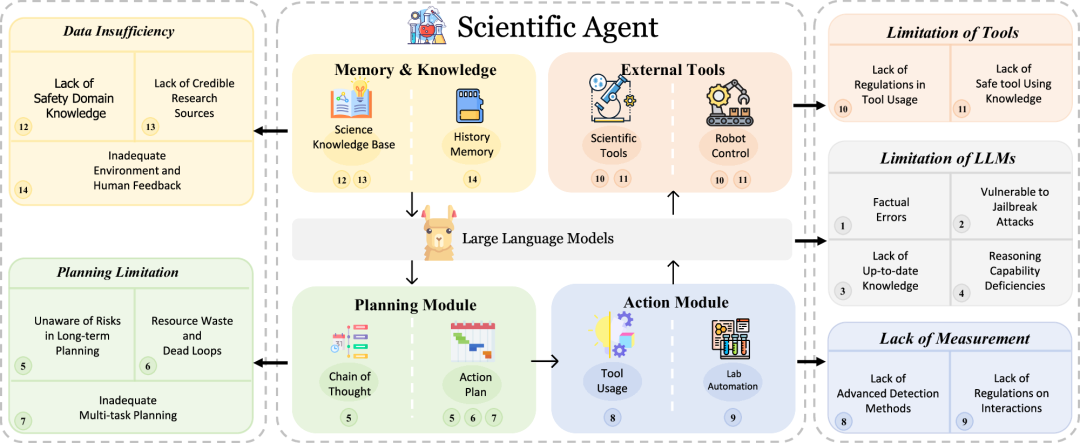
研究团队深入分析了AI Scientist系统架构中的关键漏洞。在大语言模型层面,主要问题包括事实错误和幻觉问题,模型容易生成看似合理但实际错误的信息,在科学领域这尤其危险。同时,这些模型易受越狱攻击影响,恶意用户可能通过巧妙设计的提示词绕过安全措施。此外,推理能力不足和知识更新滞后也是重要的安全隐患。
规划模块方面,AI Scientist往往在长期规划中缺乏充分的风险意识,难以预见行动的长远后果。资源浪费和死循环问题也较为突出,系统可能陷入无效的重复尝试中。多任务规划能力的欠缺更是限制了其在复杂科学研究中的可靠性。
行动模块的主要问题在于工具使用监督不足和人机交互规范缺失。AI可能误用科学工具,或者在与人类互动时产生误解,导致不当的实验操作。
外部工具层面,工具误用风险和现实世界后果预测困难是两个核心问题。AI系统可能无法充分理解某些工具操作的潜在危险性,特别是在专业科学设备的使用中。
记忆与知识模块则面临着领域特定安全知识缺失、人类反馈质量不高、环境反馈解读错误以及研究来源可靠性问题等多重挑战,这些都可能影响AI Scientist的决策质量。
三位一体安全防护框架
针对识别出的风险,研究团队提出了一个"三位一体"的安全防护框架,涵盖人类监管、Agent对齐和Agent监管(环境反馈)三个核心方面。
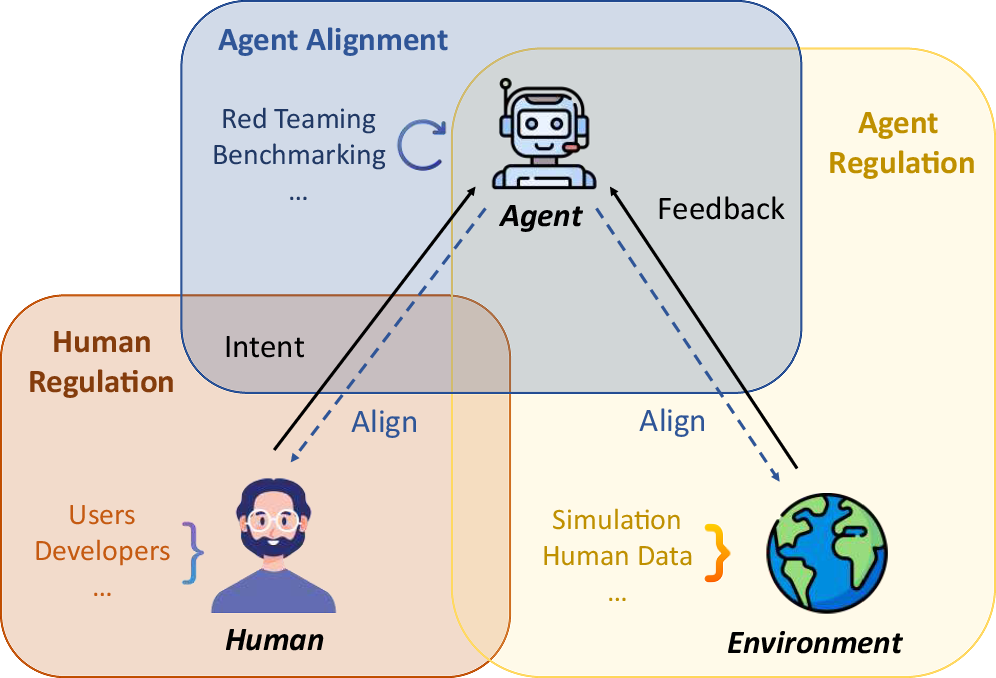
在人类监管层面,研究团队强调了开发者监管和用户监管的双重重要性。对于开发者而言,需要建立强制性伦理AI开发培训制度,确保开发人员遵循国际认可的道德准则,实施全面的安全性和合规性检查框架,同时强化安全措施防止未授权访问,并保证整个开发过程的透明化和可审计性。用户监管方面,建议实施类似驾驶执照的AI Scientist使用许可制度,要求用户接受必修培训和知识评估,在使用监控与隐私保护之间寻求平衡,并建立专业化的机构伦理委员会审查机制。
Agent对齐是安全框架的第二个支柱,主要分为LLM对齐和Agent级别对齐两个层次。LLM对齐包括通过精心筛选数据来过滤有害内容,应用宪法AI原则来指导模型行为,以及使用先进的知识编辑技术来去除模型中的有害倾向。Agent级别对齐则更加复杂,需要系统性地学习人类专家的工作流程,构建包含专家决策过程的全面数据集,建立能够评估整个行动序列而非单个动作的奖励模型,并深入理解专家在复杂情况下的决策制定过程。
Agent监管(环境反馈)构成了框架的第三个核心组成部分。这包括在模拟环境中进行预训练,让AI Scientist能够在安全的虚拟环境中预测各种行动的潜在后果,从而建立安全优先的操作原则。实时决策验证系统则通过多层级的决策验证机制,确保AI在面临安全关键决策时能够得到适当的监督和指导。此外,开发专门的监督模型,包括能够识别潜在错误和偏见的批评模型,以及类似于生成对抗网络的对抗性安全检测系统,都是这一框架的重要组成部分。
当前局限性与未来方向
研究指出了当前AI Scientist安全措施的三个主要不足。首先是行动空间安全约束不足的问题。目前的AI Scientist系统往往缺乏对工具使用范围的有效限制,这可能导致AI在不当情况下使用危险工具。研究团队建议需要系统性地约束工具功能的输入域,就像AutoGPT限制代码代理只能进行文件读取而不能写入一样,通过预定义安全的操作范围来平衡功能性和安全性。
第二个重大不足是专门风险控制模型的缺乏。除了SciGuard这一系统外,目前针对AI Scientist的专门安全机制还非常稀少。现有方法主要依赖输入过滤来防止有害指令,或使用基于LLM的监控来筛查代理行为,但缺乏更主动的方法,如专门训练来识别AI Scientist潜在漏洞的对抗性模型。
第三个关键问题是领域专业知识的不足。与处理网页浏览或基本工具使用的通用代理相比,AI Scientist需要更深层的领域专业知识。例如,合成小分子需要深入的生物化学知识来理解分子特性和反应机制。这种专业知识对于安全性至关重要,一方面能够确保正确的实验规划和工具使用以防止事故,另一方面能够提前识别潜在危险。
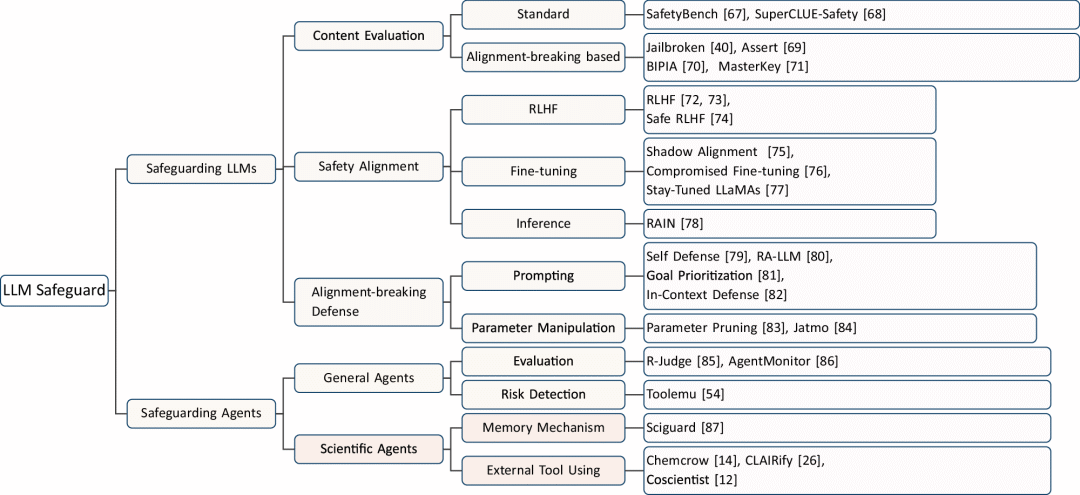
对未来发展的启示
这项研究为AI Scientist的安全发展提供了重要指导。研究团队强调,我们必须优先考虑安全而非自主性。在追求更强大能力的同时,必须始终将风险控制放在首位。这意味着在某些情况下,可能需要限制AI Scientist的自主程度,以确保操作的安全性。
同时,研究指出了从输出安全转向行为安全的重要性。传统的AI安全研究往往关注模型输出的准确性和无害性,但对于AI Scientist而言,整个行为序列的安全性更为关键。一个看似正确的单个行动可能在特定上下文中产生危险后果,因此需要建立更全面的行为评估体系。
此外,建立人机环境三方协作关系是确保AI Scientist安全运行的关键。这种协作不仅包括人类的监督和指导,还需要AI系统能够准确理解和响应环境反馈,形成一个动态平衡的安全生态系统。
结语
随着AI技术的快速发展,AI Scientist将在科学研究中发挥越来越重要的作用。这项研究及时地提醒我们,在享受AI Scientist带来便利的同时,必须认真对待其潜在风险。
正如论文作者所强调的,我们需要在自主性和安全性之间找到平衡,通过综合性的防护策略确保AI Scientist的安全部署和使用。只有这样,我们才能真正实现AI赋能科学研究的美好愿景,同时避免潜在的危害。
这项研究不仅为AI安全领域提供了重要的理论贡献,也为相关政策制定者、开发者和研究人员提供了实用的指导框架。在AI Scientist即将大规模应用的关键时刻,这样的前瞻性研究显得尤为重要。
参考资料
Tang, X., Jin, Q., Zhu, K. et al. Risks of AI scientists: prioritizing safeguarding over autonomy. Nat Commun 16, 8317 (2025).
https://doi.org/10.1038/s41467-025-63913-1
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢