
然而,开发智能体并测试这些行为并非易事。如果你曾尝试过调试自己的智能体,可能会体会到其中的繁琐和挫败感。现有的评测环境通常与特定任务紧密耦合,缺乏真实世界的灵活性,也无法反映开放世界中混乱的现实:模拟页面不会加载失败,事件不会自发发生,也不存在异步混乱。
因此,我们很高兴地介绍 Gaia2 ——智能体基准 GAIA 的后续版本。它能够分析更复杂的行为。Gaia2 与开放的 Meta Agents Research Environments (ARE) 框架一同发布,用于运行、调试和评测智能体。ARE 可以模拟复杂、接近真实世界的条件,并支持定制化,以便进一步研究智能体行为。Gaia2 数据集以 CC BY 4.0 许可证发布,ARE 框架则以 MIT 许可证开源。
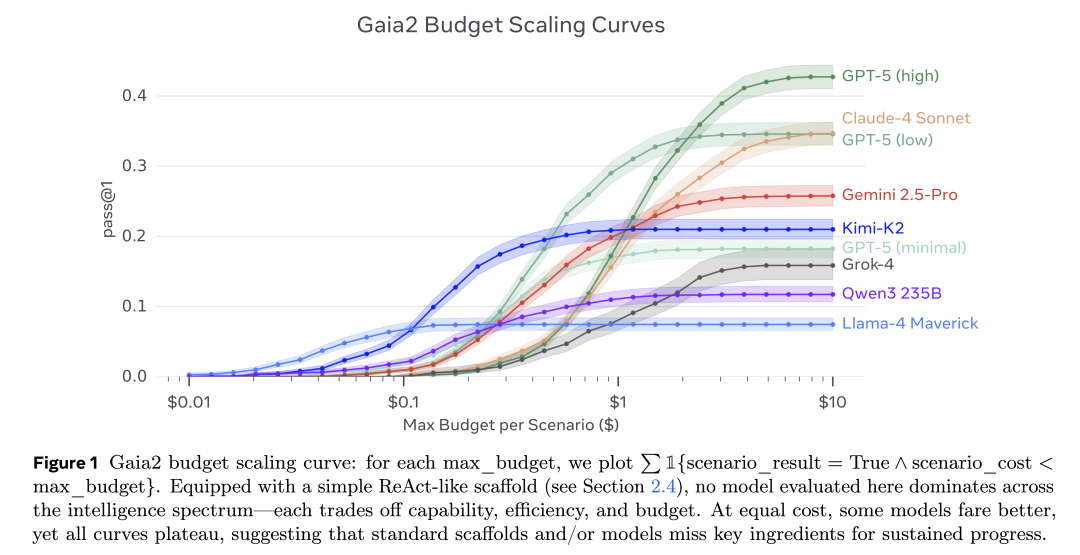
图 1:Gaia2 的预算扩展曲线(Budget Scaling Curves)。随着预算增加,智能体在任务上的表现逐渐提升,用于展示在复杂环境中智能体能力随资源投入的变化趋势。
GAIA 是 2023 年发布的一个智能体基准测试,包含三类信息检索问题,需要工具调用、网页浏览和推理能力才能完成。两年过去,如今最简单的题目对模型来说已经过于容易,而社区也逐渐接近攻克最难的部分问题,因此,是时候推出一个全新且更具挑战性的智能体基准了!这就是 Gaia2 —— GAIA 的全新升级版本,在能力覆盖与研究深度上都有大幅拓展!
相比于只读的 GAIA,Gaia2 升级为可读写的评测基准,更加关注交互行为与复杂性管理。在 Gaia2 中,智能体不仅要完成搜索与检索任务,还需要在充满不确定性和时间敏感性的指令下执行操作,并在包含可控故障的嘈杂环境中运行。这一设定比以往任何模拟环境都更接近真实世界。我们希望测试智能体在以下场景下的表现:
当工具或 API 偶尔失效时如何应对; 如何在严格的时间窗口中规划一系列动作; 如何快速适应突发事件。
这意味着智能体将面临全新的复杂性挑战!
为此,我们设计了以下任务组(基于全新创作的 1000 个人工场景):
执行能力(Execution):多步骤指令执行与工具使用(如更新联系人信息) 搜索能力(Search):跨来源信息收集(如从 WhatsApp 获取朋友所在城市) 歧义处理(Ambiguity Handling):澄清冲突请求(如解决日程冲突) 适应性(Adaptability):应对模拟环境中的变化(如根据后续信息修改邮件) 时间/时序推理(Time/Temporal Reasoning):处理时间敏感任务(如延迟 3 分钟后再叫车) 智能体间协作(Agent-to-Agent Collaboration):在无直接 API 访问的情况下进行智能体间通信 噪声容忍度(Noise Tolerance):在 API 故障和环境不稳定条件下保持稳健
延续 GAIA 的设计理念,这些场景不依赖专业知识 理论上人类可以轻松达到 100% 完成度,从而方便模型开发者进行调试和改进。
如果想要深入体验该基准,欢迎查看我们的数据集和在线 demo。
数据集:
https://huggingface.co/datasets/meta-agents-research-environments/gaia2
在线demo:
https://huggingface.co/spaces/meta-agents-research-environments/demo
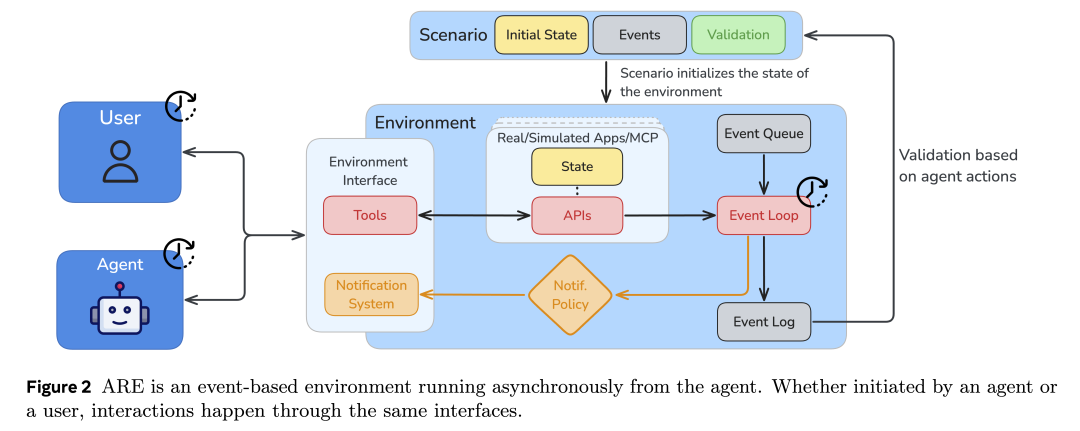
Gaia2 运行在 ARE(Agent Research Environments)执行环境中,在这里,用户可以选择任意智能体,并赋予其对一系列应用程序及预置数据的访问能力。
针对 Gaia2,我们打造了一个 智能手机模拟环境,再现人类日常生活中的使用场景。环境中包含真实世界常见的应用,如消息类(电子邮件)、工具类(日历、联系人、购物、文件系统等),以及一个与智能体对话的聊天界面。所有应用也都可以通过工具调用的方式被智能体访问。更有趣的是,演示环境还附带了一个虚拟用户的历史对话与应用交互记录。
在运行过程中,所有智能体的交互都会被自动记录为 结构化轨迹(structured traces),以便深入分析。这些轨迹包括:工具调用、API 响应、模型思考过程、时间指标(如响应延迟)、用户交互等,并可导出为 JSON 文件。
作为参考,我们对比了多款开源与闭源的大模型,包括:Llama 3.3-70B Instruct、Llama-4-Maverick、GPT-4o、Qwen3-235B-MoE、Grok-4、Kimi K2、Gemini 2.5 Pro、Claude 4 Sonnet,以及 GPT-5 在不同推理模式下的表现。
所有模型均在相同配置下进行评测:采用统一的 ReAct 循环确保一致性,温度设定为 0.5,最大生成上限为 16K tokens。根据具体任务类型,评测方式结合了“模型判别(以 Llama 3.3 Instruct 70B 作为评审)”和“严格匹配(exact-match)”两种方法。同时,系统提示中预置了全部 101 个工具及通用环境描述。
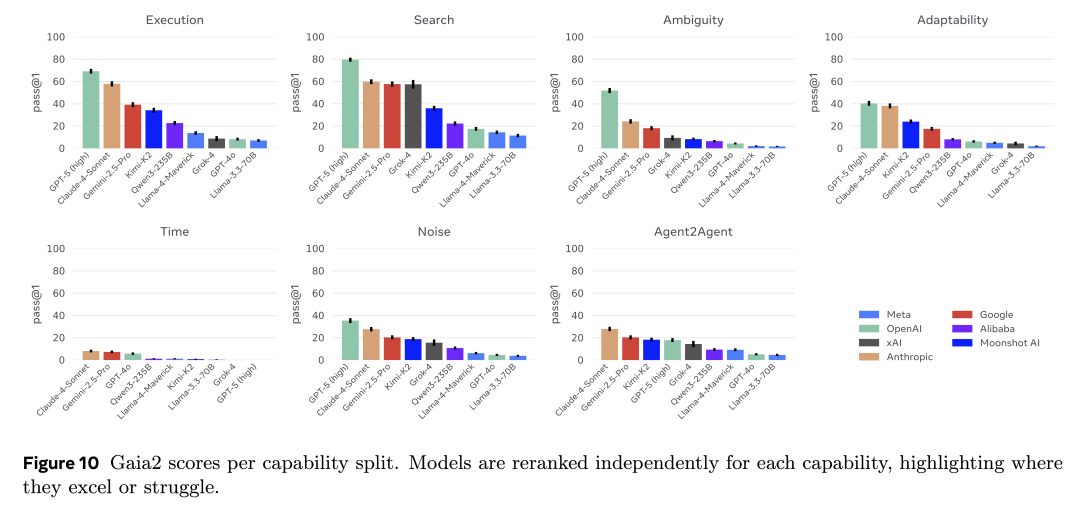
在评测的模型中,截至 2025 年 9 月,整体得分最高的模型是具备强大推理能力的 GPT-5,而表现最好的开源模型则是 Kimi K2。
从能力维度来看,一些任务已经被顶级模型基本解决:例如简单工具调用与指令执行(execution),以及整体的检索能力(search)(这一点从 GAIA 的结果中已经有所预期)。然而,歧义处理(ambiguity)、适应性(adaptability)和抗噪性(noise)依旧是所有模型的普遍挑战。值得注意的是,那些过去被认为复杂的智能体任务(如指令执行与信息检索),并不能很好预测模型在更贴近真实世界任务上的表现。最后,目前所有模型在 time 维度上的表现最为薄弱:在处理时间敏感型操作上仍然非常困难(不过,未来通过专用工具与更好的时间推理机制可能有所改善)。详细分析可见论文正文。
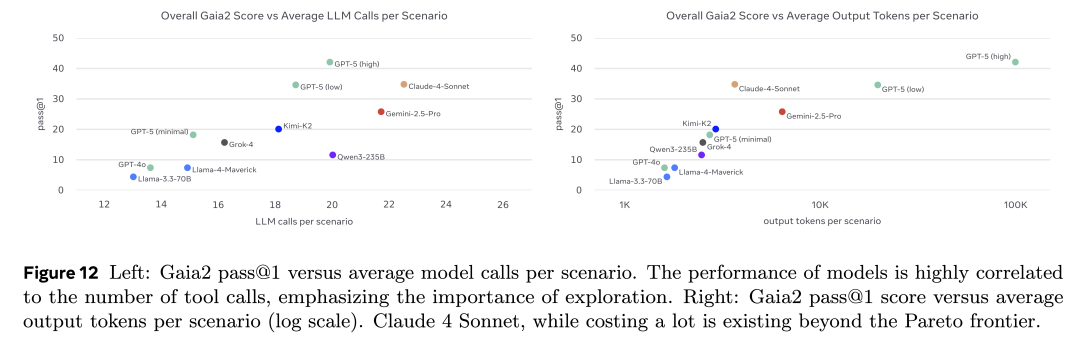
同时,我们认为必须超越单纯的分数汇报:如果一个模型虽然答对了,但需要消耗数千个 token 或运行数小时才能得出结果,那么它的表现显然“不如”另一款在更短时间、更低成本下完成任务的模型。因此,我们对得分进行了成本归一化:通过平均 LLM 调用次数与输出 token 数量来量化,并绘制出性能—成本的帕累托前沿(Pareto frontier)。在论文中,你将看到模型得分与实际金钱成本及耗时的对比结果。
如果你想在 Gaia2 上评测自己的模型,可以按照以下步骤操作:
首先,在你选择的 Python 环境(uv、conda、virtualenv 等)中安装 Meta 的 Agent Research Environment:
pip install meta-agents-research-environments
然后,运行基准测试,覆盖所有配置:执行(execution)、检索(search)、适应性(adaptability)、时间(time)以及歧义(ambiguity)。 别忘了使用 hf_upload 参数将结果上传到 Hugging Face Hub!
运行基准测试的示例命令如下:
are-benchmark run --hf meta-agents-research-environments/Gaia2 --split validation --config CONFIGURATION --model YOUR_MODEL --model_provider YOUR_PROVIDER --agent default --max_concurrent_scenarios 2 --scenario_timeout 300 --output_dir ./monitored_test_results --hf_upload YOUR_HUB_DATASET_TO_SAVE_RESULTS
运行 oracle 来生成汇总得分文件。
are-benchmark judge --hf meta-agents-research-environments/Gaia2 --split validation --config CONFIGURATION --agent default --max_concurrent_scenarios 2 --scenario_timeout 300 --output_dir ./monitored_test_results --hf_upload YOUR_HUB_DATASET_TO_SAVE_RESULTS
最后,请在 README 中补充与你的模型相关的所有信息,并将结果分享到排行榜,以便集中展示 Gaia2 的运行轨迹!
排行榜:
https://huggingface.co/spaces/meta-agents-research-environments/leaderboard
除了基准场景外,你还可以在 ARE 中使用 Gaia2 的应用和内容,测试模型是否能够正确完成一些更难验证的任务,例如加载邮件、撰写跟进回复、在日历中添加事件或预约会议。总之,ARE 提供了一个通过交互来评估 AI 助手的理想环境!你也可以轻松定制环境:
连接你的工具(通过 MCP 或直接接入),在其上测试智能体; 实现自定义场景,包括设置 触发事件或定时事件(例如:2 分钟后,邮件应用收到来自联系人的新邮件),从而观察智能体如何适应动态变化的环境。
(默认情况下,智能体运行在 json agent 模式下,不会对你的本地机器造成影响;除非你将它们连接到具备不安全权限的外部应用。因此,在添加自定义应用或使用不可信的 MCP 时,请务必保持谨慎。)
以下是我们使用 ARE 的一些典型场景:
快速评估任意智能体:基于真实或模拟数据,测试不同规则、工具、内容和验证方式下的表现 测试智能体的 工具调用与编排能力:可结合本地应用或 MCP 工具 生成自定义的工具调用轨迹,用于 微调具备工具调用能力的模型 在统一框架下,轻松收集并 复现现有的智能体基准测试 在用户界面中,实时调试并 研究智能体之间的交互 在嘈杂环境中(如 API 超时、任务歧义),研究模型的局限性
我们录制了 3 段视频,展示了其中的一些使用场景(当然,我们也希望社区能在 ARE 上发挥更多创造力!)。
这些视频基于前文提到的默认演示环境,内容模拟了一位名为 Linda Renne 的机器学习博士生的日常生活。
为了测试默认模型在活动组织上的能力,我们来策划一场生日派对! 🎉
首先,我们让智能体给 Renne 家族的成员群发短信,告知用户的 30 岁生日派对将在 11 月 7 日举行。默认的模拟环境中共有 21 个联系人,其中 5 位属于 Renne 家族 —— 包括模拟“主人”Linda、她的父母 George 和 Stephie、妹妹 Anna,以及祖父 Morgan。智能体成功遍历了联系人列表,找到了这四位家族成员,并向他们发出了通知。
接下来,我们要求智能体创建一个日历邀请,并将他们添加为受邀者。智能体成功记住了之前的上下文:它在正确的日期创建了日历事件,并把家族成员正确添加进来。
ARE 还支持我们查看智能体在执行任务时的完整轨迹。打开左侧的 Agent logs 工具后,可以看到系统提示、思维链(chain of thought)、通过工具执行的多步操作,以及最终结果——所有内容都被清晰地组织成日志形式。如果需要离线分析,还可以将所有信息导出为 JSON 文件。
在最后一个示例中,我们通过 MCP 将 ARE 连接到一只远程机械臂,让它可以做出手势。随后,我们要求智能体通过挥动机械臂来回答我们的是/否问题!以下是演示效果:
但以上这些示例只是非常简单的起点,我们真正期待的是——看看你们能用它们创造出什么!(对于更高阶的用户,你甚至可以直接安装并编辑 Meta-ARE 的代码,详见https://github.com/facebookresearch/meta-agents-research-environments)
Gaia2 与 ARE 是全新的研究工具,我们希望它们能够帮助更多人轻松构建更可靠、更具适应性的 AI 智能体。通过简化实验过程,让真实世界的评测对所有人都更易获得,并通过透明、可复现的基准与可调试的轨迹来增强信任。
我们非常期待看到大家能用这个项目做出什么!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢