

新智元报道
新智元报道
【新智元导读】Veo 3真正对手,竟不是Sora 2!通义万相2.5全网首发,直接甩出王炸:一句话,直出10秒1080P电影级视频,首次实现音画精准同步。一键生成BGM、人声,全网实测玩疯。
四个月前,谷歌DeepMind重磅推出Veo 3,首次实现「音画同步」,让AI视频彻底告别无声时代!
一段提示,可以直吐4K高清视频,还自带逼真音效,唇同步准到毫秒级别。


在云栖大会上,通义万相2.5(Wan2.5-preview)系列模型正式亮相,全模态生成一网打尽。
它包含了四大模型——文生视频、图生视频、文生图、图像编辑。

尤为瞩目的是,通义万相2.5视频生成模型,也首次取得了音画同步的突破。
无论是人声,还是音效、BGM,皆可与画面精准对齐。
单一模型基本覆盖了全模态的生成,这在AI视觉生成领域,都是领先一步的存在。
它的到来,再次大幅降低了电影级视频创作的门槛,让每个人都能成为「导演」。
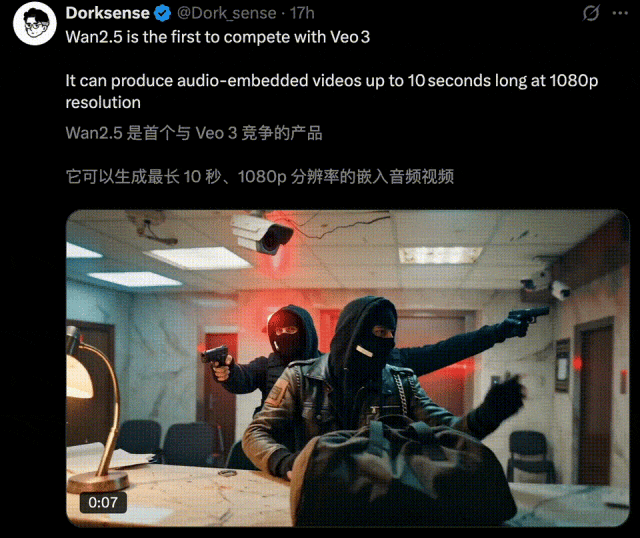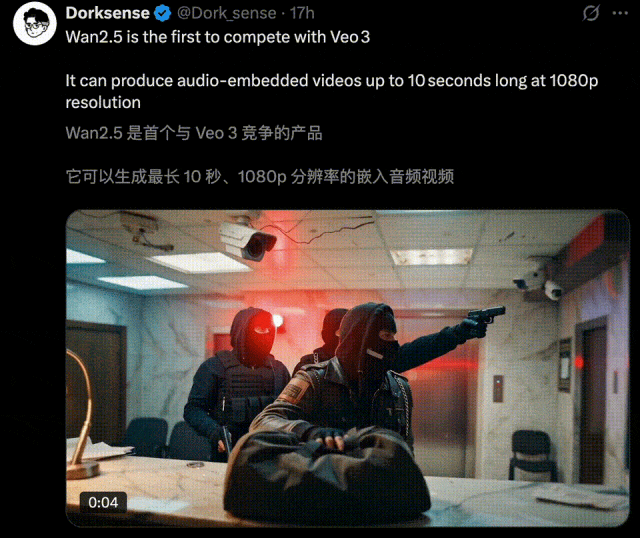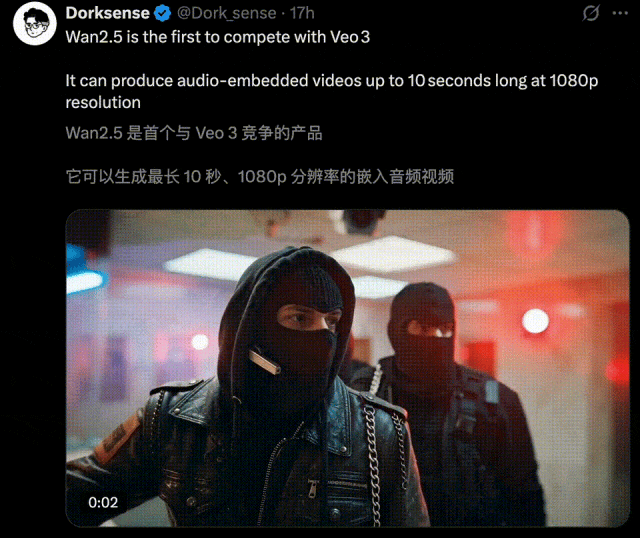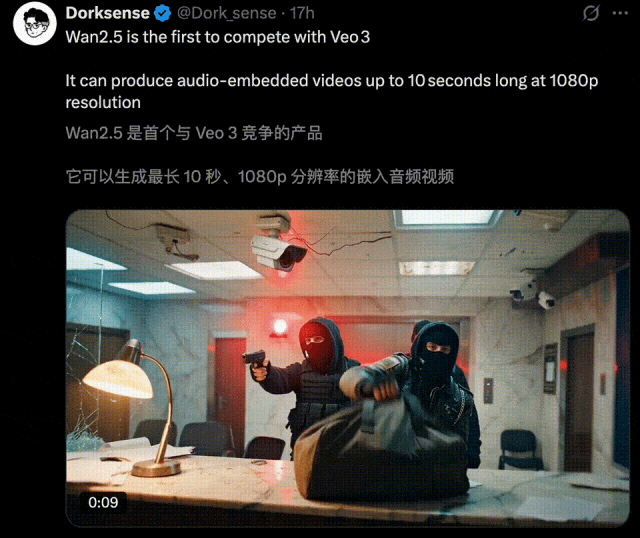
万相2.5一亮相,就被不少玩家称为「Veo 3的真正对手」。
10秒1080P超清视频,在画面质感,还有音画同步上,效果直接对标国际顶尖水平,实力不容小觑。
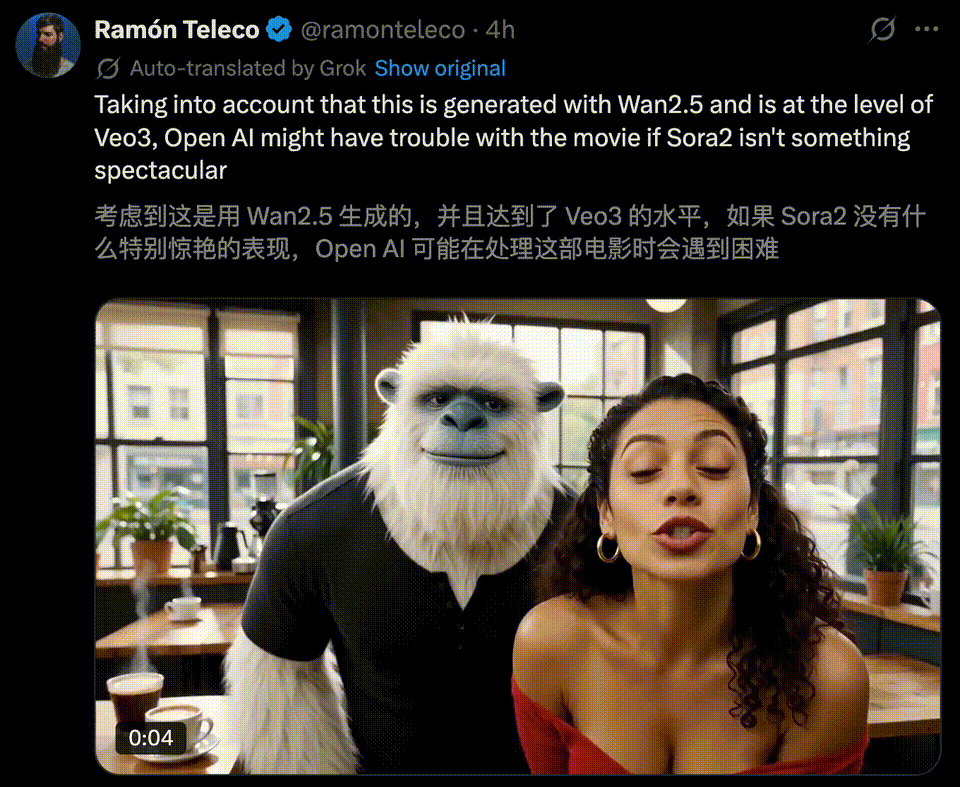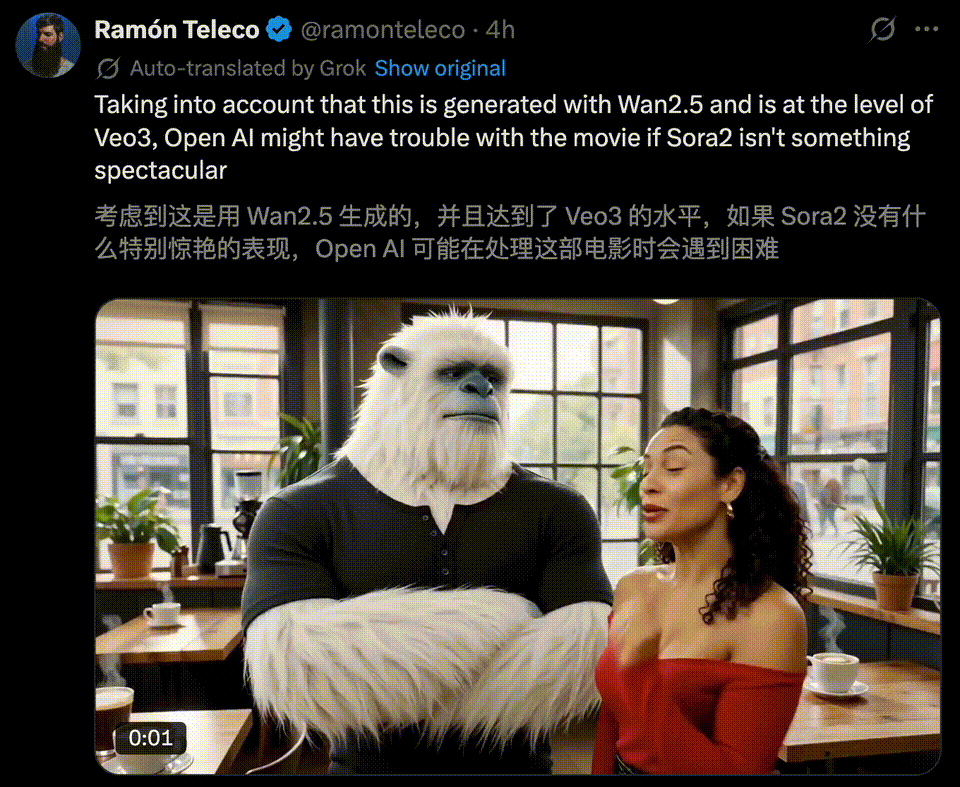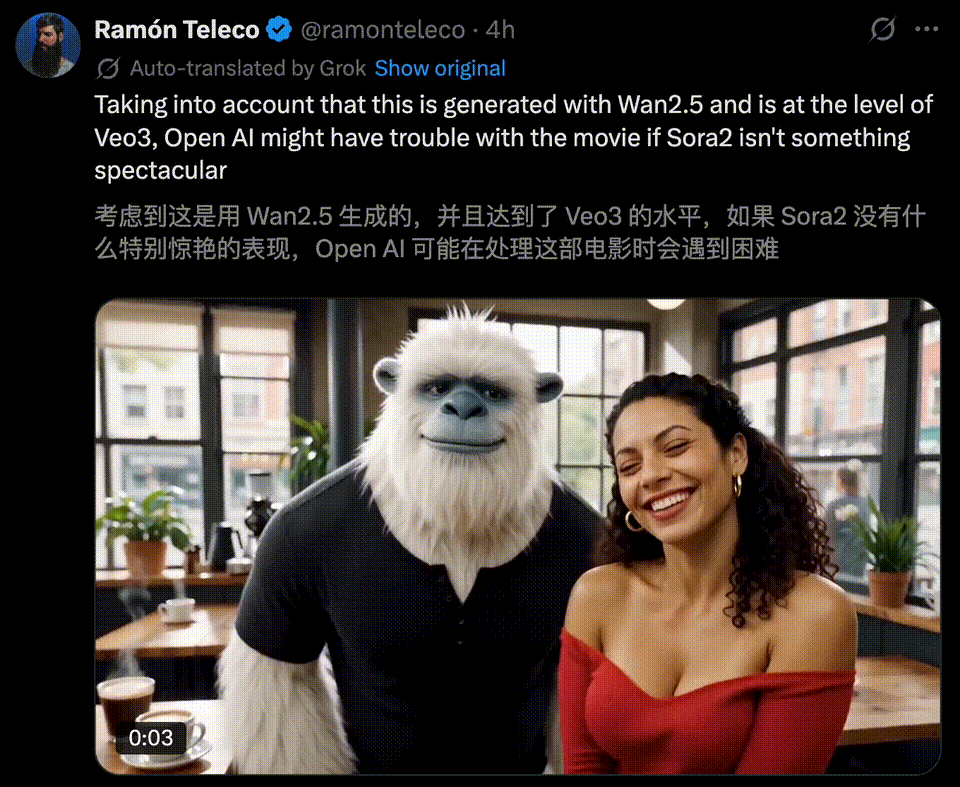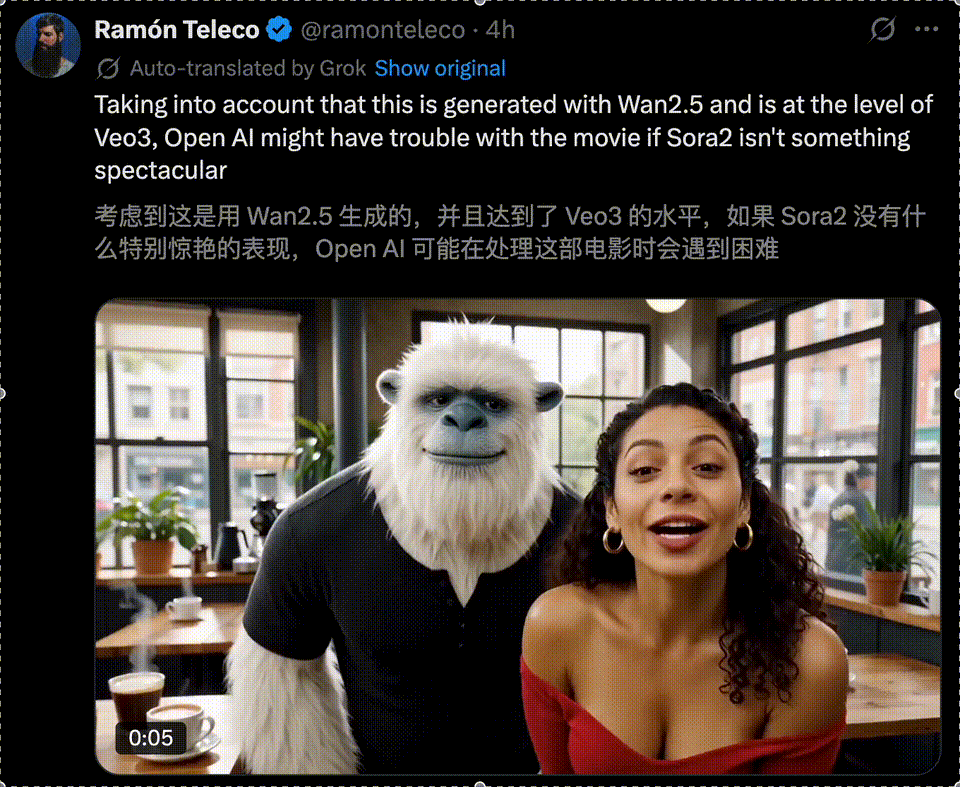
一时间,全网创意再度被万相2.5点燃,各种令人拍案叫绝的AI视频正持续刷屏。


左右滑动查看

这一次,在创作能力上,通义万相2.5实现了全方位的升级突破。
视频生成时长由5秒大幅提升至10秒,单次生成即可呈现结构完整、情节连贯的故事内容。
如前所述,它还支持24帧/秒 1080P高清视频,画面质感更加细腻流畅,完全达到了电影级视觉效果。
在指令理解与执行方面,万相2.5的能力也得到显著增强——
视频生成中,可精准理解运镜等,复杂连续变化的指令
图像生成中,支持通过指令一键实现人物换装、风格转化效果等。
输入一段提示,即可生成人声、环境音效和背景音乐,并且精准与画面内容、人物口型匹配,让视频演绎更加生动形象。
现在,所有人进入通义万相官网即可体验,开发者可通过阿里云百炼平台调用API。
传送门:https://wan.video/
一起来看看,万相2.5在实测中的真实表现。

首先,是最考验单一模型多模态融合能力的「试炼场」——文生音视频。
在这里,万相2.5需要从零开始,凭空构建一个声画俱佳的世界。
先上第一道考题——「魔性」切水果,此前Veo 3直出ASMR视频风靡全网,收割了一大波流量。
一刀切下去,Q弹果冻质感、玻璃质感水果伴随着逼真的特效声音,观感那叫一个爽到起飞。
这一次,我们不在砧板上切玻璃水果,而是蓬松的云朵状物体,还要发出「嘶」声和干冰升华的气流声。
不得不说,万相2.5自动配音超丝滑。
Prompt:一把黑色刀具从右向左推进,切入一团白色蓬松的云朵状物体,置于浅木色砧板上。刀具接触时云朵形变,表面裂开,部分结构被切离并移位。云朵边缘持续释放轻烟向上飘散。刀具完成切割后停止,云朵被分为两部分,一侧塌陷。过程伴随轻微“嘶”声和干冰升华的气流声。
再来一个让人一听,就颅内高潮的打字ASMR。
Prompt:asmr creator typing on a noisy keyboard and then looking up and blowing into the microphone as she talks
不仅如此,万相2.5还可以一句话生成一段「谐音梗」脱口秀:
为什么骷髅不打架?因为他们没有勇气(guts也指内脏)。
Prompt:a man doing stand up comedy in a small venue tells a joke (include the joke in the dialogue)
更厉害的是,对于那些包含动作、视觉、光影等复杂提示的指令,万相2.5可以做到精准解析和遵循。
比如在下面这段滑滑板的视频中,不管是整个画面的构图,还是指令中的元素,全都被一一呈现了出来。
人声、滑板音效与背景音乐,更是高度同步,动感十足。
再来看一组,万相2.5生成的1080P电影级质感的画面,每一帧都仿佛置身于专业片场。
一位风尘仆仆粗犷牛仔,从腰侧枪套中拿出一把枪,指节紧绷,目光横扫西部鬼城的荒凉街道,呢喃着,「这地界活人可待不住」。

再看如下这个demo中,海盗在暮色时分,伫立在船桅瞭望台,海水猛烈拍打,船身摇晃发出吱嘎声响,堪比电影版《加勒比海盗》。

万相2.5更多文生视频惊艳Demo合集:







左右滑动查看

除了从无到有,万相2.5还拥有一项「点石成金」的能力:图生视频。
它能一键让静态图片「活」过来,并智能地配上最契合的音效。
比如,上传一张倒牛奶的图。
它可以精准模拟物理细节,比如倾倒牛奶时,音效会随液体渐满而由强变弱,细腻地还原真实听感。
Prompt:俯拍视角下,温牛奶从画面上方持续注入白色陶瓷杯中,液流稳定,撞击杯内液面引发涟漪向外扩散,液面随之缓慢上升。杯口处的蒸汽持续向上飘散。镜头跟随液面逐渐上升,记录液体填充全过程。伴随牛奶注入,可听见清晰的潺潺流动声及杯口蒸汽的细微“嘶嘶”声。后期添加微弱的液体流动视觉波纹。
上传一张快乐水图片,万相2.5同样可以将其变为一段动态短片。
它能瞬间激活听觉,精准还原了那活灵活现、滋滋作响的气泡音效。
Prompt:两杯透明玻璃杯中的气泡饮品放置在木质桌面上,杯中液体清澈,内含大量细小气泡,杯中可见橙色柠檬片、绿色薄荷叶和冰块。气泡从液体底部持续向上移动,在杯壁聚集后破裂,发出“滋滋”“噼啪”声。柠檬片在液体中因气泡推动而轻微晃动,薄荷叶与冰块随之缓慢漂移。整个过程持续进行,气泡不断生成、上升、破裂,形成稳定而连贯的动态效果,伴随持续的气泡声。
冰雪消融,化作涓涓细流,背景里那空旷治愈的自然之声,竟然是万相2.5仅仅「看图」,便能生成出强代入感的意境。

Prompt:固定镜头记录冰雪融化的场景。冰层边缘持续融化,水珠从冰块顶部断续滴落,落入下方水流中,激起微小水花。水流在冰层间缓慢流动,水面泛起轻微涟漪。冰层内部出现细微裂痕,伴随脆响。滴水声与冰裂声交替出现,背景为寂静清冷的清晨环境音,包括远处微弱的风声与自然空旷感的回响。
值得一提的是,万相2.5还支持多种模态的组合输入,比如「图片+音频」和「文字+音频」,让创作者秒变大片「导演」。
比起一段文字、一张图片直出视频,从内容创作的优势来看,多种模态输入可以更好控制最终的生成效果。
上传一张红毛猩猩图片,再搭配一段中文语音,看看万相2.5能不能来一个跨物种的「灵魂配音」。
全网都在更通义万相最新模型,你这个年龄段的创作者,你怎么睡得着的?
这段音频,配上大猩猩那一脸认真而又严肃的表情,效果实在太有趣了!
Prompt:红毛猩猩坐姿,双臂交叉抱胸,头部轻微左右转动,眼神随之偏移,嘴唇开合,说出中文台词:“全网都在更通义万相最新模型,你这个年龄段的创作者,你怎么睡得着的?” 雨水持续落下,打在毛发和地面上。头部和嘴部动作配合语音节奏。
再比如,我们还可以让一个歪果仁小哥,亲自为万相AI打Call。
经过万相2.5加工之后,小哥的口型和面部表情都实现了精准匹配,表现力十足,堪称是一波生动有趣且毫无违和感的精彩宣传。
Prompt:一位卷发外国男性站在中国复古街头,身穿格子衬衫和破洞牛仔裤,面向镜头。他开始说话,嘴唇开合,面部表情随之变化,依次说出:“大家好,我是小王。AI我用过很多,但视频生成我只用通义万相。是兄弟就一起来生视频。”背景中一名骑自行车的人从画面左侧快速驶入,向右侧移动并消失在画面外。镜头固定,聚焦人物主体。
再上传一张WAN模特AI海报,以及一份音频,万相2.5可以很好地遵循指令。
包括人物左右摆动身体、背景霓虹灯光线、「WAN AIGC」闪烁等效果, 每一个细节都被精准呈现。
Prompt:一位女性模特头部轻微左右摆动,身体随节奏轻微晃动,嘴唇开合演唱,视线在镜头间移动,头发轻微飘动。背景中紫色霓虹光线以波浪形态从左至右持续流动,文字“WAN AIGC”周期性闪烁。模特持续演唱,面部表情随歌词变化。
接下来,我们将文字、音频输入,看看万相2.5实际表现。
上传一张涂鸦图和一段rap音频,没想到,模型不仅让涂鸦小人「活」了起来,而且口型也与Rap节奏完全同步,视觉冲击力极强。


如上经过一波全方位实测后,不难看出,通义万相2.5的效果彻底鲨疯。
为什么这一次迭代后,能够如此厉害?
这是因为,通义万相2.5在技术架构上实现了重大更新:首次采用原生多模态架构!

过去,生成一个带声音的视频,可能需要一个文本理解模型、一个视频生成模型、一个音频生成模型,再将它们强行拼凑在一起,效果自然生硬。
而「原生多模态」意味着,通义万相2.5是在一个统一的框架下,同时学习和理解文本、图像、视频、音频等多种模态的数据。
一体化处理:在同一套框架下,模型可以无缝处理多种任务,无论是理解还是生成,文本、图像、视频、音频都可以自由地作为输入和输出。
深度模态对齐:通过联合训练,模型对文本、音频、视觉数据建立了更深层次的关联。这正是实现音画精准同步、指令遵循能力大幅提升的关键。
人类偏好对齐(RLHF):在技术底层之上,团队还通过持续的人类反馈强化学习,不断优化模型的审美,最终提升了图像质量和视频的动态美感。
如今,通义万相「家族」已支持文生图、生视频、图生视频、人声生视频、动作生成等10多种视觉创作能力。
截至目前,其累计已生成3.9亿张图片、7000万个视频。

自2月以来,通义万相连续开源了20多款模型,下载量超3000万,稳坐开源社区「最受欢迎视频生成模型」的宝座。
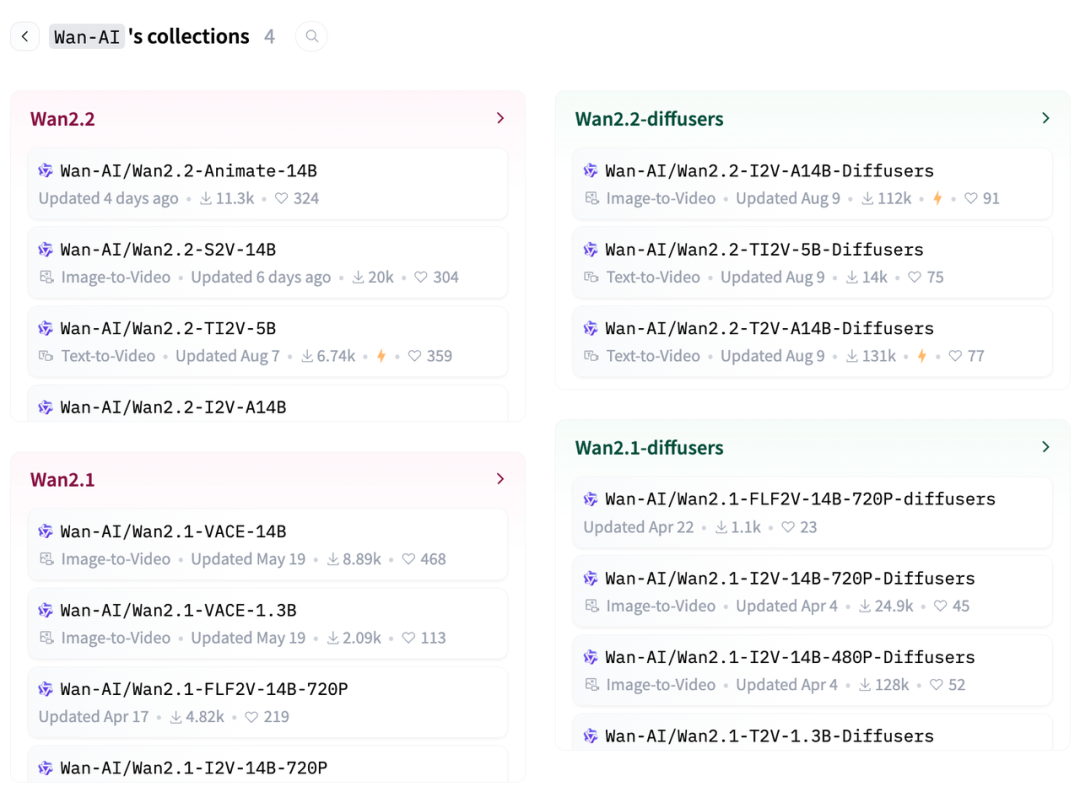
回顾今年,通义万相模型多箭齐发,每一款模型都针对不同场景优化,让AI能力无限延伸。
在图像生成领域,有文生图、图像编辑两大类模型,比如Wan2.0-T2I、Wan2.1-T2I、Wan2.2-T2I,以及Wan2.1-ImageEdit。
在视频生成方向,又划分了五大类多样的生成能力,其中包括:首尾帧生视频、图生视频、文生视频、视频编辑。
Wan2.1-FLF2V
Wan2.1-I2V、Wan2.2-I2V
Wan2.1-T2V、Wan2.2-T2V
Wan2.1-VACE
再加上这一次的「多模态视频生成」Wan2.5-T2V-Preview、Wan2.5-I2V-Preview,一共凑齐了五大类。
在数字人领域,有「人声生视频」的Wan2.2-S2V模型,还有前段时间爆火全网的「动作生成」Wan2.2-Animate。
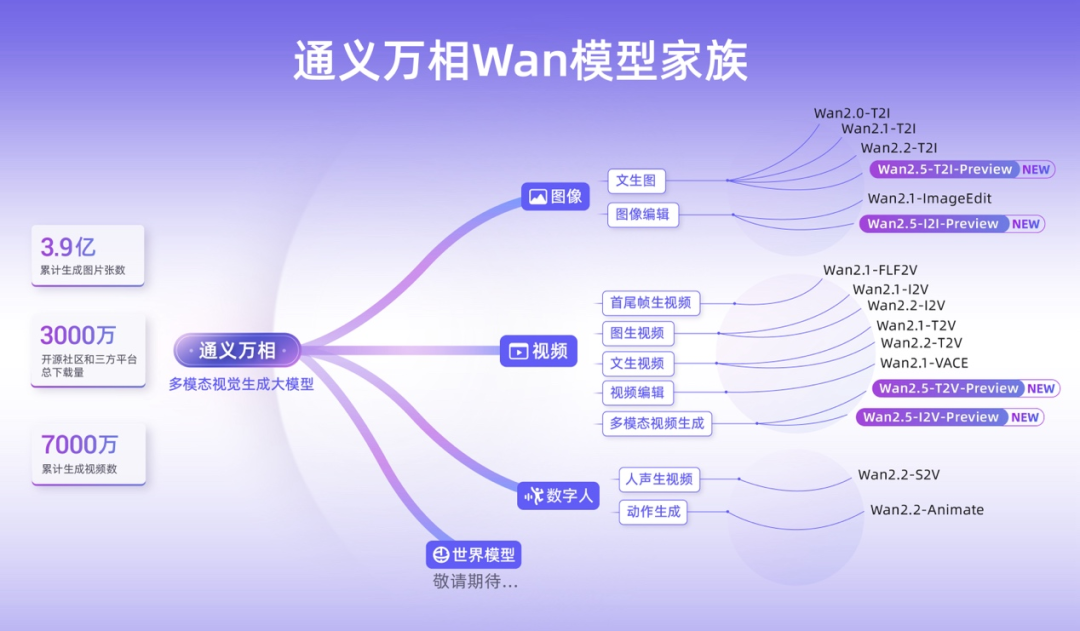
通义万相模型「家族」中,所有模型连接起文字、图像、音频、视频多模态世界的转化,最终无缝融合就能创造出「世界模型」。
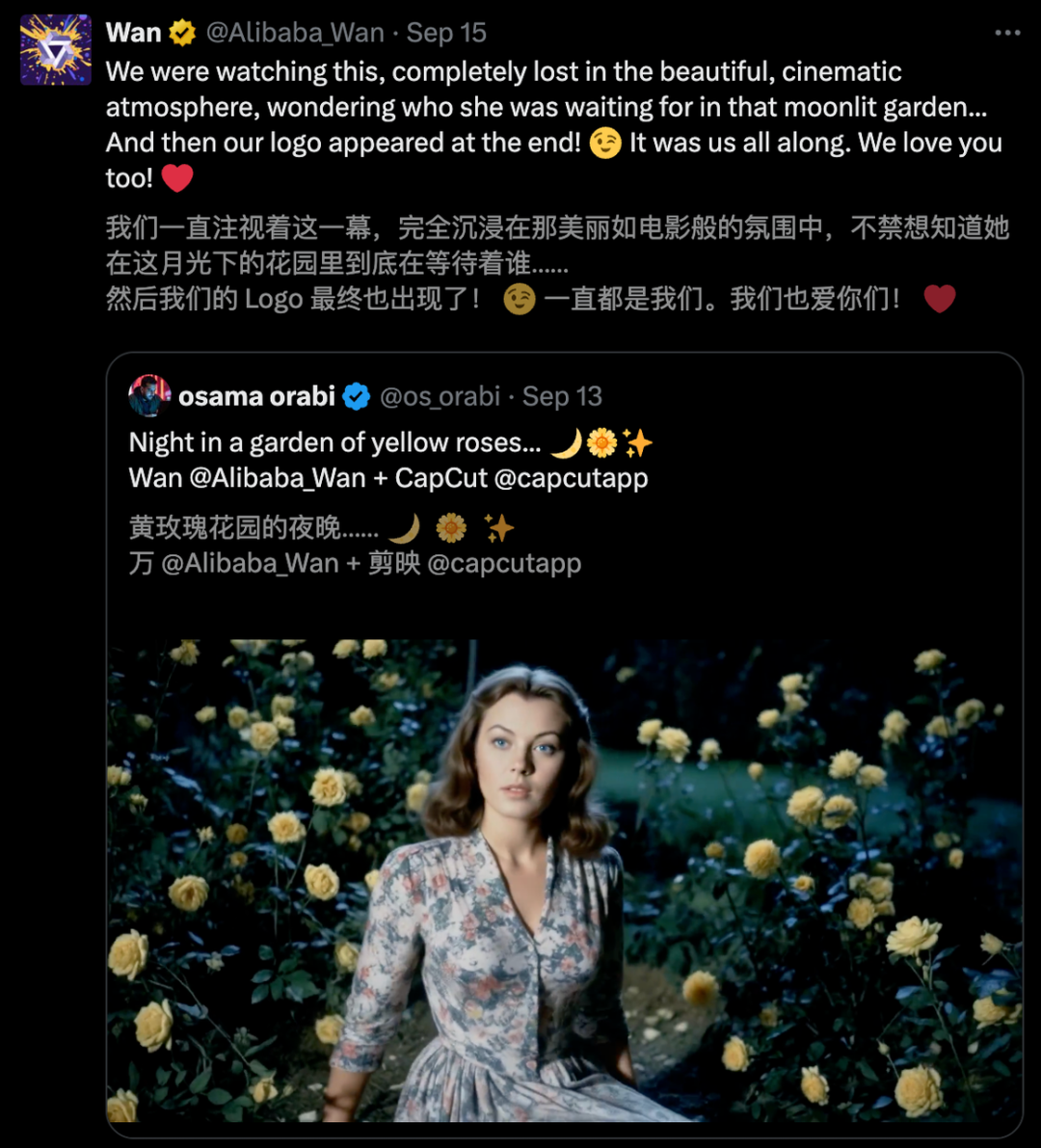
在全网,通义万相「家族」收获了诸多好评,许多人晒出了自己的创作成果。

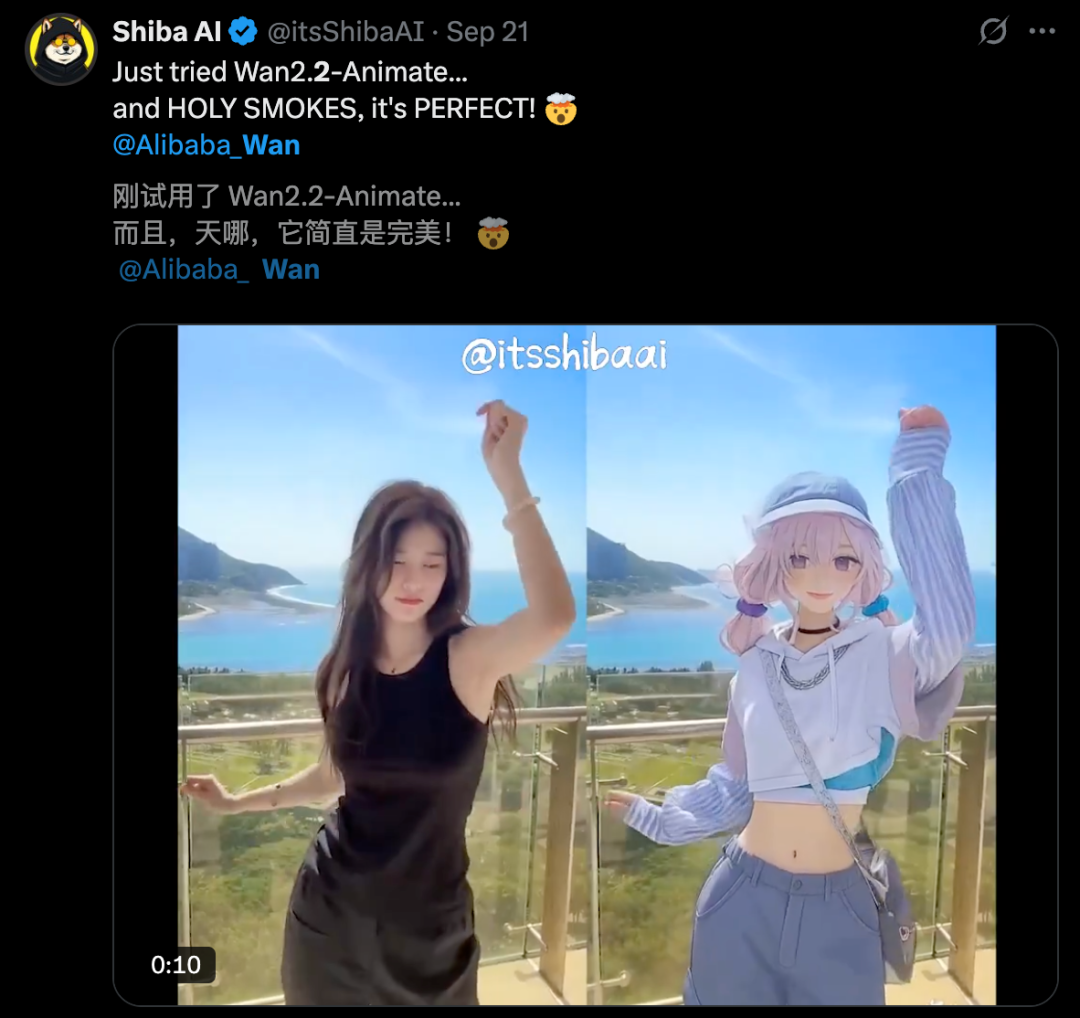
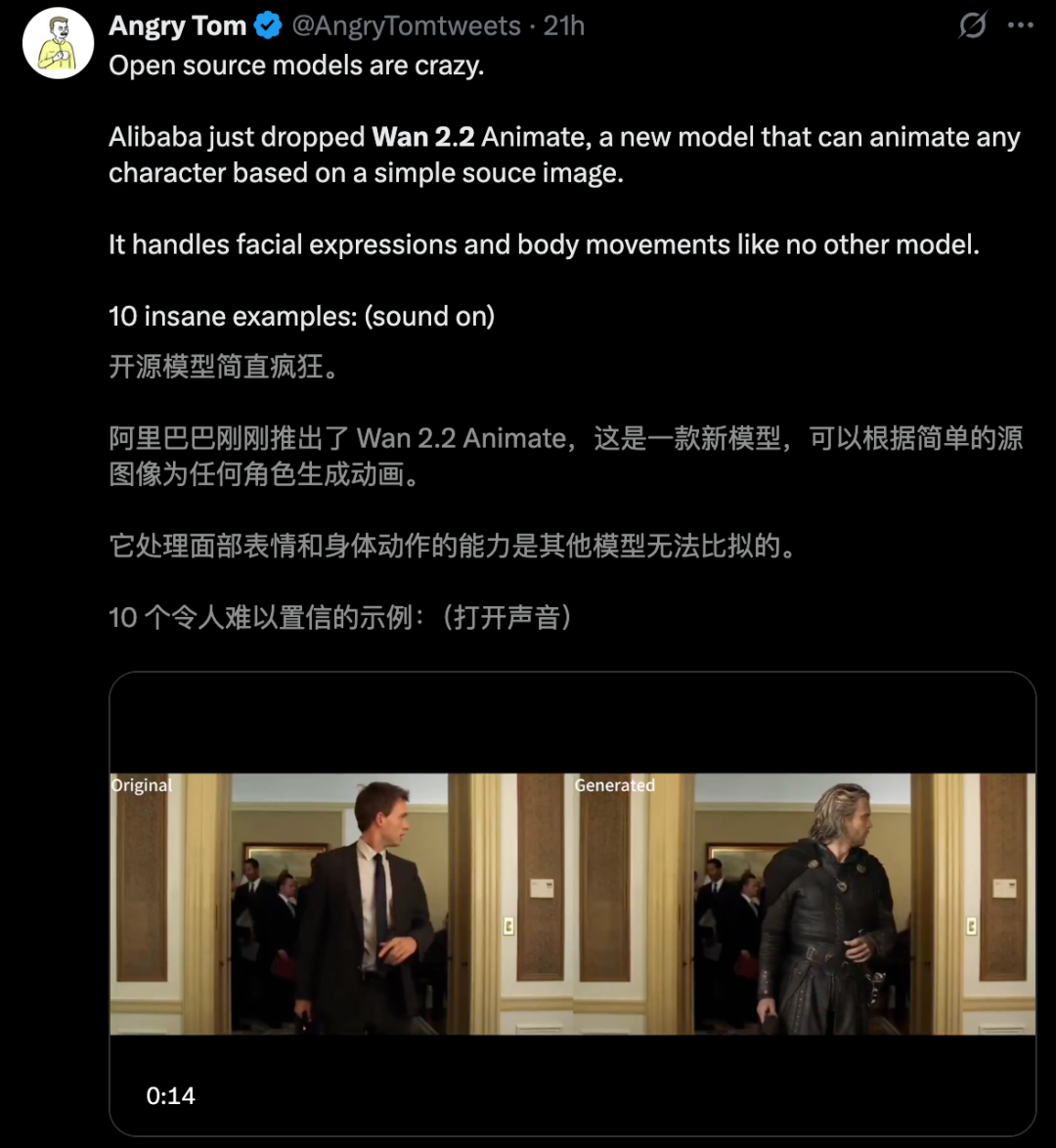
左右滑动查看
如今,首个原生多模态通义万相2.5出世,再次刷新了世界模型纪录,成为国内最能打的模型。
或许,我们离AI生成整部电影、互动故事的那一天,不远了。
而这一切的起点,可能就藏在你脑海中,那句尚未说出口的、充满奇思妙想的Prompt里。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢