

图神经网络 (GNN) 已为推荐系统、分子动力学模拟、高能物理等众多领域的众多问题奠定了坚实的基础,并取得了诸多前沿成果。然而,这些学科的图数据集通常规模庞大。例如,用于高能物理问题的 GNN 包含数万亿条边。因此,必须开发在大型超级计算机上训练大规模 GNN 模型的方法。
然而,在超级计算机上扩展 GNN 并非易事。GNN 目前在“硬件彩票”中落败。这意味着它们的底层内核无法高效利用基于 GPU 的超级计算机的资源,这与 Transformers 等实现高集群利用率的模型不同。本论文概述了加速分布式 GNN 训练的方法,使 GNN 能够应用于追求“赢得”硬件彩票的下游应用。
这项工作的主要思想是用稀疏矩阵乘法来表达GNN训练,并使用避免通信的分布式稀疏矩阵算法来扩展训练。首先,我们概述了分布式稀疏-密集矩阵乘法如何有效地扩展全批量GNN训练。我们将通过引入高效的稀疏感知和负载平衡技术来进一步深入探讨这一主题。其次,我们展示了如何使用稀疏-稀疏矩阵乘法来加速小批量GNN训练,以执行批量采样。最后,我们展示了这些方法如何扩展用于解决粒子径迹重建(高能物理中的一个重要问题)的GNN。

论文题目:Scaling Graph Neural Networks for Sciences
作者:Alok Tripathy
类型:2025年博士论文
学校:University of California, Berkeley(美国加州大学伯克利分校)
下载链接:
链接: https://pan.baidu.com/s/1R-C24Cl23A6sRIhQQKJyIQ?pwd=w5hb
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
引言
在过去十年中,深度学习的普及度呈爆炸式增长。继 AlexNet 在 2012 年 ImageNet 大赛中取得骄人成绩之后,深度神经网络 (DNN),例如卷积神经网络 (CNN)、循环神经网络 (RNN) 和长短期记忆网络 (LSTM),成为图像、视频和文本问题解决的主流[69, 73, 74, 48, 72]。如今,Transformer 已在大型语言模型 (LLM) 和视觉语言模型 (VLM) [82] 中取得了革命性的成果。然而,尽管 DNN 直到 2010 年代才成为主流,但这些算法在文献中已经存在了几十年。长期以来,DNN 一直无法在 CPU 架构上运行。它们最近兴起的一个关键原因是,出现了一些新技术,可以在 GPU 上高效地实现 DNN[91]。换句话说,DNN 模型赢得了“硬件彩票”,这意味着最成功的机器学习模型是能够充分利用现代硬件的模型 [49]。LLM 也受益于硬件彩票的胜利。经验标度定律表明,在训练 LLM 时添加 GPU 不仅可以提高计算性能,而且可以预见地提升 LLM 的表达能力 [60]。然而,DNN 和 LLM 的成功引出了一个问题:如果能够有效利用硬件资源,是否存在强大的机器学习模型?
图学习,尤其是图神经网络 (GNN),提供了一种泛化许多传统深度神经网络 (DNN) 的方法 [88]。GNN 以非结构化图数据作为输入,而不是结构化图像、视频或文本数据。CNN 和 Transformer 都可以视为 GNN 的特例。CNN 本质上是图像数据上的 GNN,其中每个像素都是与其八个相邻像素相连的顶点。Transformer 相当于完全图上的图注意力网络,其中每个顶点都是与其他每个顶点相连的标记。这种泛化能力非常强大,因为图数据结构可以表示各种各样的现实世界现象。图可以建模任何东西,从小型分子图到大型推荐系统和社交网络图 [37]。此外,解决这些图结构上的问题也非常有用。图算法,例如最短路径、中心性度量和聚类,广泛应用于科学和工业领域 [13, 87, 24, 61]。例如,社会学家使用中心性度量来确定社交网络中最具影响力的成员 [19]。在图上使用 GNN 的能力使用户能够回答更丰富的图相关问题,包括节点分类、链接预测和图分类。这些科学和工业应用中使用的图通常也非常大,包含多达数十亿个节点和数千亿条边 [112, 109, 18, 111]。在科学应用中,科学家接收的数据量每年都在增长,涵盖了基因组学、材料科学和粒子物理学等各个学科 [115, 14, 56]。在工业领域,图通常以用户为顶点,以交易为边,从而产生包含数千亿条边的图。如此大的图以及基于这些图的 GNN 模型,需要大规模超级计算机来运行训练。
然而,在现代硬件上高效运行 GNN 比运行 DNN 困难得多。传统的 DNN 是计算密集型应用程序。DNN 的主要底层内核是密集矩阵乘法 (GEMM),它花费更多时间计算数据,而不是在硬件资源之间传递数据。此外,GEMM 往往表现出高度的并行性和空间局部性。这使得在现代 GPU 上很容易实现充分利用(“光速”)。另一方面,GNN 是通信密集型应用程序,它们花费更多时间传递数据,而不是计算数据。GNN 还存在内存访问不规则和并行性受限的问题。因此,虽然存在一些可以分布式处理传统 DNN 的方法(例如批处理并行、模型并行和流水线并行),但必须开发新的方法来扩展 GNN 训练,并使大规模 GNN 切实可行 [41]。
在本文中,我提出了一些高效扩展 GNN 训练的新技术。其核心思想是利用输入图的稀疏邻接矩阵表示,并用稀疏矩阵运算来表示 GNN 训练流程的每个阶段。这种方法的优势在于,我们可以使用分布式通信避免 (CA) 稀疏矩阵乘法算法 [39,67, 6] 来分布式 GNN 训练。CA 算法具有可证明的通信边界,该边界会随着 GPU 数量的增加而扩展。仅使用这些算法来表示 GNN 训练,可以实现可证明的训练扩展。这种方法的灵感来自 GraphBLAS 和 CombBLAS 项目,这两个项目开发了一个 API,用于用稀疏矩阵乘法来表示图算法,并利用分布式稀疏矩阵乘法来分布式处理图算法 [64, 23]。这些基于稀疏矩阵的GNN技术被封装到一个名为CAGNET的系统中,这是一个比最先进的学术和工业系统[94, 92, 79]收敛速度更快的GNN训练系统。第三章讨论了相关的GNN训练系统以及该领域的发展历程。第四章讨论了CA算法如何通过重要的优化来扩展全批量GNN训练。第五章讨论了CAGNET如何用矩阵运算来表达小批量训练,以及CA算法如何扩展小批量训练。
随着机器学习的发展,各领域科学家纷纷应用深度学习在各自领域探索新科学,并取得了巨大成功。AlphaFold 对于长期存在的蛋白质结构预测问题 [57] 具有革命性意义。气候科学家已开始使用 CNN 预测未来的湍流 [70]。遗传学家利用深度学习来理解基因组与表型之间的关系 [115, 106]。颠覆硬件的“彩票”模式将为科学家提供新的机器学习工具。小规模的 GNN 已经开始发挥作用,尤其是在材料科学领域 [78]。在气候科学领域,GNN 也带来了更高效的天气预报方法 [71]。在本文中,我将展示 CAGNET 如何有效地扩展 GNN 以用于高能物理中的粒子径迹重建,从而使物理学家能够从之前因过大而无法训练的图形中发现粒子径迹。第七章讨论了 CAGNET 如何加速 GNN 流程以进行粒子径迹重建。
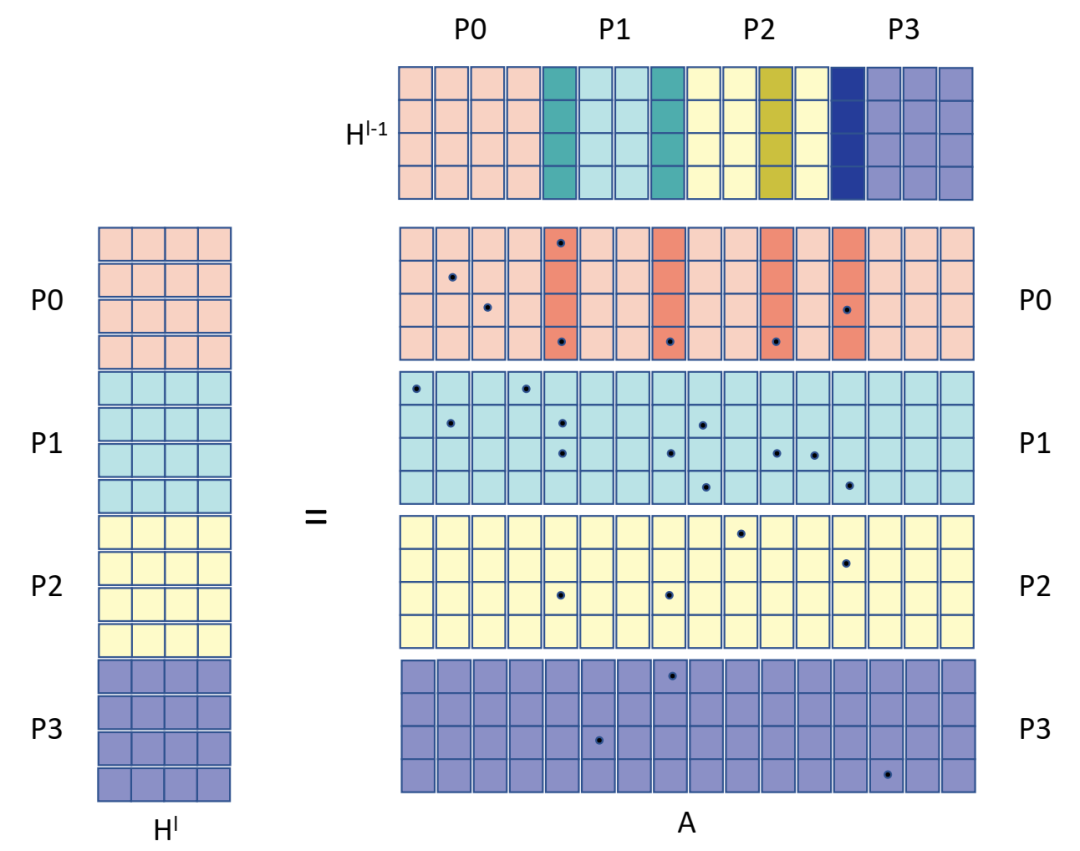
稀疏感知一维算法中 AT 和 H 的划分,包含 4 个进程。AT 和 Hl−1 第一块行中粗体阴影列表示非空列这些列要求 H 的相应行需要由 P0 接收。
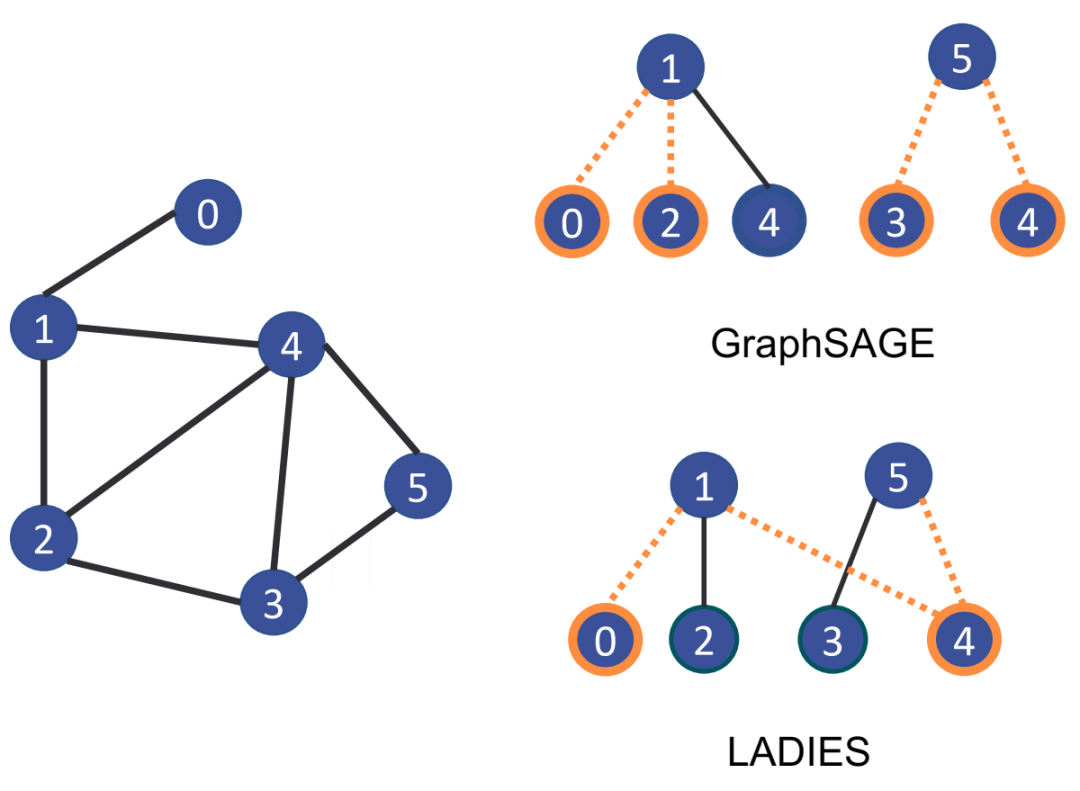
GraphSAGE 和 LADIES 在顶点为 {1, 5} 且样本数为 s = 2 的批次上进行采样的示例输出。加粗的顶点表示样本中包含的顶点,虚线边表示样本中包含的边。
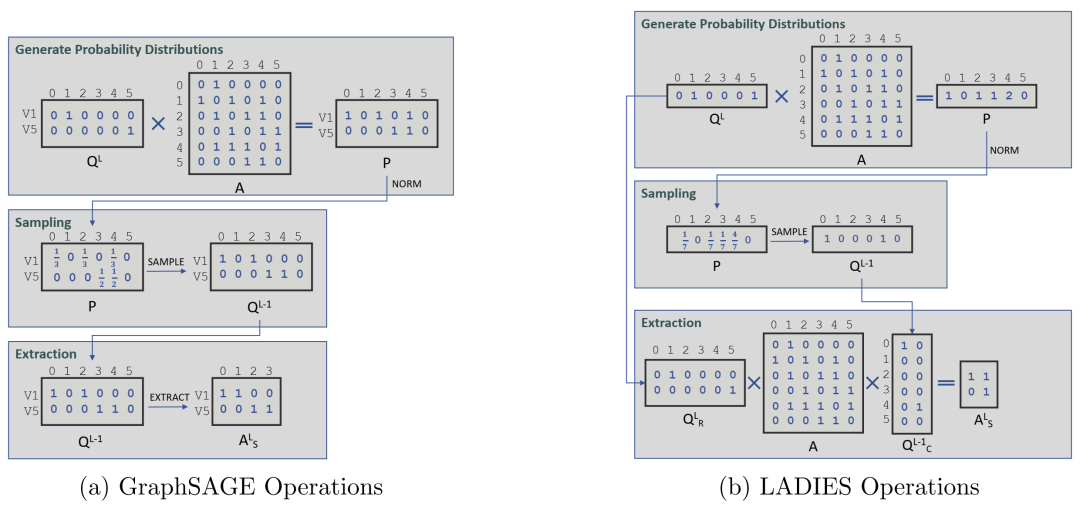
用于对图 5.1 中的示例图以及小批量 {1, 5} 形成的 GNN 第一层进行采样的矩阵运算图。
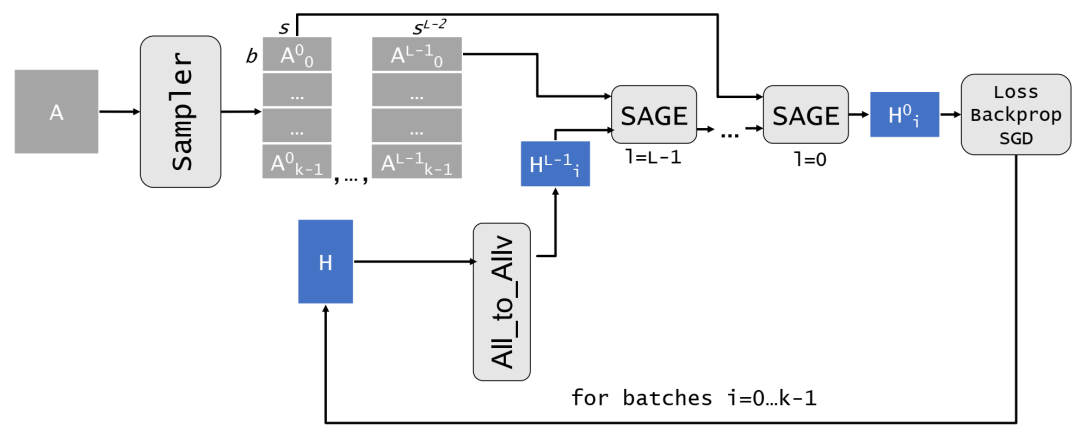
从单个流程的角度来看,我们的分布式流水线的整体架构。图中,A 是整个邻接矩阵或一个分区,具体取决于算法;H 是输入特征矩阵的一个分区。流水线的第一步是一次性对 k 个小批量进行采样。然后,对于每个小批量,我们迭代调用 all-to-allv 函数获取相应的特征向量,并在小批量上运行传播。

Exa.TrkX GNN pipeline
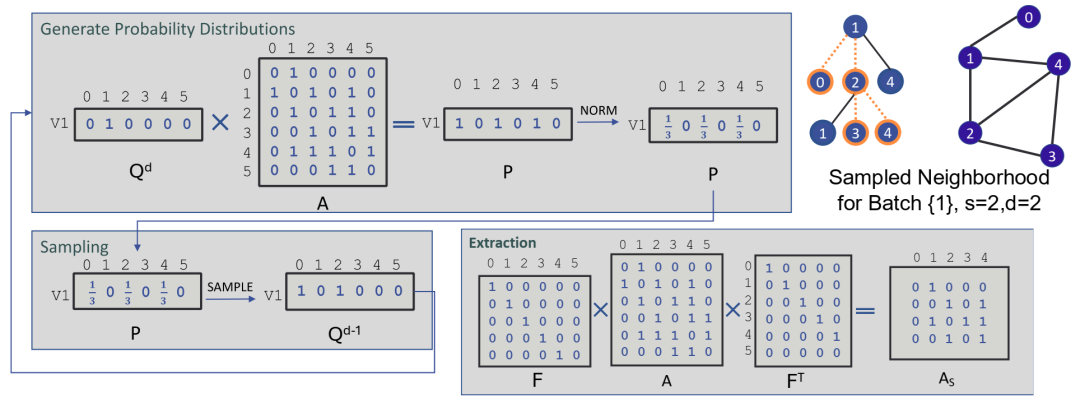
基于矩阵的阴影采样算法,用于示例图和批次。当对多个小批次进行采样时,我们会堆叠每个批次的 Qd 矩阵,并将输出堆叠矩阵输入到批量采样例程中。





内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢