

作者:傅聪Cong
浙江大学计算机博士、美国南加州大学访问学者傅聪老师及其团队,联合中国人民大学等研究机构,共同发表了题为「OnePiece: Bringing Context Engineering andReasoning to Industrial Cascade Ranking System」的论文,介绍 OnePiece 框架,该框架首次将类似 LLM 的上下文工程和隐式推理,注入到以 item ID 为语言的搜推模型中,并取得显著线上收益推全。
论文链接:
https://hyper.ai/cn/papers/2509.18091
以下为傅聪老师对该成果的详细解读分享:
2024 年初,Meta 提出 HSTU 后,整个搜推广工业界掀起了一股「生成式推荐」落地热潮,之后陆续出现的一篇篇工业系统落地的文章,都无一例外地牵动了每个搜推广人的神经。为什么推荐系统会掀起「生成式热」呢?这是因为 Meta 的论文不仅仅提出了一种新的带注意力机制的序列推荐模型结构,还在工业级数据上验证了 scaling law 的存在。这难免让每个搜推从业者都热血沸腾,因为如果推荐模型也存在类似 LLM 的 scaling law,那么搜推系统就可以借鉴所有 LLM 的成功经验,在搜推广语境下迎来属于自己的「超级智能」。
想象力是拉满了的,而落地过程却是异常艰难的。自 HSTU 开始,我们也在 follow 行业内各式各样的解决方案:沿着 HSTU,我们看到了美团 HSTU GR 和小红书 HSTU 落地的技术报告;在用户建模上,我们看到了阿里 LUM 的系列工作;语义 ID 建模路线上,我们看到从 Google 的 Tiger 到快手的 One 系列;其它类型的探索上,我们也调研了字节的 HLLM、Longer、Rank Mixe r等等。
直到今年上半年,我们有了一定富余的人员和资源支持后,也开始紧锣密鼓地投入到路线验证的工作中去。在我们初期的尝试中,有对前文提到的优秀工作进行借鉴,但在实际落地过程中都没有取得显著的效果。我们总结了失败的经验,发现问题主要出在以下几个方面:
各家的 Baseline 优化程度、用户习惯、场景特性、建模目标、数据规模各不相同,落地方案的经验难以迁移,例如我们尝试 HSTU 原文的平铺式特征注入得到了比较差的效果,后来测试有效的 side info 融合效果和美团GR的方案比较接近。
各家的特征服务、样本服务、模型推理服务、业务架构各不相同,一些方案「过拟合」到了对应的具体系统的研发经验中,就很强的路径依赖。这种情况下,不是不想试,而是不敢试,缺少低成本的 MVP 方案来快速试错。
一些方案缺少关键的技术细节,尝试的 ROI 太低。例如我们尝试 HLLM 的时候,按照原文揣摩复现的时候,取得的效果远低于 baseline 双塔。我们猜测文本样本的构造可能是关键,但苦于东南亚小语种的样本试错难度过大,只能浅尝辄止。
注意力机制在 DLRM(传统深度神经网络推荐范式)已经深度集成,从旧范式到新范式,一些长期积累下来的特征工程和网络结构优化需要被「取舍」,结构优化带来的增益不一定能磨平范式切换带来的损失。
基于前面的思考,我将团队的探索方向聚焦到两个问题:寻找基于传统召回-排序系统可验证的 MVP 方案,以及将 LLM 领域已被验证的成功范式完整迁移过来。在这个路径上,我们和人大高瓴学院的研究团队一拍即合,尝试将 LLM-style 的推理技术落地至生成式推荐,进而提出了 OnePiece 框架,首次将类似 LLM 的上下文工程和隐式推理,注入到以 item ID 为语言的搜推模型中,并取得显著线上收益推全:

纵观 LLM 的发展,其爆发都有迹可循。我认为从 GPT-1~3 这个过程中,开源、开放的环境促成了 LLM 快速的产品化是和落地,如今,复刻 GPT-3.5 水准的模型已经不是难事。DeepSeek-R1、Qwen3 的开源更是大大丰富了高质量开源模型生态,孵化了众多 AI 应用。生成式推荐不太可能做一个通用推荐大模型开源,因为各家的数据不对外开放。那么生成式推荐话题下的技术报告更需要务实、深度、细节的讨论,才能加速这个领域的发展。
因此,为了让大家少走弯路,这篇文章会就 OnePiece 落地过程中看到的核心问题进行分析,解读我们认为对取得收益有帮助的关键细节,希望能带来有质量的开放讨论。
从 Paper 到落地:
DLRM 为什么难以超越?
和学术界的朋友们合作交流后,我们发现一个很有意思的现象。学术界的朋友会觉得我工业界的模型可能是一个 SIM 或者 PLE,而实际上真实的 DLRM 是一个「大杂烩」。除了包含前文提到的复杂的 attention 机制和多序列建模外,DLRM 难以被超越的另一个重要原因在于算力的分离:从在线迁移到离线,从模型迁移到数据工程。这里面积累了十几年整个行业的经验智慧。
第一,特征、模型工程。工业系统中的模型往往会使用成百上千的特征,数据类型覆盖序列、map、ID、实数、向量等等,这里往往积累了很多行业「老师傅」经验。同时,这些模型也不是「单一结构」的模型,它往往是各种优化的结合体(现在统称为 DLRM)。比如我们会用 DCNv2 或 xDeepFM 做特征交叉,会用类似 DIN 的 target attention 或者序列间的 cross attention 来做序列建模,会用 SENet 之类的结构做自适应的特征选择、会用 MMoE 或 PLE 类似的结构做多任务、多场景建模等等。甚至在 LLM 火爆之前,超长序列建模在搜推广领域早有应用。
换句话说,所谓「生成式」所倚仗的强大武器——基于 attention 进行序列内信息检索和聚合——在搜推广早有应用,甚至玩出的花样更多。生成式落地面临的挑战是,如何追平甚至超越DLRM体系中如此多样、丰富的领域知识积淀带来的强大加持。
第二,样本工程。熟悉 LLM 的小伙伴都知道,各家视为珍宝的训练数据配方和训练策略是 LLM 基座模型能够脱颖而出的重要因素。在传统的多级推荐系统,每个阶段(召回、粗排、精排、重排)都有自己的样本构造方式,而生成式推荐里面,最容易被忽视但又最重要的,依然是样本的构建。目前来看,样本优化依然是一片未开垦的处女地。
第三,投入产出比。DLRM 卷到今天,排序模型能稳定提升千分之几的离线 AUC,就能带来线上高额的收益,而且这种优化迭代往往不需要庞大的显卡资源消耗。工业系统最看重的就是 ROI,因此生成式推荐不能走 LLM 那种暴力怼算力提效果的路子,不仅 ROI 快速碰壁,一旦形成路径依赖,会给后续迭代造成巨大阻碍。因此,我们必须在低成本的限制下就验证清晰后续的优化路径并得到更有效的 scaling law。
从 DLRM 向生成式推荐的跨越,不是简简单单线上切换一个模型那么简单,还涉及到线上推理系统、线下训练系统、数据系统等大量系统或中间件的改造。如此兴师动众、伤筋动骨的改造不是一拍脑袋就能决定的。工业界的技术决策都是不见兔子不撒鹰的,只有真的能够突破 DLRM 的天花板,为平台带来真正的商业价值,我们才有驱动革新的号召力。因此,OnePiece 才会选择推理和上下文工程作为主要发力方向。
从LLM发展的视角看:
生成式推荐的验证之路
生成式推荐(Generative Recommender,GR)的落地之路虽难,但也不是毫无头绪。从 LLM 的发展来看,我们有非常多可借鉴的地方。
回看 LLM 的发展史,主要经历了 3 个重要阶段:
1)GPT-1~3 主要在验证数据配方、模型参数、Scaling Law。
2)GPT-3~3.5 主要在验证训练方法、策略。
3)GPT-3~4(o) 主要在验证模型推理以及 test time scaling law。
如果对标 LLM 的发展路径,只走通第一步是远远不够的。「生成式推荐」一定不能靠 parameter scaling 击败 DLRM 范式,这是由推荐系统现存的用户交互模式决定的。即便是在 ChatGPT 重塑 AI 交互模式的今天,推荐系统的用户仍习惯于当下的毫秒级、页面式交互方式。模型的 scaling 天花板很快会被在线推理耗时的硬门槛锁死。
同时,工业级推荐系统这种高吞吐、低延迟的场景最讲究「性价比」,模型参数扩大十倍如果只带来千分位的 AUC 提升,这样的资源预算是很难审批通过的。想让“生成式”这碗饭吃得更久,一个方向是追求极致的信息压缩比,另一个则是把 LLM 效能提升的「三步」都走通。在追求 ROI 的前提下,OnePiece 的选择是后者。
框架解析:OnePiece
OnePiece框架主要覆盖「两种模式」、「三个部分」:
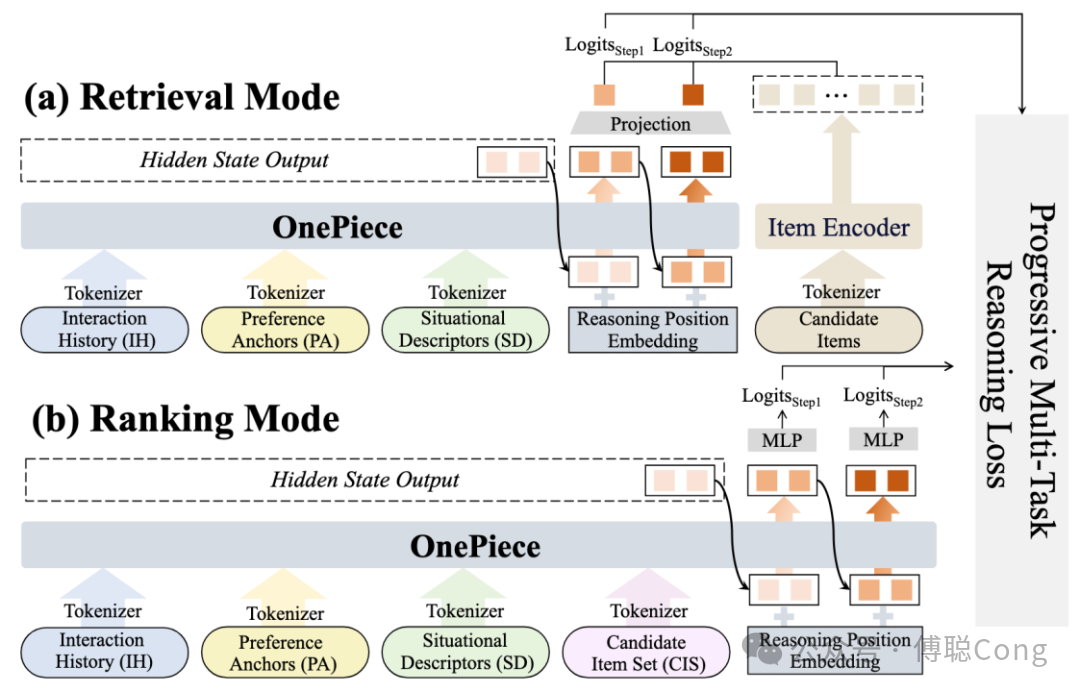
「两种模式」指的是当下工业级联 ranking 系统中抽象出来的两种截然不同的模式:召回模式和排序模式。
召回模式的特点是,候选集合非常大,动辄千万甚至上亿,因此在 inference 阶段,候选集合对模型「不可见」。排序模式的特点是候选集合相对较小,从数百到上千不等,难度在于「优中选优」。作为 DLRM 到生成式的「初探」,OnePiece 的选择是尽可能降低系统工程改造成本,让模型切换接近「无缝、无痛」,因此依然将召回、排序分开看待。
「三个部分」包含上下文工程(context engineering)、隐式推理(latent reasoning)和渐进式多目标训练策略。
第一个部分,上下文工程可以说是最近几个月来 LLM-智能体领域最性感的词汇了,它脱胎于提示词工程(prompt engineering),旨在为智能体(LLM agent)赋予动态的、高质量的上下文,辅助 LLM 进行「思考」。毫不夸张地说,是上下文工程让 LLM 成为了通用 AI 模型(general-purpose model)。通过精心设计的上下文,可以让同一个模型、同一套参数,在不同的语境、任务设置下,扮演不同的角色,完成个性化的任务。如果能将这种能力赋予推荐系统,那它必然是多场景建模、多路召回的福音,也将彻底改变推荐系统的优化迭代模式。
给生成式推荐激活上下文工程技能点最大的阻碍在于如何定义序列化的上下文格式和内容。在 LLM 语境下,所谓引导模型「思考」的上下文,是应用 CoT 技术,将拟人化的逻辑思考步骤用文本表达出来,填充到输入序列后,在文本空间引导模型 decoding 的方向。然而,生成式推荐模型的输入是以 item ID 为核心的序列,一般情况下,表达的是用户的历史交互行为。我们也可以说,推荐模型的语言体系,是基于 item ID 的特殊 token,模型能不能在 item ID 上构造上下文工程呢?
答案是可以的。回归上下文工程的本质,它是利用了文本序列模型的 test time few shot learning 的模式来让模型举一反三的,因此,我们想让推荐模型举一反三,就需要给出合适的例子。在我们的落地场景——shopee 主搜——我们测试了一些比较直给的「举例」方法:给模型展示给定 query 下的热门交互商品集合,模型在推理时,会在不同的 query 下看到不同的商品集合,从而引导模型往不同的方向 decoding,更形式化地,我们把为生成式推荐量身定制的 prompt 格式拆分为 4 个部分:
用户交互历史(Interaction History,IH),这部分包含了用户多种行为的交互历史,在实践中,我们把不同行为的历史进行混合,按照时间顺序排序、去重、标记交互类型,方便模型捕捉时间尺度的行为关系。
引导锚点(Preference Anchor,PA),这部分可以结合领域经验进行设计,目的是给模型展示动态的、多样化的、场景自适应的样例或锚定物品,注入人工设计的 inductive bias 来引导模型思考方向,例如前文提到的 query 下热门物品,我们在实践中融合了不同行为维度的集合(如下单、加购、收藏等)。
场景描述词(Situational Descriptor,SD),这是用来描述场景特殊性的 token,例如场景全局信息、用户全局信息,或者我们在个性化搜索常用的 query 全局信息,由于这类信息和前面的 item token 在语义层面和特征集合层面上属于异构 token,因此需要经过不同的 adapter(或者叫 tokenizer)来进行 embedding 映射。
候选物品集合(candidate item set,CIS),这是专属于 ranking 模式的上下文。在排序模式下,候选物品规模小,且对模型可见,因此我们可以将其纳入上下文构造的范畴。为了平衡计算效率和信息密度,我们将排序阶段庞大的物品集合通过随机分组的方式,拆成了多个 block,在推理阶段,各个 block 之间并行推理。
实验结果证明,上下文工程这里存在巨大优化空间以及一定的 scaling 效果:

随着 PA 序列的增长,我们融入了越来越多不同维度的 query 热门商品,观察到稳定的效果提升,同时 SD token 犹如定海神针辅助模型聚合、聚焦序列信息。
在这里,我们必须要提到的细节是,对传统特征工程信息的融合非常重要。序列中只有 item ID 是完全干不过 DLRM 的。在序列中融合「side info」的模式主要有两种:类似 HSTU 原文中的那种将 side info 平铺进序列;或者通过简单的 adapter 将 side info 和 item id 先融合成「latent token」,再构造出「一个位置一个 item」的 latent 序列作为 transformer 的输入。
OnePiece 选择的方式是后者。除了实践尝试了前者后发现效果极差外,平铺特征的模式会大大降低 token efficiency 和增大词表。想象一下如果要替换精排模型,一个 item 跟着大几百甚至上千特征,没几个 item 就会把 context window 的 quota 用完。因此我们浅尝辄止。
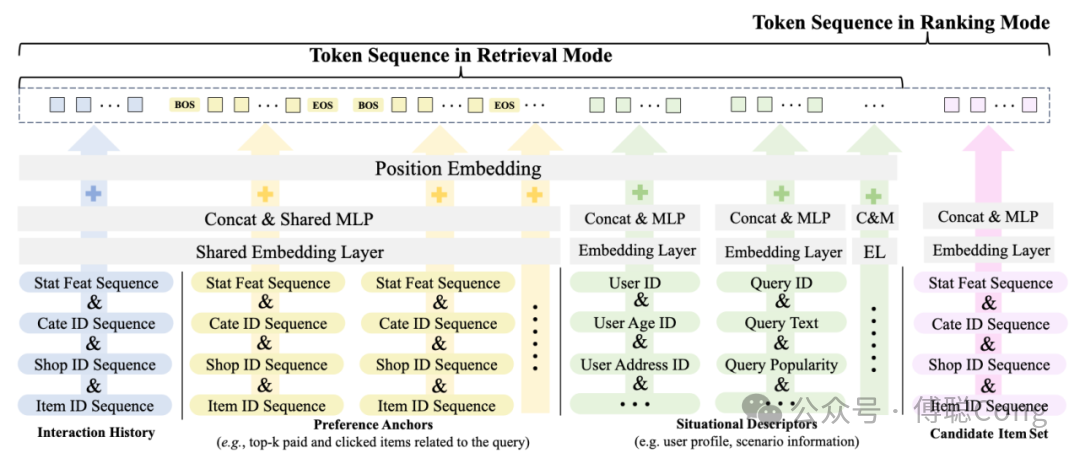
上图这个例子里面,user token 和 query token,相对于前面的 item token 来说,算是「异构」token,因此它们很奢侈地「独享」一套 adapter 参数。在 ranking 模式下,为了强化 candidate item 互相之间的「对比度」,我们允许 candidate item 使用比前序序列中的 item 更多的特征,因此两类 item 互相之间也是「异构」的存在,因此也不共享 adapter。实践表明,adapter 大道至简,我们用了最简单的 concat+linear 来实现。
为了适配 OnePiece 所需的样本和现存的训练平台,我们将所有阶段的样本都按照 listwise 建模的方式组织,并限制了各个组分的最大长度。将 prefilling 的序列结构和 target item 都放进一个序列,来保证样本读取、解析效率。增加 mask 信息来方便识别 target 物品集合。
第二个部分,隐式推理。
既然有隐式推理,那必然有显示推理。从 LLM 视角看,显式推理的代表性方法就是 CoT 或者 ReAct:我们给出了思考的引导词后,让模型在文本空间自回归地输出思考过程。诚如前文所言,生成式推荐的母语体系是 item ID,让模型在 item ID 这个词表上思考让人有些无从下手。因此,我们和 ReaRec 的作者,人大高瓴学院团队合作,尝试落地隐式推理的方式,强化模型 test time scaling 能力。
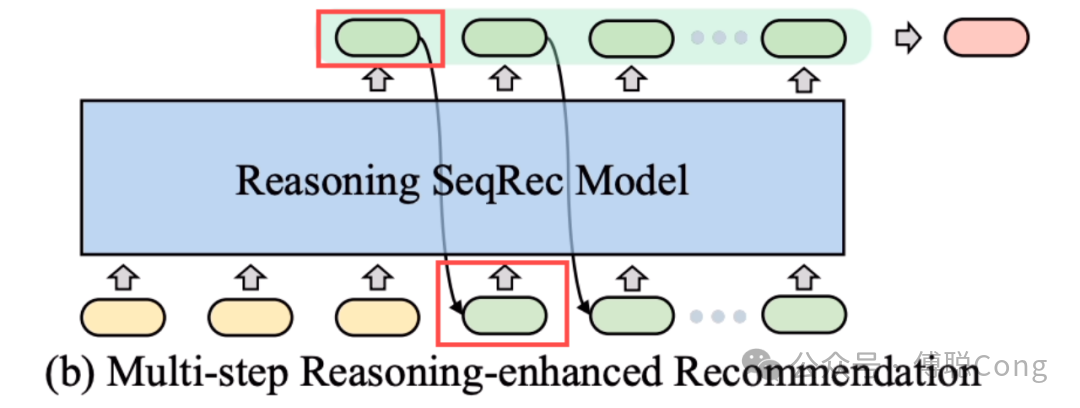
还是以 LLM 为例,让模型做显式推理,就是让模型在文本空间上先自我思考一阵,decoding 出第一步我要做什么,第二步我要做什么,最后再输出前序序列中问题的答案。隐式推理的最大特点就可以总结为「不做 decoding」。在我们的实践视角看,当模型在输入的上下文序列上完成计算后,最后一个位置输出的 latent token,其实聚合了整个序列中有助于预测的关键信息。这个时候要求模型通过 softmax 分布在词表空间解码,其实是一个「信息损失」的过程。既然 decoding 不可避免的会对信息进行「截断」,那么不妨让模型直接在 latent space 思考,这便是隐式推理(latent space)的核心思想。毕竟,人类在很多时候,比如所谓「灵光一闪」、「跳跃式思考」,都是无法在文本空间中表达出来的。如上图所示,在模型输出第一个 latent token(绿色)的时候,我们不进行 softmax 计算和 decoding,直接把这个 tensor 串到输入序列后面,作为新的输入 token 再过一遍 transformer,如此往复循环。
隐式推理除了能减少 decoding 阶段的逐 token 信息损失外,还有一个显著优势是大大减少了 decoding token 的消耗。这一点在 LLM 领域也有工作验证(CoCoNut)。这对于生成式推荐的推理来说简直是天降福音。我们的在线模型很难接受在处理了上下文序列成百上千个token后,又要让模型自我思考个成百上千 token 再输出答案。隐式推理基本上可以让这个过程在 5、6 个 token 内完成,节省了数十倍、甚至百倍的 inference 资源。
第三个部分,渐进式多任务训练策略。隐式推理在 LLM 领域和搜推领域出现的时间都不长,我们在实践中发现,虽然隐式推理能够几乎完全保留思考过程中的全部信息,但这种“完全保留”对于推理而言并不一定是好事。
前序的上下文构造即便再怎么优化,都无可避免的会引入噪声。如果把 multi-head attention 理解为一种 neural retrieval,那么我们希望思考的过程中,模型可以完成「取其精华,取其糟粕」。早期的 Latent Reasoning For Rec 的工作(例如 ReaRec 等),在训练过程中会遇到明显的稳定性问题,我们认为问题的关键在于 latent reasoning 的阶段缺少有效的「过程监督」。受到 ReaRec 的 progressive learning 模式的启发,以及结合我们之前在渐进式多任务学习的经验(GNOLR: https://arxiv.org/pdf/2505.20900),我们尝试在隐式推理的过程中增加循序渐进的监督信息来引导模型的思考过程,来取得更好的结果:
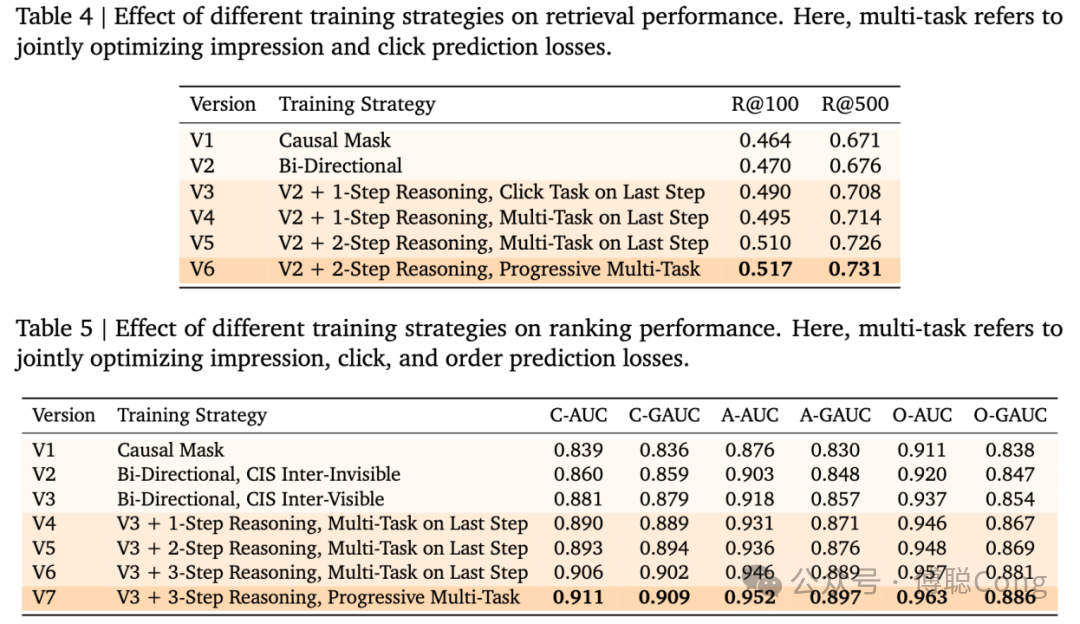
通过实验我们可以看到多步推理和渐进式的监督相结合能带来更大增益。我们可以把这些隐式推理追加的 latent token 理解为类似 Bert [CLS] token 那种 read-out token。通过它们,我们可以将序列中的信息再进行检索和聚合,并根据互相独立的监督信号筛选相关信息。同时,避免多个监督信号扎堆在同一个 token 上,也可以缓解信息瓶颈和梯度冲突等老问题。
整个实验过程我们使用的都是两层的 transformer,hidden size=256,pre-norm 结构。在大量的实验中,我们发现虽然我们设计的上下文工程框架和隐式推理不挑 backbone,但 HSTU 相比于 transformer 仍然展现出较差的稳定性和 scalability:
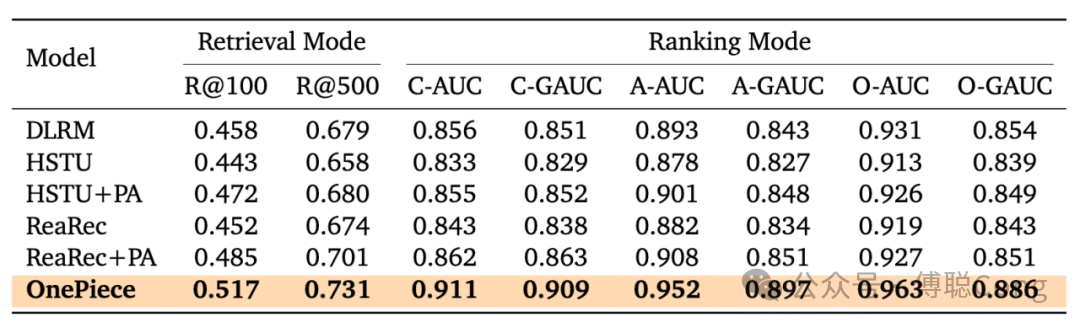
在训练过程中,我们还发现一个现象。DLRM 范式的模型前期起得快但天花板底,生成式模式下的模型收敛较慢,需要大量数据喂养。通过充分的超参数调优,transformer 会和 HSTU 逐渐拉开差距:
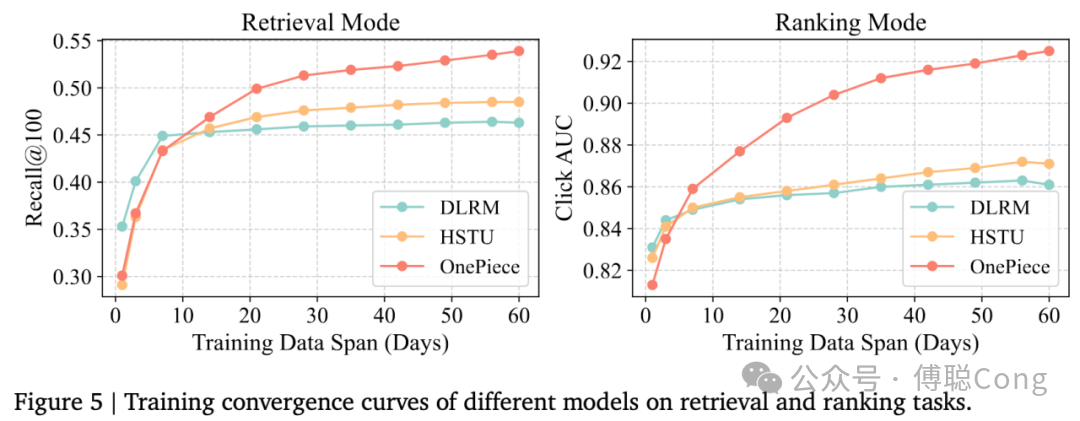
从 attention 透视:模型的思考过程
为了充分理解为什么 OnePiece 框架有效,我们对收敛后的模型进行了 attention 可视化。在随机采样得到的 attention 热力图中,我们看到了惊人一致的结果。我们分别看看召回和排序模式下,序列建模阶段和推理阶段,模型分别在想什么。
首先是召回模式:
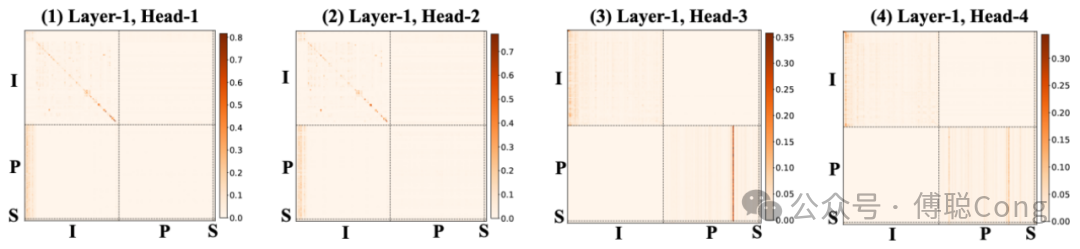
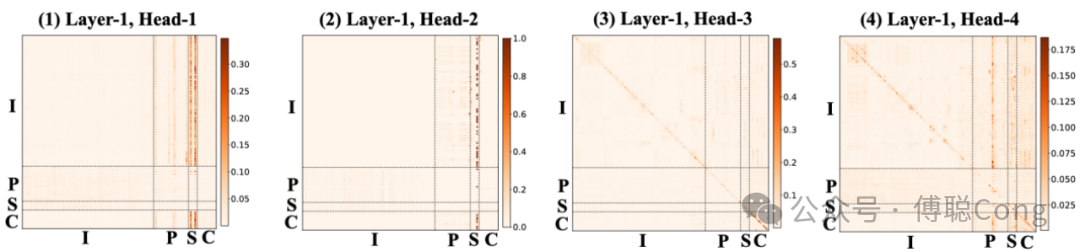
分别看第一层的 4 个 head,左侧两个 head 在 I 序列(用户交互历史)的对角线上形成了一些「菱形」方块,这部分是在自动捕捉用户行为序列内部,时间尺度上的聚类信息。我们分析了序列内容后会很容易发现,用户行为历史可以按照时间被切割成一簇簇的子集。这是因为在一个较小的时间窗口内,其行为主题是高度一致的。比如某个用户前三天可能一直在看零食相关的商品,后三天可能集中浏览美妆相关的商品。我们可以把这种高度内聚的时间簇理解为一种特殊的会话窗口(user session)。
同时,左侧两个 head 的左下角的部分,捕捉到了用户最近期行为和 P 序列(query 热门 item)之间的相关性。而右边两个 head 则关注I序列和P序列各自内部的信息,尤其是用户最近起行为,以及 P 序列内部少数高亮的锚点商品。
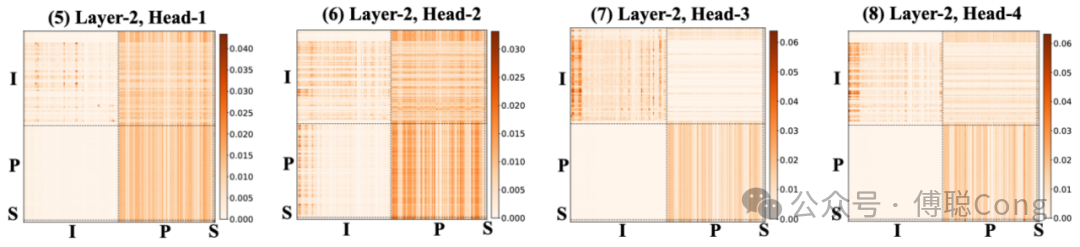
而到了第二层,大幅度跨域信息交叉会更明显,对用户最近期行为的关注度也会更高。但比较明显的是,以 P 为 Query,以 I 为 Key 的信息迁移较少(左下角方块)。模型更关注将 P 序列的信息迁移叠加到 I 上,说明模型受到提示词(PA 序列)的影响,在对 user 行为历史的信息进行过滤、擦除、融合、甚至「重写」。这体现了精心设计的 PA 序列作为思考引导的重要作用。
而到了推理阶段,SD token 开始发挥重要作用:
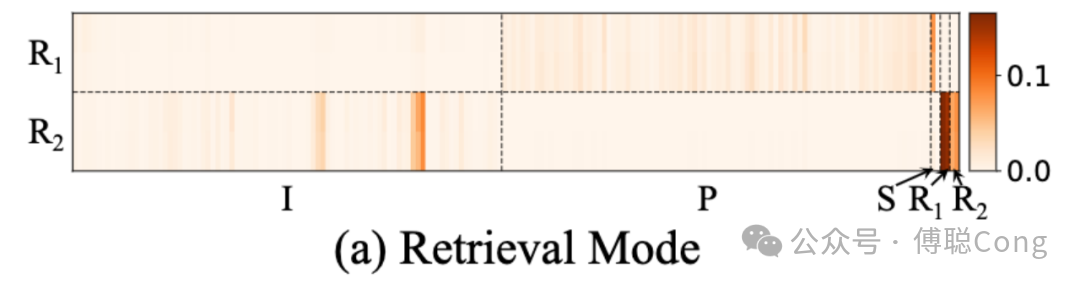
召回模式下我们进行了两步推理,第一步受到「曝光」信号监督,让模型学习筛选精排「看得上」的商品。第二步受到「点击」信号监督,让模型学习筛选用户「看得上」的商品。我们可以明显看到,第一步(对应 attention 可视化的 R1 行),SD token(包括 query 文本、用户活跃度等描述性、异构信息)高亮、PA 序列内部少数位置高亮,说明精排「喜欢」的商品大部分和 query 下热门商品类似,模型在 PA 中寻找样板商品,并将信息聚合至 R1(1st reasoning block)。而到了第二步,用户序列内部少数热点高亮、R1 token 高亮,说明 R2-block 在从 R1 继承已经聚合的信息,并从用户行为序列中寻找用户个性化偏好相关的依据。
接下来,我们再来看排序模式。这里比召回多出来的 C 区域是 candidate items。
我们可以看到,排序模式下,左边两个 head 更加关注 SD token,在将 SD token 所蕴含的场景、用户特意化信息迁移至整个 I 序列(用户行为历史)和 C 序列(目标集合),方便后续层级进行融合、读写和对比。右边两个 head 呈现了和召回类似的模式,在寻找用户历史中的会话聚类。同时,在右下角 C 区构成的小方块,在目标 candidate 结合内部进行信息迁移,我们认为模型在寻找 candidate 内部的共性和差异。
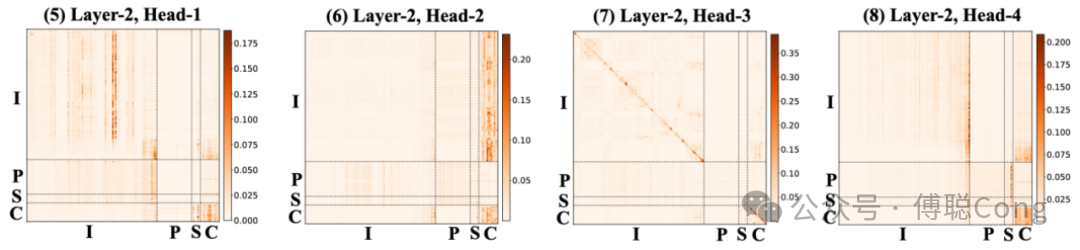
同样,到了第二层,跨域的信息迁移程度更加剧烈起来。I 序列的信息被迁移至 C 中,尤其是用户最近期的行为。注意,这里由于在线样本系统的问题,在排序阶段,I序列中最右侧(作为 Y 轴看是最下侧)是最近的行为,而召回模型是反过来。同时,最右下角部分的明暗对比度增加,信息集中向少数位置迁移,我们认为模型几乎完成了 candidate 之间的比较。
在推理阶段,candidate 基本就成为了模型的唯一关注点。
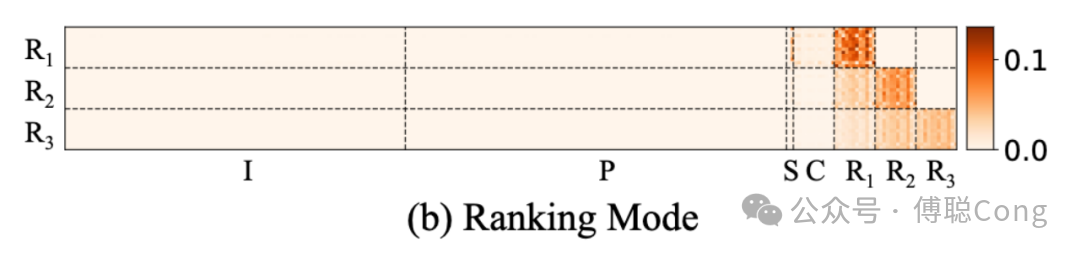
这是因为在 prefilling 的 forward 计算阶段,从 I、P、S 序列向 C 序列的信息迁移基本完成。模型有足够的信息在 candidate 之间做出区分。同时,每向前推理一步,当前的 reasoning head 都更多地从离自己最近 reasoning block 聚合信息,考虑到我们用 click->cart->order 这样的顺序进行逐步引导,这样的信息筛选模式也符合预期。
离线训练和在线实验
首先,我们看特征、样本构造的问题。
从实验结果看,item side info 的引入对模型效果有重要影响。然而,在序列侧引入大量特征会造成离线样本体积以及在线样本表剧烈膨胀。为了能够低成本地验证效果,我们对序列侧特征做了极致的精简。上线版本 OnePiece 用到的特征数量不到 DLRM 的二分之一。
关联哪些特征的问题解决了,另一个重要的抉择是关联哪天的特征。从防止时间穿越的角度看,我们认为序列里的 item 应该根据行为发生当天的时间来决定关联特征的时间分区。
举个简单的例子,某用户在二十天前买了一部手机,其价格是原价的 95 折,在构造样本的当下,该手机商品已经取消了 95折 活动,我们应该给二十天前的这个行为关联哪个价格作为特征呢?我们认为关联二十天前的价格更合理,这是因为用户的决策是基于 95 折后的价格做出的,如果是原价,用户未必会买。关联准确的特征,有利于我们准确地理解用户的兴趣、购买力等特征,以便于用户做出准确的判断。
从这种新型样本形态来看,最准确的样本,应当是取得用户实时行为序列中的 item ID,在线查询对应的 item 特征表,获取到特征后,拼接成二维序列后,送给模型并异步 dump 到离线形成样本。为了节省二次查询的延迟,已经发生过的行为历史查询到特征后,应当在存储中固化下来,那么在线的序列特征表应当是一个双端队列,最新的行为查询到 item 对应特征后push到「队列尾」,过期或超长的 item 可以动态出列。这种方式对当下的样本服务流水线改造成本过高,因此我们实际上通过离线模拟序列特征拼接,并按天级别 update 二维序列表来简单快速验证通路。这样做的损失在于,在线推理时,用户当天实时发生的行为无法被更新,会带来一定效果折损。考虑到离线收益相对提升够高,我们暂时接受这部分效果损失上线。
其次是模型训练的损失函数和超参数。
我们在召回和排序两种模式下都应用了类似 InfoNCE 的对比学习损失。这种损失函数的好处在于,我们可以很容易拉开正负样本的 margin,强化模型的泛化性。但由于这种对比学习的损失函数只关注 margin,但不关注 logits 的数值分布,我们叠加了 BCE 损失作为 calibration loss,辅助模型稳定学习。
值得注意的是 BCE 损失作为 calibration loss,在 DLRM 召回模式下并无卵用,只有 InfoNCE 损失,DLRM 的召回模型也可以正常收敛。但 OnePiece 模式下,则会让 logits 数值起飞,飞往无穷大直到梯度全部 NaN。这时应用 BCE 来稳定 logits 有奇效。关于为何 transformer 模式下,模型容易出现 NaN,我们的观察是因为 transformer 容易引爆 latent embedding 的 norm。DLRM 模式下,序列特征往往只有 item id,attention 的主力也是类似 DIN 的 target attention,这种问题不明显。
但在 OnePiece 模式下,大量的 side info的embedding 和 item id embedding 一起融合后送进模型,不注意调参的话,会让输入序列的 token norm 很大。又因为 transformer 会将 embedding 通过残差链接起来,output token的norm 会随着层数增加剧烈增加,这个是深层 transformer 训练的老问题了。再加上对比学习的引导,output token 的 norm 会随着训练快速起飞,很容易就超越精度边界。没想到生成式推荐染上了「LLM 病」。
因此,为了稳定训练,除了应用 BCE loss 外,我们还根据之前工作的经验——
GNOLR: https://arxiv.org/pdf/2505.20900,人工控制logits的范围。
具体来说,就是把 sigmoid(x) 改成 sigmoid(ax+b),缩小正例 item embedding 到 user embedding 的角度,让 item embedding 的空间「舒展开」,增强稳定性。同时我们针对所有原始特征的 embedding 初始化进行了小区间的截断,从原来的正负 0.1 区间,缩小到正负 0.02。也分别调节了 dense 参数和 embedding 参数的学习率,既保证 embedding 不会落后 dense 的学习速度,也不会学太快导致梯度爆炸。
接着是模型上线服务的问题。
召回模型上线比较容易,因为在线的部分,只需要针对 user embedding 进行推理。我们在排序模式下的上下遇到较大阻力。这是因为我们的模型服务平台是针对 point wise 打分深度优化的平台,而我们离线测试带来显著收益的部分是 blockwise reasoning,它要求我们需要针对在线打分的商品先分组再打分,改造成本较高,同时模拟环境下大 block 推理的耗时会上涨比较明显。我们针对 block size 进行了降级测试,当 block size 降到 1 时,模型可以无痛上线,虽然效果有明显折损,但仍优于 DLRM 模型,拿到了结果,我们可以推动推理平台进行改造:

最终,我们在召回模式下上线正常的 block wise reasoning,而在 prerank 阶段上线了残血版(block size=1)的 OnePiece。OnePiece 的训练和推理都基于 tensorflow 框架。训练平台是典型的 sample serve+parameter server+training server 的架构,通过 pipeline 并行可以基本隐藏样本、梯度、参数等 IO,结合 batch grad 累积,模型离线训练 MFU 可以稳定在 100% 附近。在线服务平台对齐离线,也是 parameter server+feature server+inference server,巨大的 embedding table 存储在 CPU server,推理显卡采用多模型实例并行推理的模式,在 DLRM 切换为 OnePiece 后能观测到明显的 MFU 上升。
这主要得益于模型计算并行度的大幅度增加(DLRM 往往是多结构拼接加串行塔状结构,越高层级越容易有互相等待和计算浪费)。在流水线并行下观测到的在线推理 MFU 并不准确,准确测试起来比较麻烦也没必要,总体来看生成式上线不一定会带来显著的硬件资源压力,适当的计算规模下,只是把原来没能利用好的计算资源用得更充分。由于结合了隐式推理,整体显存的使用率会明显提升,主要是 kv cache 带来的消耗,这里我们是手动在 tensorflow 里实现的 kv-cache,后续应该还有面向硬件的优化空间。
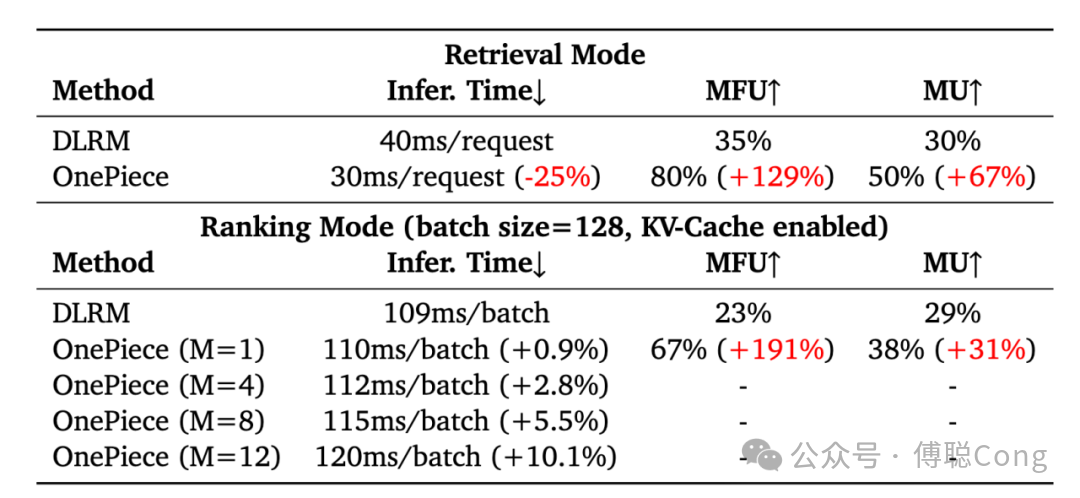
然而,可以预见的是,随着模型参数 scale up,未来推理 MFU 会急剧下降。目前的 MFU 得益于模型尺寸非常小,显存带宽够用,高并发能带来极高的利用率。当模型尺寸上升,显存带宽会成为主要瓶颈,参数低 bit 量化会是大势所趋。
最后,我们看实验结果。在排序阶段,我们取得了 1.12% 的 GMV/user 收益和 2.9% 的广告收入增益,我们只用了 OnePiece 推理第一步和第三步输出的 ctr 和 ctcvr 分数来参与公式调节。在召回阶段,OnePiece 初步试水的目标是替换旧的 DLRM U2I baseline,取得了 1.08% Gmv/user 和 0.98% paid order/user 收益。
详细分析召回阶段收益时,我们发现了有趣的现象:
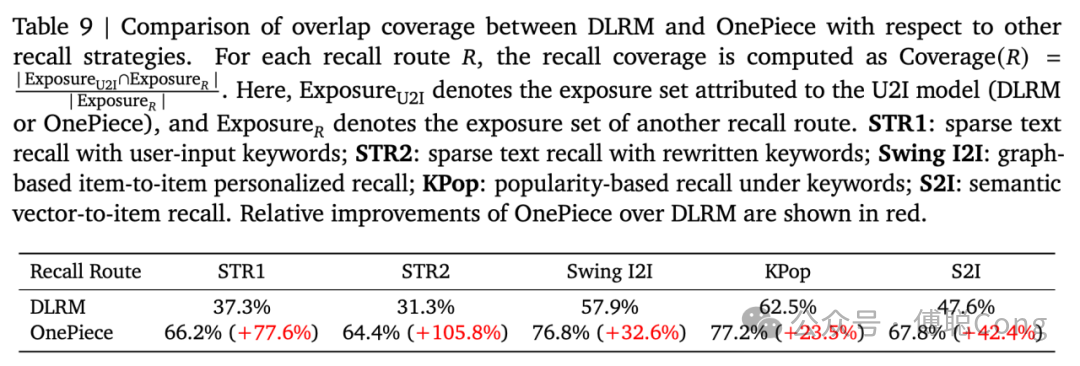
我们首先计算了 OnePiece 召回相对于其它召回策略的曝光覆盖率。由于我们上线的是个性化搜索场景,所以代表性的召回策略包括原词召回、改写词召回、语义召回等面向文本语义相关性的策略,也必须支持面向热度、流行度和个性化的召回策略,例如 swing 和 top 榜单等。
通过合理调整用户历史行为序列和 PA 序列(query 热门锚点商品)的配比以及内容,OnePiece 实现了相关性语义、个性化、热度的均衡。尤其是语义相关性的覆盖,相对于 DLRM baseline 有一个巨大的提升。做到这一点是很难的,尤其是旧的 DLRM 范式。
在 DLRM 范式下,我们也可以通过人工构造相关性导向和个性化导向的特征和训练目标来进行平衡。例如我们那旧的 DLRM baseline 用到了 query 原词、改写词构成的文本,通过内嵌一个 text-CNN 来抽取简单的文本特征,通过和 item 标题文本设定独立的交叉目标来强化模型的相关性;同时,也用了复杂的多视角、多行为、多特征的用户历史序列来捕捉个性化信息,通过图片表征等额外特征构造 item 多模态信息。
如此庞杂的信息抽取、融合由 DLRM 网络自主完成,并受到相关性和个性化目标来监督。然而两者的平衡是非常困难的,往往出现此消彼长的跷跷板效应:提高相关性权重会降低个性化程度,用户不喜欢,从而降低在线效率指标(GMV 等);提高个性化权重则会降低相关性考量,引入大量无关 bad case,降低用户体验。行业内大家的经验是两者很难平衡,所以 U2I 往往很难扩召回。稍有不慎就会引入大量 bad case。神奇的是,OnePiece 没有引入相关性目标,靠模型自身能力捕捉到了相关性诉求,我们认为这部分的效果源自 PA 序列的设计,给模型看到了很好的范本。虽然 DLRM 模型也用了 top k item 的序列特征,但却没能够自动捕捉到这部分信息。
同时 OnePiece 相对于 DLRM 也有着很高的独立贡献度:
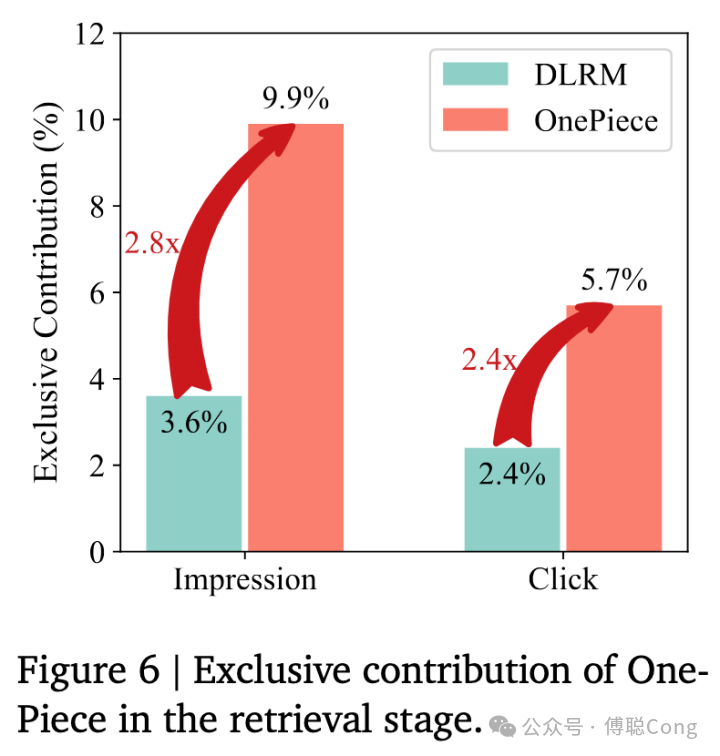
我们分别统计了被 DLRM U2I baseline 独立召回的商品占比,和被 OnePiece 独立召回的商品占比。其中 Impression 占比的提升说明 OnePiece 独立召回了大量的能被精排等后续模块认可的商品,同时,click 占比的提升说明 OnePiece 独立召回的商品能够被用户认可。
探索与利用(Explore&Exploit)是推荐系统永恒的主题。从前面的结果看,对其它召回路径的覆盖说明了 OnePiece 有着强大的 Exploit 能力,能够有效地从历史数据中挖掘协同过滤的信息;而独立召回贡献度的大幅度提升说明了 OnePiece 强大的 explore 能力。说明模型以用户历史偏好为轴心,向外推理、扩展的时候能够挖掘到用户潜在的偏好,拥有更强的泛化能力。
从这组数据分析引申出来的意义是,OnePiece 初具 General-Purpose Model 潜质。通过合理设计 PA 序列的部分,模型可以实现更好的个性化和相关性的平衡。而 PA 的本质,是搜推工程师行业经验的信息注入。我们可以通过 query 下热门商品来引导模型向着相关性和热度方向进行有效预测,那也可以通过注入其它 inductive bias 来引导模型向其它方向思考、预测。例如通过注入 I2I graph 信息,来引导模型去模拟图上的多跳关系推理等等。通过设计优化这些特殊的 prompt,我们可以实现一个模型多路召回的迭代新范式:
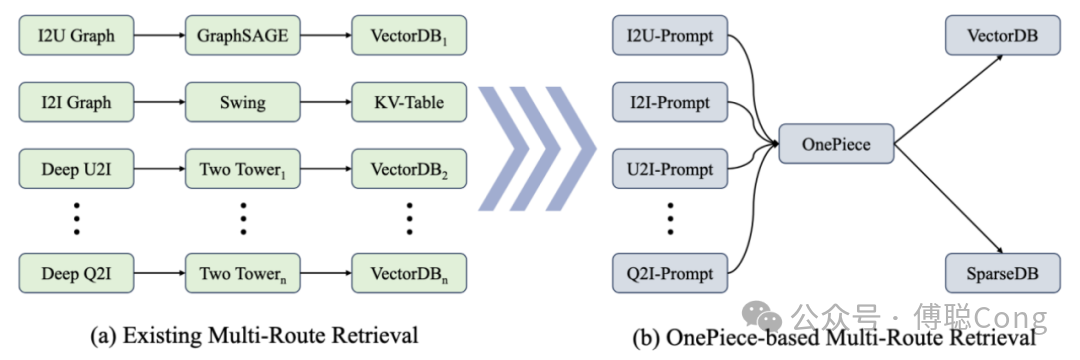
2025,生成式推荐进入了大航海时代!未来,我们团队会围绕三个关键词进一步迭代:压缩、检索和通用化。我们也欢迎更多小伙伴加入一起讨论、合作!
* 傅聪老师 GitHub 主页:https://github.com/CongFu92
* 个人邮箱:fucong92@126.com






戳“阅读原文”,免费获取海量数据集资源!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢