
当人工智能不断演进,用户对于大模型的交互需求不再局限于单一的文本问答或图文对话,而是希望能像与人交流一样,自由运用语言、图像、音视频进行沟通。现有的技术方案大多仍局限于少数几种模态的组合,或在某一特定模态上进行专项优化,距离跨模态的深度融合与流畅交互仍有差距。
基于此,阿里通义千问团队发布了原生全模态大模型 Qwen3-Omni,包含 Qwen3-Omni-30B-A3B-Instruct(指令跟随)、Qwen3-Omni-30B-A3B-Thinking(推理)和通用音频字幕器 Qwen3-Omni-30B-A3B-Captioner。它通过端到端的统一架构,实现了对文本、图像、音频、视频四大核心模态的深度理解与生成,并能够以文本或自然语音的形式进行流式输出。
Qwen3-Omni 致力于在单一模型中实现多模态能力的均衡发展和高效协同,减少以往多模态模型在不同能力之间的权衡取舍问题,为跨模态交互拓展了新的可能性,也推动了多模态大模型从「单点突破」向「全能协作」的进一步演进。
目前,HyperAI超神经官网已上线了「Qwen3-Omni:突破模态边界的全能选手」「Qwen3-Omni-30B-A3B-Captioner:音频描述大模型」,快来试试吧~
在线使用:
「Qwen3-Omni:突破模态边界的全能选手」
https://go.hyper.ai/jvqEE
「Qwen3-Omni-30B-A3B-Captioner:音频描述大模型」
https://go.hyper.ai/Jnz7b
9 月 22 日-9 月 30 日,hyper.ai 官网更新速览:
* 优质公共数据集:10 个
* 优质教程精选:7 个
* 本周论文推荐: 5 篇
* 社区文章解读:5 篇
* 热门百科词条:5 条
* 10 月截稿顶会:6 个
访问官网:hyper.ai
公共数据集精选
1. Brain Tumor(MRI)Detection 脑肿瘤影像数据集
Brain Tumor(MRI)Detection 是一个用于检测是否有脑肿瘤的医学影像分类数据集,旨在为机器学习模型提供用于脑肿瘤检测任务的 MRI 图像样本。该数据集由磁共振成像(MRI)图像构成,图像被划分为含有脑肿瘤的病例和不含脑肿瘤的正常病例两类。
直接使用:https://go.hyper.ai/1MGt3
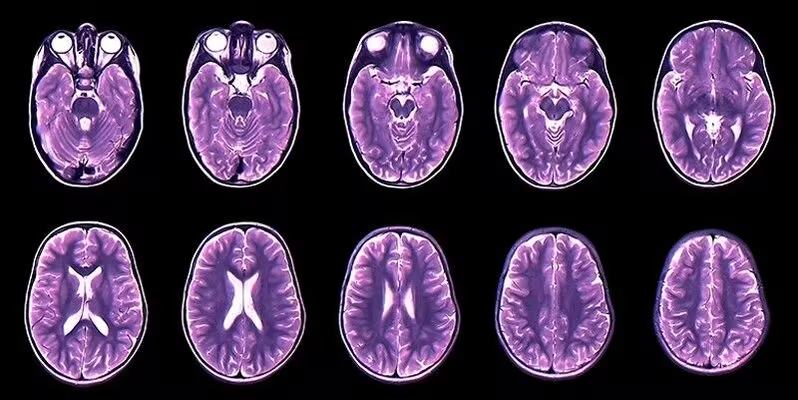
数据集示例
2. BRISC 2025 脑肿瘤 MRI 分割与分类数据集
BRISC 2025 是一个用于脑肿瘤分割与分类的磁共振成像(MRI)数据集,该数据集同时支持两类任务:一是分类任务,即基于 MRI 图像的多类肿瘤识别;二是分割任务,即利用配对的 MRI 图像与掩模进行像素级肿瘤区域检测。其组织结构清晰,图像与掩模文件名严格对齐,便于直接应用于深度学习模型的训练与验证。
直接使用:https://go.hyper.ai/cOBZ4
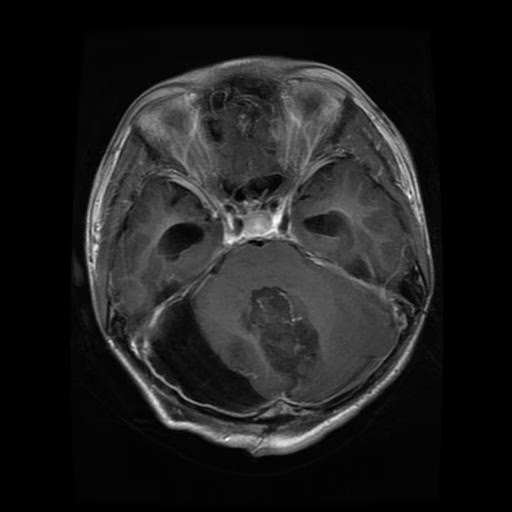
数据集示例
3. GenExam 多学科文生图考试基准数据集
GenExam 是由上海人工智能实验室联合上海交通大学、清华大学等机构发布首个多学科文本到图像的考试风格基准数据集,旨在检验模型是否能够整合理解、推理与生成能力,从而真正解决绘图类问题。
直接使用:https://go.hyper.ai/AWu0s
数据集示例
4. Nav CoT-110k 轨迹推理数据集
Nav CoT-110K 是一个专为具身导航(embodied navigation)任务构建的大规模轨迹推理数据集,旨在训练和评估模型在复杂三维场景中进行结构化推理与动作规划的能力,并作为 Nav-R1 框架冷启动阶段的重要基础。
直接使用:https://go.hyper.ai/HR64E
5. MMPR-v1.2-Prompts 多模态推理提示语数据集
MMPR-v1.2-Prompts 是由上海人工智能实验室联合清华大学、复旦大学等机构发布的一个面向多模态推理偏好学习的提示语料集合,旨在支持模型在复杂的视觉–语言推理任务中的训练与评估。
直接使用:https://go.hyper.ai/Pe4RV
6. CHIRLA 高分辨率人物重识别数据集
CHIRLA 是由阿利坎特大学计算研究所发布的一个用于人物重识别(Re-ID)与跟踪研究的多摄像头视频数据集,旨在评估长期、复杂场景下的 Re-ID 与跟踪算法性能。数据集内包含的所有视频帧均经过半自动标注,构建了一个大规模的多视角、多时间跨度的多人跟踪与重识别标注数据集。
直接使用:https://go.hyper.ai/shhvL

数据集示例
7. MultiEdit 多模态图像编辑数据集
MultiEdit 是由 inclusionAI 联合新南威尔士大学和香港大学等机构发布的一个全面的大规模基于指令的图像编辑数据集,旨在推动模型在复杂、多样化的图像编辑任务中的能力提升。该数据集覆盖 6 大编辑任务与 56 种子类别编辑类型,包括对象引用编辑、人物引用编辑、文本与界面元素调整、视角变换及风格迁移等。
直接使用:https://go.hyper.ai/g5YH1
8. InternScenes 室内模拟场景数据集
InternScenes 是由上海人工智能实验室联合上海交通大学、北京航空航天大学等机构发布的一个具有逼真布局的大规模可模拟室内场景数据集,相比以往数据集,该数据集特别保留了大量小型物体,从而构建出更加逼真且复杂的场景布局,每个区域平均包含 41.5 个对象。
直接使用:https://go.hyper.ai/f1bnk
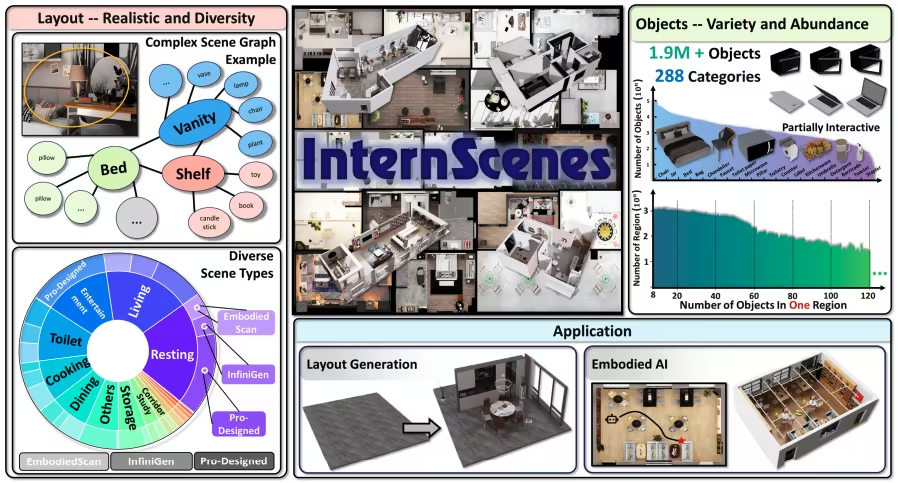
数据集示例
9. Health & Lifestyle 健康生活方式数据集
Health & Lifestyle 是一个有关健康生活方式数据集,旨在探索生活方式因素与个体健康状况之间的关系,为健康预测建模、聚类分析和数据挖掘提供实验基础。该数据集共包含 100,000 条个体记录,以 CSV 表格的形式提供,涵盖了从人口统计学特征到健康状态与生活习惯的多维度信息。
直接使用:https://go.hyper.ai/vyuBz
10. Sleep Disorder Diagnosis 睡眠障碍诊断数据集
Sleep Disorder Diagnosis 是一个有关睡眠健康和生活方式数据集,旨在为研究睡眠习惯、生活方式与健康状况之间的关系提供数据支持。该数据集包含 374 个个体样本,每个样本均记录了多维度的特征信息,最终以是否存在睡眠障碍及其类型作为目标标签。
直接使用:https://go.hyper.ai/b1TLw
公共教程精选
本周汇总了 3 类优质公共教程:
* OCR 教程:2 个
* Qwen 系列教程:3 个
* 音频生成 TTS 教程:2 个
OCR 教程
1. POINTS-Reader:无蒸馏端到端的轻量级文档视觉语言模型
POINTS-Reader 是由腾讯、上海交通大学与清华大学联合推出的一款专为文档图像转文本设计的轻量级视觉-语言模型(VLM)。该模型不追求参数规模,也不依赖教师模型「蒸馏」,而是通过一套两阶段自进化框架,在保持结构极简的同时,实现对中英文复杂文档(含表格、公式、多栏排版)的高精度端到端识别。
在线运行:https://go.hyper.ai/yM506

效果示例
2. Granite-docling-258M:轻量多模态文档处理模型
Granite-Docling-258M 是由 IBM 推出的轻量级视觉语言模型,专为高效文档转换设计。该模型能将文档转换为机器可读格式,同时完整保留布局、表格、公式等元素,支持多语言(包括阿拉伯语、中文和日语)处理。
在线运行:https://go.hyper.ai/b8WSY
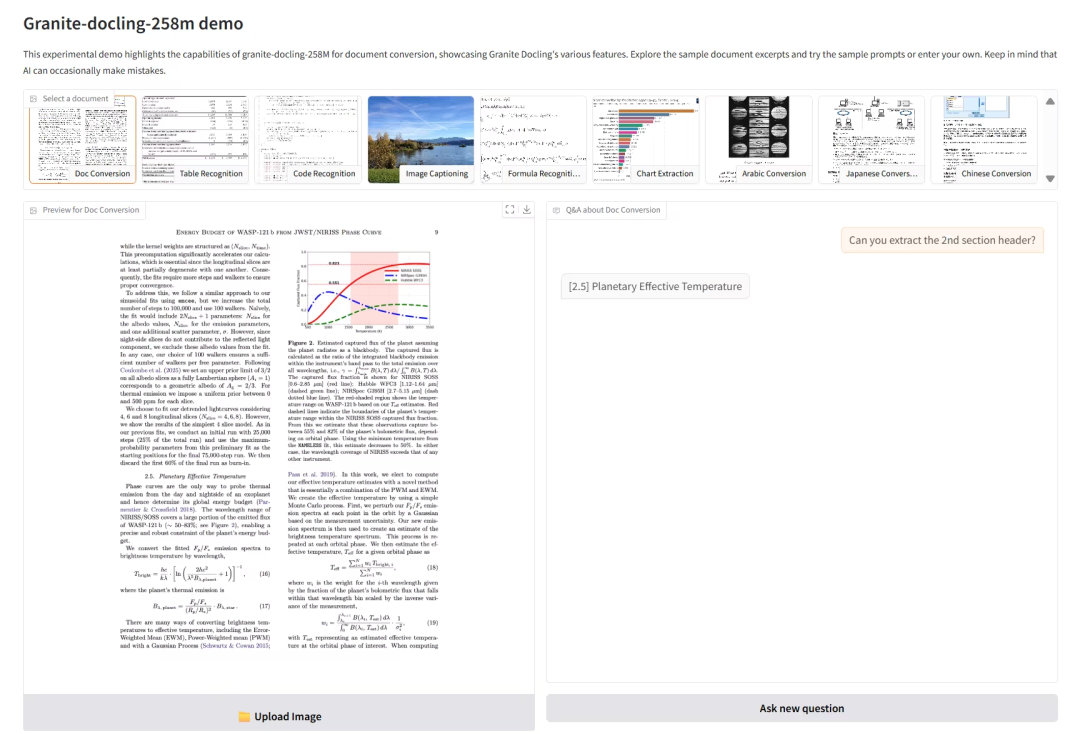
效果示例
Qwen 系列教程
1. Qwen-Image-Edit-2509:多图像编辑器
Qwen-Image-Edit-2509 是由阿里巴巴通义千问团队发布的全能图像编辑模型。新版本模型相比 8 月份开源的 Qwen-Image-Edit,单图编辑的一致性有所提升,同时新支持多图编辑功能,支持深度图、边缘图、关键点图,可控性更强,出图更自由。
在线运行:https://go.hyper.ai/1TJnb
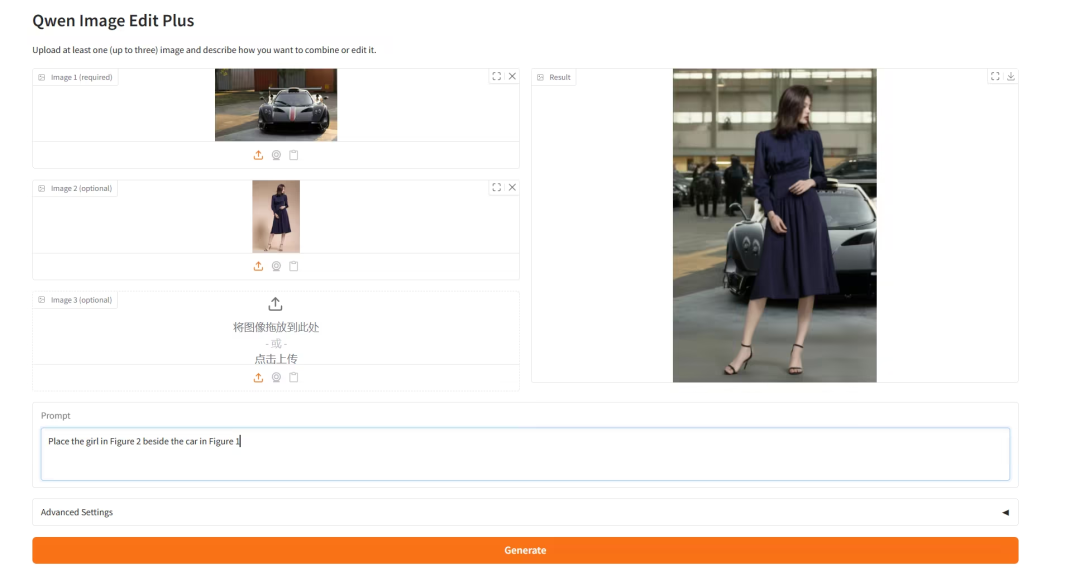
效果示例
2. Qwen3-Omni:突破模态边界的全能选手
Qwen3-Omni 是由阿里巴巴通义千问团队推出的业界首个原生端到端全模态 AI 模型,能够处理文本、图像、音频和视频多种类型的输入,并可通过文本与自然语音实时流式输出结果,解决了长期以来多模态模型需要在不同能力之间进行权衡取舍的难题。
在线运行:https://go.hyper.ai/jvqEE
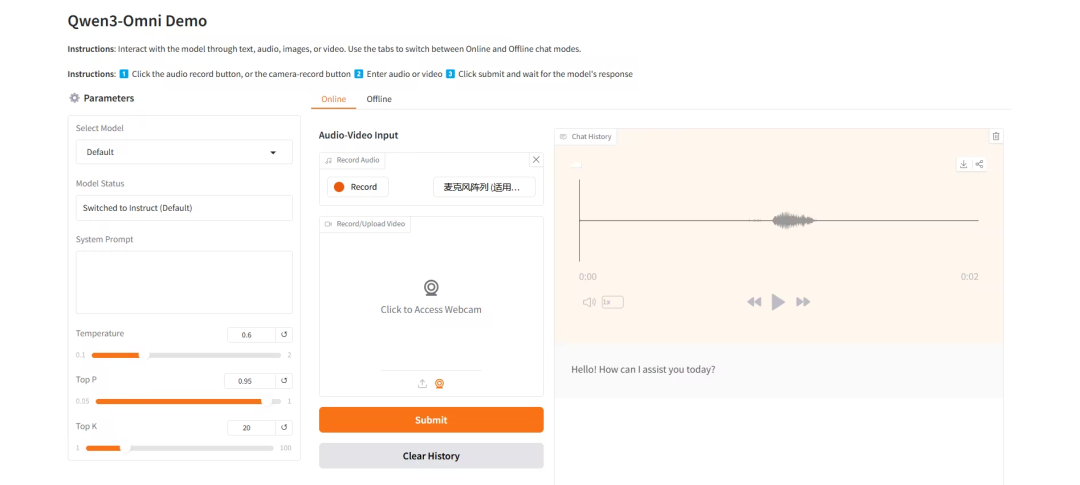
效果展示
3. Qwen3-Omni-30B-A3B-Captioner:音频描述大模型
Qwen3-Omni-30B-A3B-Captioner 是由阿里巴巴通义千问团队发布的音频描述大模型,无需任何提示,该模型能够自动为复杂语音、影视声效等生成精准全面的描述,能识别说话人情绪、音乐元素(如风格、乐器)、敏感信息等,适用于音频内容分析、安全审核、意图识别、音频剪辑等多个领域。
在线运行:https://go.hyper.ai/Jnz7b
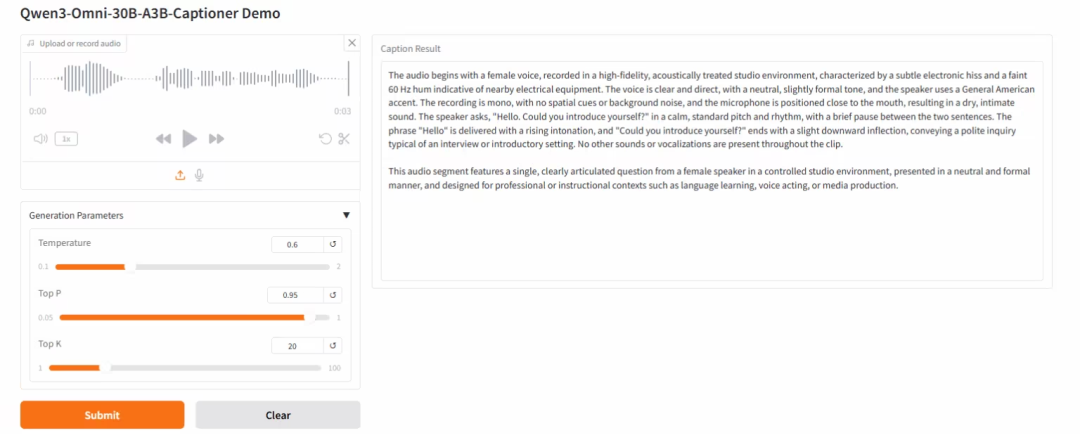
效果展示
音频生成 TTS 教程
1. VoxCPM:无分词器的 TTS 技术
VoxCPM 是由面壁智能与清华大学深圳国际研究生院联合开发的 0.5B 参数语音生成模型,在语音合成的自然度、音色相似度及韵律表现力方面达到了业界顶尖水平。该模型采用端到端的扩散自回归架构,直接从文本生成连续语音表示,突破了传统离散分词的局限。
在线运行:https://go.hyper.ai/a4erS
效果展示
2. IndexTTS-2:突破自回归 TTS 时长与情感控制瓶颈
IndexTTS-2 是由哔哩哔哩语音团队开源的新型文本转语音(TTS)模型,在情感表达和时长控制方面实现了重大突破,是首个支持精确时长控制的自回归 TTS 模型。同时该模型支持零样本声音克隆、情感音色分离控制、多模态情感输入功能。
在线运行:https://go.hyper.ai/idJAy
效果展示
💡我们还建立了 Stable Diffusion 教程交流群,欢迎小伙伴们扫码备注【SD教程】,入群探讨各类技术问题、分享应用效果~

本周论文推荐
1. RPG: A Repository Planning Graph for Unified and Scalable Codebase Generation
本文提出代码库规划图(RPG),通过将能力、文件结构、数据流和函数等要素统一编码为一张图,实现了方案层与实现层规划的融合。RPG 以明确的蓝图取代模糊的自然语言,支持长周期规划与可扩展的代码库生成。基于 RPG,研究人员还构建了从零开始生成代码库的图驱动框架 ZeroRepo。
论文链接:https://go.hyper.ai/YiE4q
2. Baseer: A Vision-Language Model for Arabic Document-to-Markdown OCR
本文提出了一种专为阿拉伯语文档 OCR 任务进行微调的视觉-语言模型 Baseer,通过结合大量合成文档与真实世界文档的超大规模数据集,该模型采用仅解码器结构的微调策略,在保留预训练 MLLM 通用视觉特征的同时,对模型进行针对性适配。
论文链接:https://go.hyper.ai/nBqaV
3. Qwen3-Omni Technical Report
本文提出多模态模型 Qwen3-Omni,首次在文本、图像、音频和视频四种模态上均实现了当前最先进的性能。在相同参数规模下,该模型性能与 Qwen 系列中的单模态模型相当,并在音频任务上表现尤为突出。
论文链接:https://go.hyper.ai/uC2kn
4. LIMI: Less is More for Agency
本文通过提出 LIMI(Less Is More for Intelligent Agency)证明,智能体性的演进遵循截然不同的发展规律。通过聚焦协作式软件开发与科学研究工作流等关键场景,研究人员发现:仅需少量但经过战略性筛选的自主行为示范,即可催生出高度复杂的智能体智能。
论文链接:https://go.hyper.ai/rjakg
5. OmniInsert: Mask-Free Video Insertion of Any Reference via Diffusion Transformer Models
本文进一步开发了 OmniInsert,一种面向单主体或多主体参考的统一无掩码视频插入框架。具体而言,为保持主体与场景之间的平衡,研究人员引入了一种简单而有效的条件特异性特征注入机制,能够清晰地区分并注入多源条件信息;同时提出一种新颖的渐进式训练策略,使模型能够有效平衡来自主体和源视频的特征注入。
论文链接:https://go.hyper.ai/mZRqt
更多 AI 前沿论文:https://go.hyper.ai/iSYSZ
社区文章解读
1. 机器学习vs.动力学模型,Ai2最新研究:仅需2分钟,ACE2可完成一次4个月季节预报
英国埃克塞特哈德利中心气象局、埃克塞特大学以及美国艾伦人工智能研究所(Ai2)共同组成的研究团队,对此前开发的机器学习天气模型 ACE2 进行了评估,并将其与主流基于物理的海气耦合集合预报系统 GloSea 进行对比。研究首次证明,机器学习天气模型能够生成具备高技巧的全球季节预测,为深化理解短期气候变异机制、发展新一代预报技术并推动业务预报进步,提供了新的可能方向。
查看完整报道:https://go.hyper.ai/n4eIp
2. 在线教程丨41个案例中的生成成功率达100%,RFdiffusion2 基于化学反应实现原子级别蛋白质生成
华盛顿大学蛋白质设计研究所发布了全新生成模型 Rosetta Fold diffusion 2(RFdiffusion2),实现了根据简单的化学反应描述,生成具有定制活性位点的蛋白质骨架的优化路径,突破了长期以来在催化剂设计上的技术瓶颈,为包括塑料降解在内的多种应用提供了强有力的技术支撑。
查看完整报道:https://go.hyper.ai/gtlE4
3. Qwen3-Max参数规模超万亿,多项基准测试达SOTA,预告推理增强版本达奥数竞赛满分水平
2025 阿里云栖大会开幕式上,Qwen3-Max 正式亮相,这个号称是其迄今为止规模最大、能力最强的模型,以 1T 的模型总参数横扫多项评测基准。除此之外,此次会议还介绍了 Qwen3-VL、Qwen3-Coder 等模型。
查看完整报道:https://go.hyper.ai/odH8O
4. 香港科技大学提出融合神经网络框架,高效预测蛋白质序列的多金属结合位点
香港科技大学的研究团队提出了一个融合神经网络框架,用于预测蛋白质序列中的多金属结合位点。该框架采用由 CNN 与融合网络组成的两阶段架构,能够实现快速、稳健、高质量的整体预测,加速了金属-蛋白质相互作用的更多可能性挖掘。
查看完整报道:https://go.hyper.ai/ChgtK
5. 英伟达提出ReaSyn,借鉴思维链类比分子合成,实现超高重建率与路径多样性
英伟达研究团队推出融合推理能力的高效可合成分子投影框架 ReaSyn,采用反应链表示法,将合成路径视为 LLM 的 CoT 推理路径,为破解分子合成的现实难题开辟了新路径。它借鉴大型语言模型中的 「思维链推理」 思想,从技术底层为解决可合成分子设计的核心痛点提供了新思路。
查看完整报道:https://go.hyper.ai/B4zY8
热门百科词条精选
1. DALL-E
2. 倒数排序融合 RRF
3. 世界模型 World Models
4. 故障词元 Glitch Token
5. 量子神经网络 Quantum Neural Network
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
https://go.hyper.ai/wiki
10 月截稿顶会
10 月 2 日
8:00:00
VLDB 2026
10 月 3 日
19:59:59
EUROCRYPT 2026
10 月 8 日
19:59:59
WWW 2026
10 月 11 日
19:59:59
OOPSLA 2026
10 月 18 日
19:59:59
SIGMOD 2026
10 月 28 日
19:59:59
ICDE 2026
一站式追踪人工智能学术顶会:https://go.hyper.ai/event

以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!
关于 HyperAI超神经 (hyper.ai)
HyperAI超神经 (hyper.ai) 是国内领先的人工智能及高性能计算社区,致力于成为国内数据科学领域的基础设施,为国内开发者提供丰富、优质的公共资源,截至目前已经:
* 为 1800+ 公开数据集提供国内加速下载节点
* 收录 600+ 经典及流行在线教程
* 解读 200+ AI4Science 论文案例
* 支持 600+ 相关词条查询
* 托管国内首个完整的 Apache TVM 中文文档
访问官网开启学习之旅:
https://hyper.ai/






戳“阅读原文”,免费获取海量数据集资源!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢