
在本研究中,作者引入了一个用于视觉定位的密度特征网络(DenserNet)。 作者的工作有三个主要贡献。
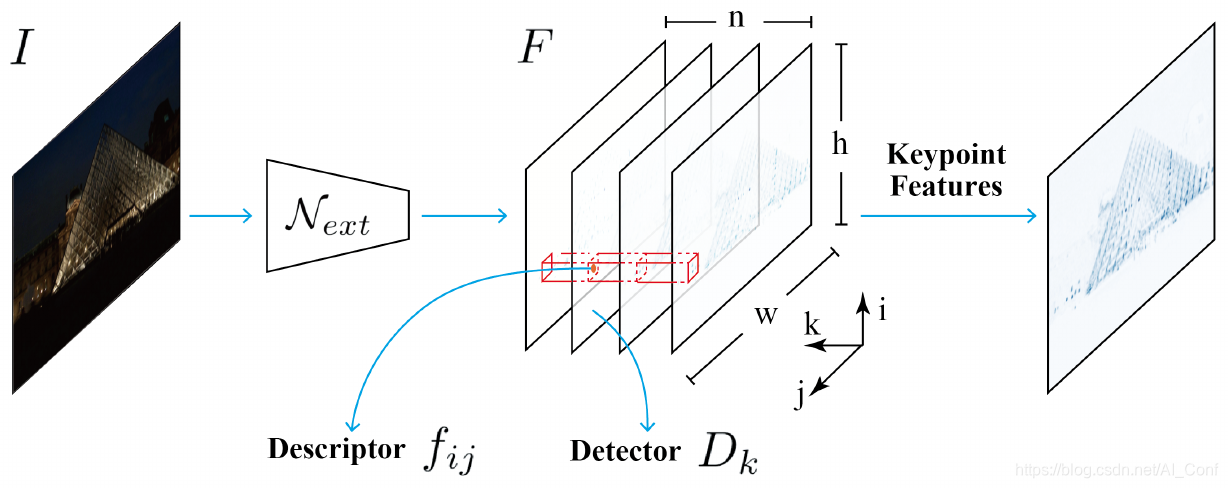
首先,作者开发了一种卷积神经网络(CNN)架构,它在不同语义层次上聚合feature map,用于图像表示。使用更密集的feature map,作者的方法可以产生更多的关键点特征,提高图像检索精度。其次,作者的模型是在没有像素级标注的情况下进行端到端训练的,除了正负GPS标记的图像对。作者使用弱监督的三重排序损失来学习判别性特征,并鼓励关键点特征重复性的图像表示。最后,由于作者的架构在计算过程中具有共享的特征和参数,因此该方法在计算上是高效的。作者的方法可以在具有挑战性的条件下进行精确的大规模定位,同时保持计算约束。
广泛的实验结果表明,作者的方法在4个具有挑战性的大规模定位基准和3个图像检索基准上达到了新的水平。
论文链接:https://www.aminer.cn/pub/5fcdf89491e01124d5ec3e4e?conf=aaai2021
会议链接:https://www.aminer.cn/conf/aaai2021



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢