
【论文名称】VILIO: STATE-OF-THE-ART VISIO-LINGUISTIC MODELS APPLIED TO HATEFUL MEMES 【作者团队】Niklas Muennighoff 【发表时间】2020/12/14 【文章链接】https://arxiv.org/pdf/2012.07788v1.pdf
【推荐理由】 恶意图文(HATEFUL MEMES,又译迷因或模因),是一种基于宗教或种族等特征的、用于贬低他人的文字和图像组合。本文为了提高深度模型「检测」恶意图文的能力,提出了一种视觉语义模型VILIO。 文章的主要贡献包含:1)根据多种视觉语义模型封装了统一的代码库;2)封装好的代码库可以增强现有的视觉语义模型性能;3)在“Hateful Memes Dataset ”上评估了不同模型,并为该数据集提供了未来研究的必要代码。
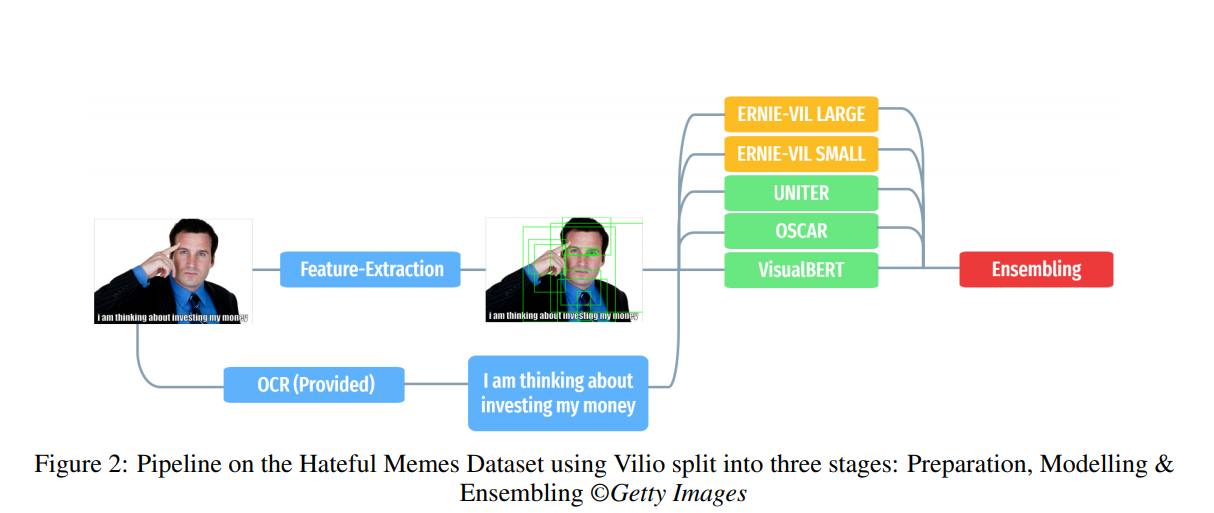
VILIO结构示意图如图1所示,包含三部分:准备;模型和嵌入。在准备部分中提取图像的特征,再将特征输入到模型中。模型中包含: ERNIE-ViL; UNITER ; OSCAR和VisualBERT四部分, ERNIE-ViL负责提取特征和在原始的真值标签中进行预训练,UNITER&OSCAR用以反映transformers library中的变量变化情况,同时,OSCAR还使用图像-文本匹配(ITM)和屏蔽语言建模(MLM)在恶意图文上进行特定于任务的预训练。VisualBERT与OSCAR类似也使用MLM进行特定任务的预训练。在嵌入部分,对于每个模型提取的特征进行平均处理,然后将结果输入到集成回路中应用简单平均,等级平均,功率平均和单纯形优化生成最终结果。 VILIO在使用5种视觉语义模型集成的情况下,获得了“the Hateful Memes Challenge”大赛的第二名。目前,VILIO已经封装在统一的代码库中,以此为恶意图文检测相关任务提供支持。
内容中包含的图片若涉及版权问题,请及时与我们联系删除
评论列表
沙发等你来抢

评论
沙发等你来抢