

人类通过整合多种感知模态来理解世界,这使得人类能够感知、推理和想象动态的物理过程。受此能力的启发,多模态基础模型 (MFM)应运而生,成为多模态理解和生成的强大工具。然而,如今的 MFM 尚不足以成为有效的世界模型。它们缺乏执行反事实推理、模拟动态、理解时空信息、控制生成的视觉结果以及执行多方面推理等基本能力。
本论文探讨了如何弥合多模态基础模型 (MFM) 与世界模型之间的差距。我们首先通过判别性任务提升多模态基础模型 (MFM) 的推理能力,并赋予其结构化推理技能,例如因果推理、反事实思维和时空推理,使其能够超越表面关联,理解视觉和文本数据中更深层次的关系。接下来,我们探索多模态基础模型在图像和视频模态中的生成能力,并引入新的结构化可控生成框架。我们的方法结合了场景图、多模态条件反射和多模态对齐策略来指导生成过程,确保与高级语义和细粒度用户意图的一致性。我们进一步将这些技术扩展到可控的四维生成,从而实现跨时间和空间的交互式、可编辑和可变形的对象合成。为了全面评估这一方向的进展以及世界模型的最终目标,我们引入了 MMWorld 基准,用于评估多学科和多方面推理任务中的多模态基础模型。
总而言之,本论文旨在超越静态感知,构建能够在结构丰富的环境中进行想象、推理和行动的智能系统。通过推动多模态基础模型更接近世界模型,本研究朝着构建不仅能够观察和描述世界,而且能够像人类一样进行推理、模拟和与世界互动的模型迈出了一步。

论文题目:Bridging the Gap Between Multimodal Foundation Models and World Models
作者:Xuehai He
类型:2025年博士论文
学校:University of California, Santa Cruz(美国加州大学圣克鲁兹分校)
下载:
链接: https://pan.baidu.com/s/1-cymPIjPHWNas9ki_w_k8A?pwd=6t4x
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
引言
人类通过多种感官模态感知和理解世界,包括视觉、听觉和触觉。受人类认知多模态特性的启发,多模态基础模型应运而生,成为模拟、理解和生成物理世界表征的基础工具[363,13, 247]。本论文主要旨在回答以下问题:如何弥合多模态基础模型 (MFM) 与世界模型之间的差距?
虽然当前的多模态模型在众多任务中展现出令人印象深刻的性能[363, 420, 247],但它们往往在核心世界建模能力方面存在不足,例如反事实推理[137]、因果和时间推理[228]、基于观测估计的世界缺失状态、对环境的时空感知以及对世界演变的动态理解。这些缺陷限制了它们以类似人类的方式模拟、规划和与世界互动的能力。为此,本博士论文首先提出了将各种推理能力注入多模态基础模型的新颖方法。这包括赋予多模态模型反事实思维能力,使其能够提出“假设”问题、推断因果关系以及对时空动态进行推理。
然后,我们转向世界建模的生成方面,其中 MFM不仅应该模拟世界的样子,还应该模拟它如何变化。除了生成视觉逼真的内容之外,我们还提出了新的结构化和可控生成机制。这包括多模态受控图像生成[159]、运动调节视频生成[153],以及从文本生成可交互、可控且可编辑的 4D 场景。
为了系统全面地评估这一方向的进展,我们引入了新的基准和评估协议,强调推理、可控性和多学科理解。其中一项贡献是MMWorld 基准 [150],旨在从不同维度评估世界模型,例如时间理解、多模态对齐以及跨领域和概念的泛化能力。我们的评估框架允许进行标准化比较,并促进通用、具有推理能力的多模态系统的开发。
总体而言,在本论文中,我们首先研究多模态基础模型如何有效地感知和理解世界,尤其关注需要因果推理、结构推理和反事实思维能力的判别性任务。其次,我们探索其生成能力,以模拟现实场景并生成反映世界复杂性的新内容。最后,为了最终实现创建有效的世界模型的目标,我们引入了专门从这些角度评估多模态基础模型的基准。
本论文分为两部分:
1.1 第一部分:判别性世界建模(感知与推理)
本文第一部分重点关注提升多模态基础模型的感知和推理能力。
• 第二章提出了将基础模型应用于感知任务的技术。我们介绍了基于子空间的训练策略,并分析了不同适应方法对多模态基础模型(尤其是视觉-语言模型)的归纳偏差。
• 第三章通过一种新的即时学习范式,将反事实思维融入多模态模型。这种方法使模型能够推理可能发生的事情,而不仅仅是现在发生的事情,从而提高了模型对未知或模糊输入的鲁棒性[156]。
• 第四章通过将视觉和语言结构与因果关系相结合,增强了多模态基础模型的组合推理能力。我们表明,整合因果关系有助于模型推广到已知概念的新组合,并提高其在结构化推理任务中的表现。
• 第五章探讨了生成模型在感知领域的应用[149],尤其是基于扩散的模型。我们展示了如何将扩散模型应用于判别性任务,并提出了一种利用生成先验加速零样本分类的机制。
• 第六章介绍了一个基于图的多模态生成框架[154]。我们设计了一个多模态图变换器,它以结构化场景图和其他符号表示作为生成条件,从而增强了组合保真度和关系保真度。
• 第七章介绍了MMWorld,这是一个多模态世界模型的基准测试和评估套件[150]。它涵盖了感知、推理和生成的任务,涵盖了不同的领域和时间尺度,最重要的是,涵盖了不同的学科。该基准测试包含新的评估指标,以及广泛的任务分类,从而能够对多模态模型进行标准化比较。
• 第 八 章介绍了 VLM4D [584],这是一个用于评估多模态世界模型中时空感知能力的基准测试和评估套件 [150]。我们还介绍了未来提升世界模型中时空感知能力的解决方案。
1.2 第二部分:生成式世界模型
论文的第二部分从感知转向生成,重点关注可控和交互式生成。
• 第 九 章探讨了可控的文本到图像生成。我们开发了一个灵活的框架,允许用户通过提示、草图、深度图和其他多种模态来指导生成,从而支持对图像生成的多模态控制 [159]。
• 第 十 章将可控性扩展到视频领域。我们提出了 Mojito,一个具有可控运动动力学的文本到视频生成框架,并展示了如何在不重新训练主干模型的情况下操纵运动强度和方向 [153]。 • 第11章介绍了基于Morpho4D的4D生成技术,该技术能够合成可交互、可控制且可编辑的4D场景,并使其随时间推移。这能够更丰富地模拟物理世界,为4D生成建模开辟新的途径。
1.3 结论与未来工作
为了便于将来参考,论文的最后几章(第12章和第13章)总结了核心发现和贡献,并讨论了本论文面临的挑战和未来研究方向。这些挑战包括:扩展到现实世界环境、改进长视域推理能力以及开发交互式、具身化的多模态智能体。
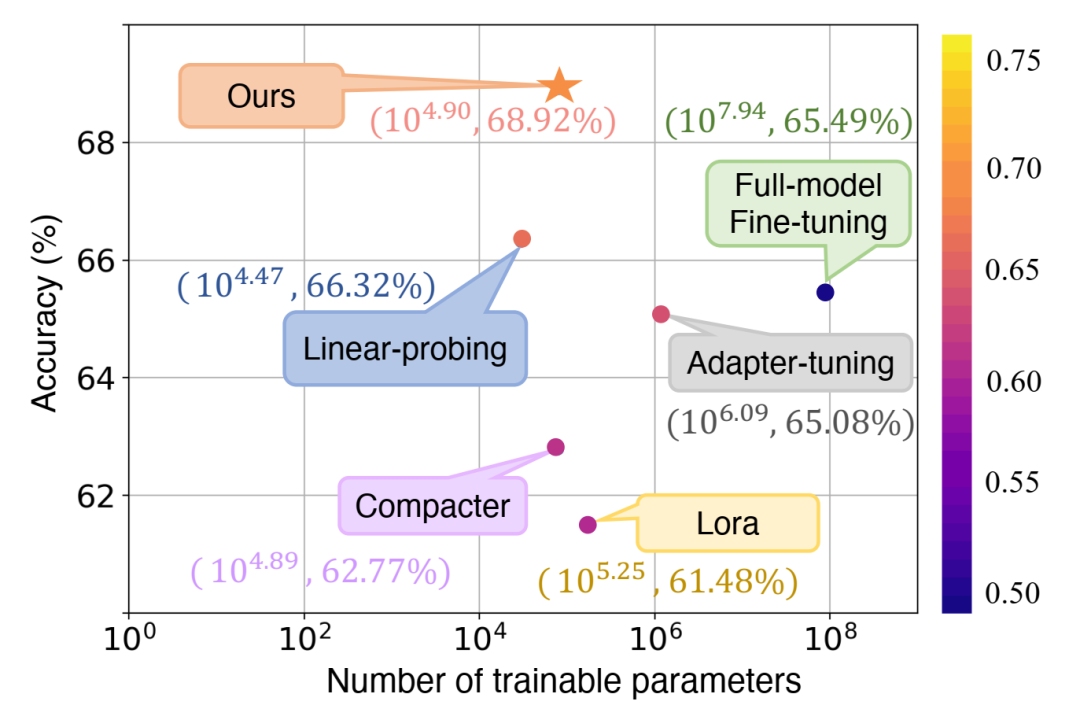
使用 Vision Transformer (ViT-B-224/32)通过 CLIP 预训练,在 20 个图像分类数据集的平均值上测量结果。我们的方法位于左上角,并在准确率和参数效率之间实现了最佳平衡。点和数字的颜色表示性能效率 (PE) 指标(越高越好)。
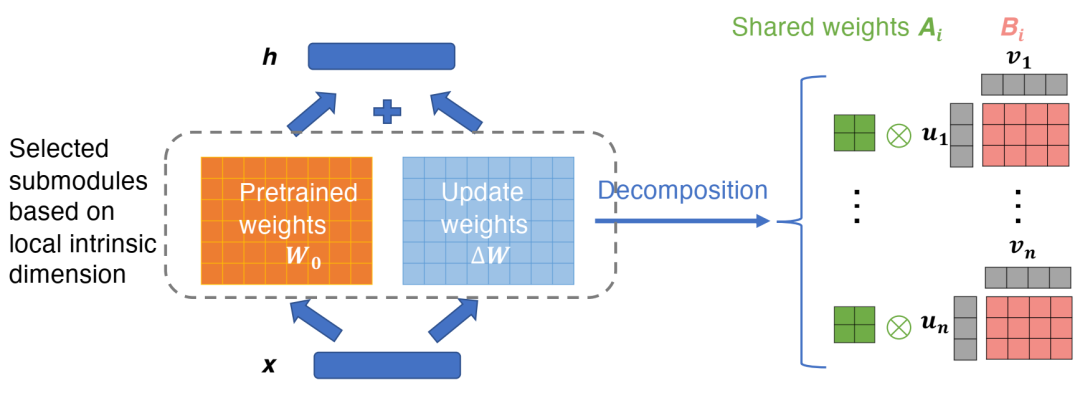
Ai 表示共享权重矩阵,i ∈ {1, ..., n}。Bi分解为两个低秩矩阵 ui 和 vi。h 是所选ViT 子模块的输出。x 是子模块的输入。在模型自适应过程中,只有矩阵 Ai、ui 和 vi 接收梯度,以提高参数效率。

反事实提示学习的概念概述。CPL 通过识别导致提示变化的非虚假特征变化来构建反事实。在本例中,“谷仓”特征是提示 A 和 B 之间的根本原因。
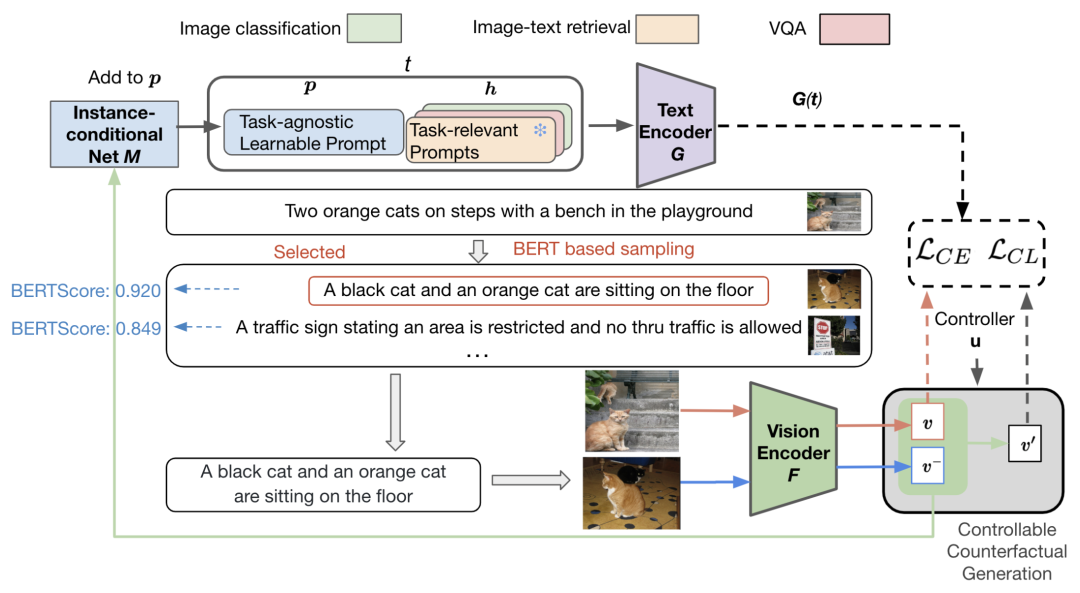
反事实提示学习框架。我们冻结视觉编码器 F 和文本编码器 G,仅优化与任务无关的提示和实例条件网络 M(蓝色块)。有关说明,请参阅第 3.2.2 节。
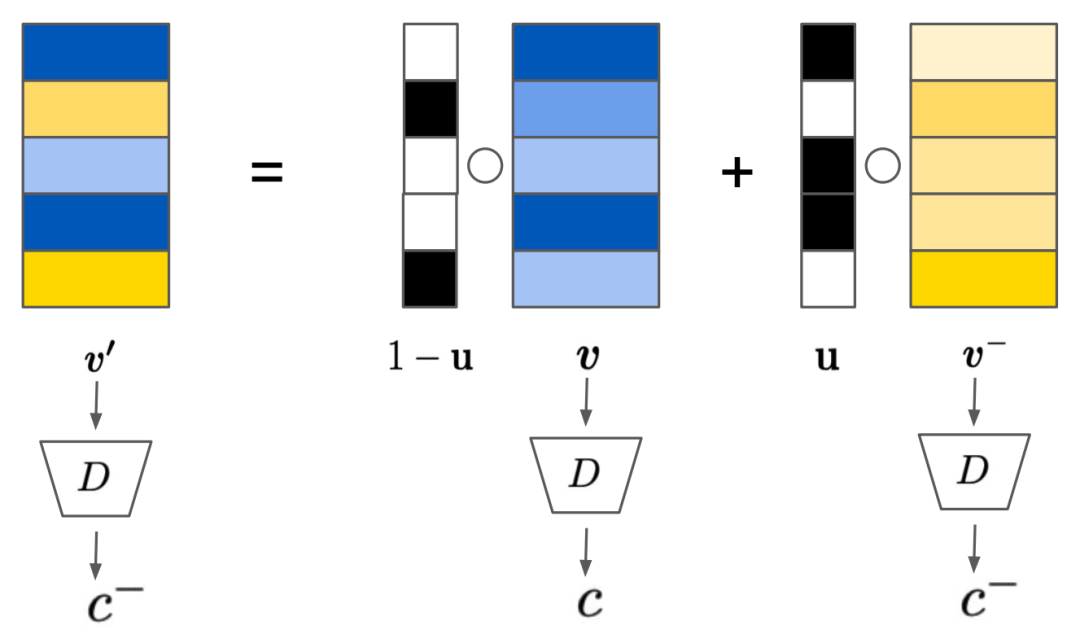
反事实生成过程。v 和 c 分别为正图像特征和标签,v− 和 c− 分别为负图像特征和标签。◦ 是元素乘法。通过混合 v 和 v−,判别器 D 将反事实图像特征 v′ 预测为负标签 c−。u 被最小化,因此,这里捕获了对正图像特征 u 的最小变化,从而导致标签发生因果变化。

组合式图像-文本匹配问题的示例,其中正例图像和负例图像除了主语、谓语/动词或宾语之外,语义非常相似。CLIP 错误地将文本提示与右侧的错误图像(与负例图像的相似度得分较高)连接起来,而我们的 ComCLIP 模型可以更有效地进行组合式匹配。
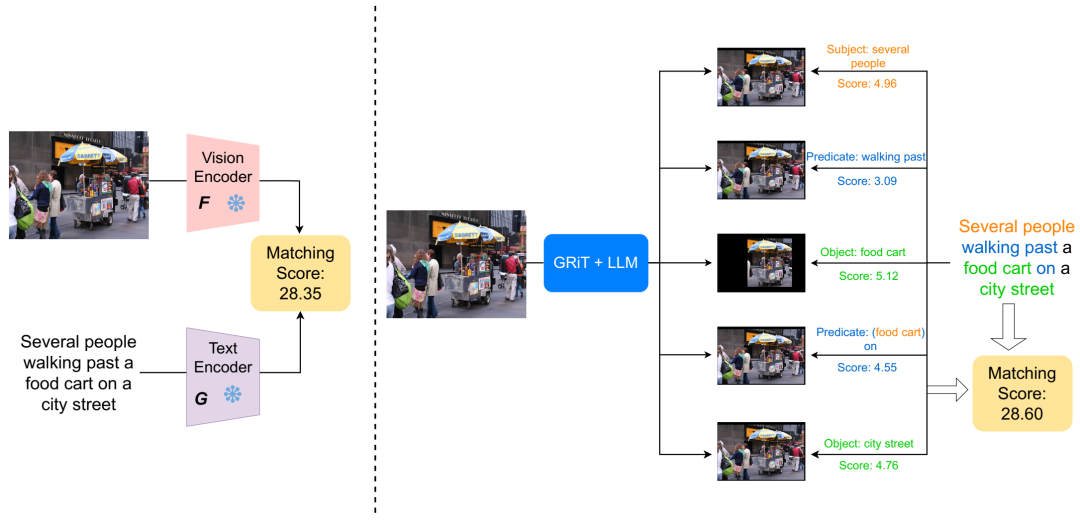
以 CLIP 为骨干的 ComCLIP 框架概览。我们使用 GRiT [474] 和大型语言模型 (LLM) 来解析输入图像,并分别遵循对宾语、主语和谓语进行编码的规则。图中展示了涉及多个主语/宾语/谓语的情况,(这是来自 Flickr30K 的一个正例)。
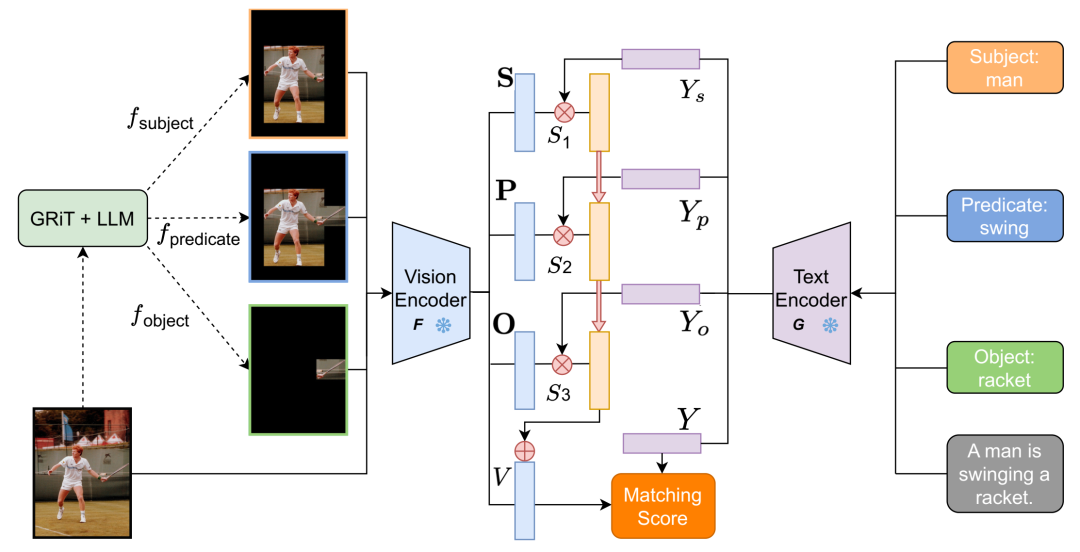
以 CLIP 为骨干的 ComCLIP 框架概述。我们使用三种独立的编码机制,分别遵循对象、主语和谓语的编码规则,对输入图像进行解耦。实体信息被引入到整幅图像的全局嵌入中。CLIP 的模块组件(视觉编码器 F(·)、文本编码器 G(·))始终处于冻结状态。在实现过程中,匹配和计算分数的过程始于将输入图像处理成对象、主语和谓语子图像。然后将原始句子和图像以及解析后的单词和子图像输入到 CLIP 文本和视觉编码器中。随后,计算每对子图像和单词嵌入的余弦相似度分数。这些分数随后经过 Softmax 层处理,得到三个正权重。下一步是将重新加权的子图像嵌入添加到原始图像的嵌入中。最后,通过比较聚合图像嵌入和全局文本嵌入,得出最终的匹配分数。整个框架无需训练。
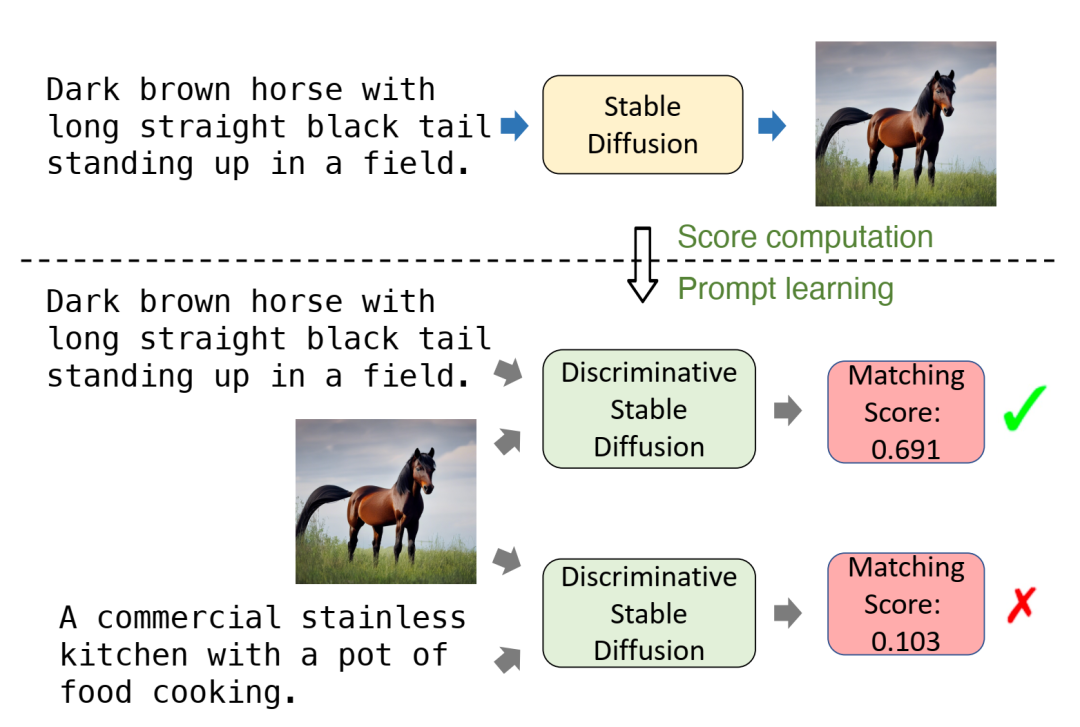
预告图中的上部子图展示了稳定扩散 (Stable Diffusion) 在给定文本提示的情况下生成逼真图像的能力。下部子图展示了我们提出的方法——判别式稳定扩散 (Discffusion) 的流程,该方法利用稳定扩散进行图文匹配。Discffusion 可以针对给定的文本提示和图像输出匹配分数,分数越高表示匹配度越高。
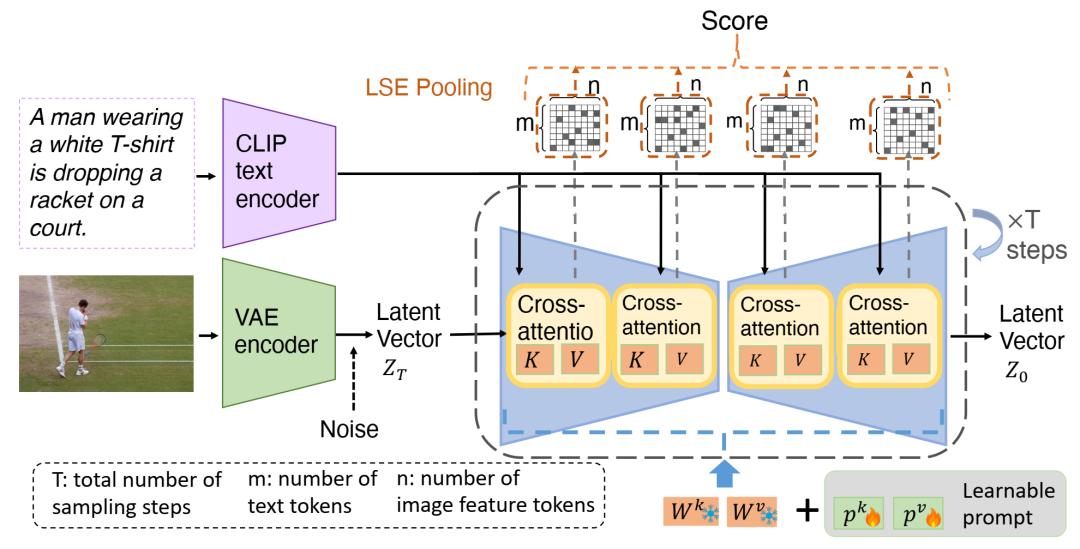
我们的判别式稳定扩散框架概述,该框架衡量给定图像和文本的匹配程度,并利用了稳定扩散中的交叉注意力机制。判别式稳定扩散在注意力矩阵(红色框)上添加了可学习的提示。可学习的提示将在训练过程中接收梯度并进行更新,而预训练权重则保持不变。为了简化起见,m 和 n 中的层索引被删除。
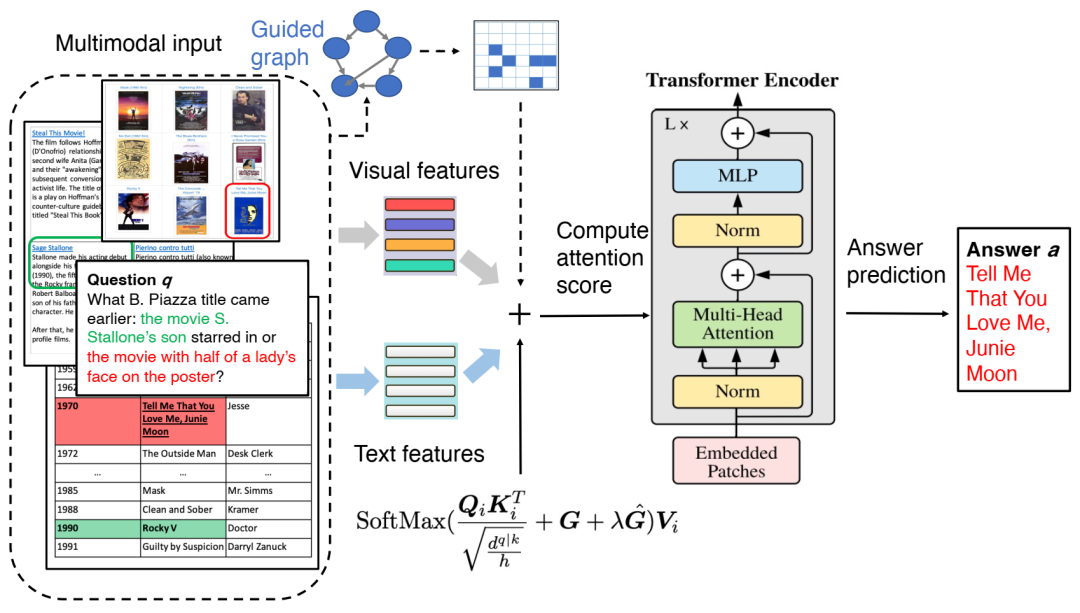
多模态图 Transformer 概述。它以视觉特征、文本特征及其对应的生成图作为输入。生成的图首先转换为邻接矩阵,以导出掩码矩阵 G。Transformer 中计算修改后的准注意力得分,以推断答案。公式中,G 是通过连接视觉端和语言端的邻接矩阵而构建的图导出矩阵。Gˆ 是可训练偏差。不同模态的输入特征与图信息融合,以执行下游推理。
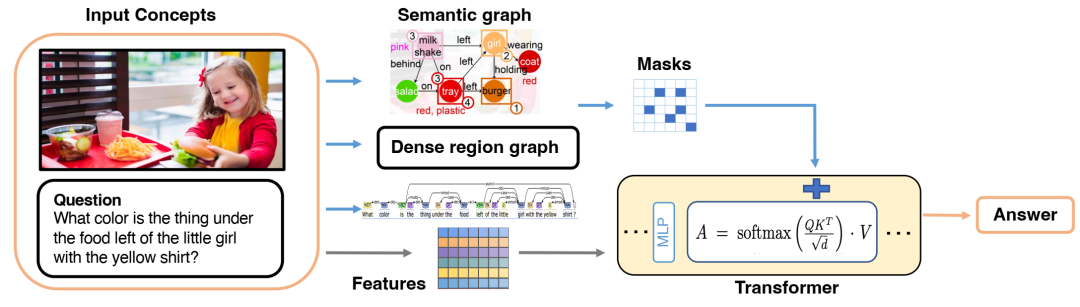
图中展示了我们多模态图变换器(Multimodal Graph Transformer)的整体框架。不同模态的输入经过处理并变换为相应的图,这些图随后被转换为掩码(mask),并与其特征相结合,最终输入到变换器中进行下游推理。具体来说,语义图是通过场景图生成方法创建的,稠密区域图被提取为稠密连接图,文本图则通过解析生成。
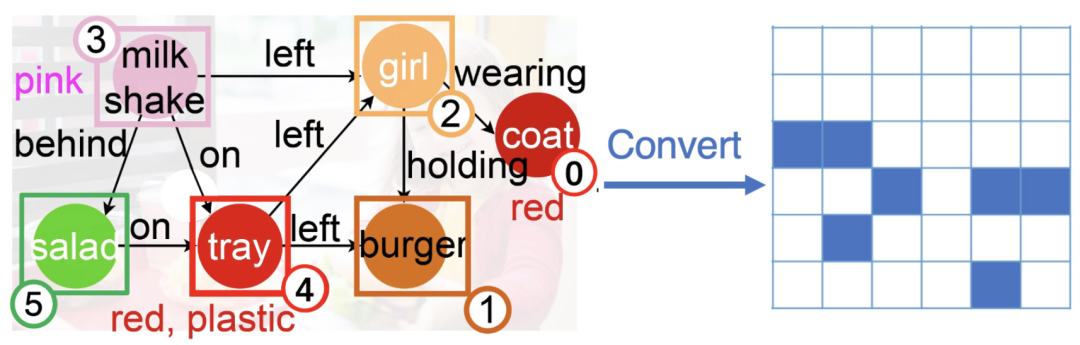
将语义图转换为邻接矩阵的简单演示。蓝色单元格表示图矩阵中该元素的值为“0”,而白色单元格表示“-inf”。我们在计算准注意力机制时,将矩阵用作掩码。
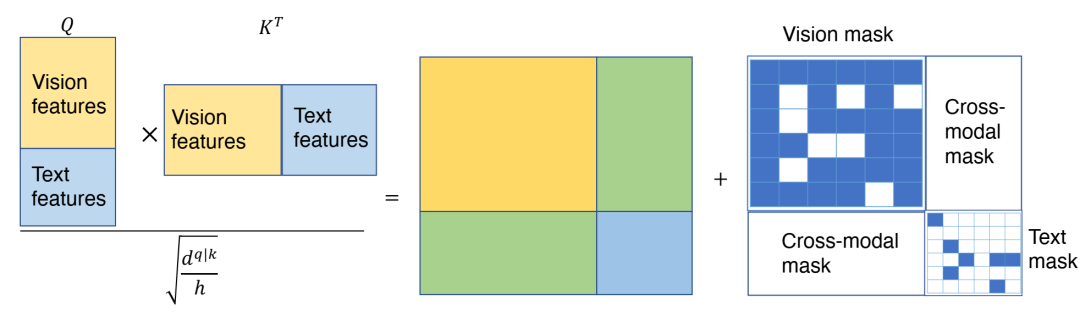
当输入来自两种模态时,在计算准注意力时添加图诱导掩码的简单演示。视觉掩码是从密集区域图转换而来的,文本掩码是从文本图转换而来的。跨模态掩码始终设置为全零矩阵,用于鼓励模型学习图像特征和文本特征之间的交叉注意力,从而促进它们之间的对齐。
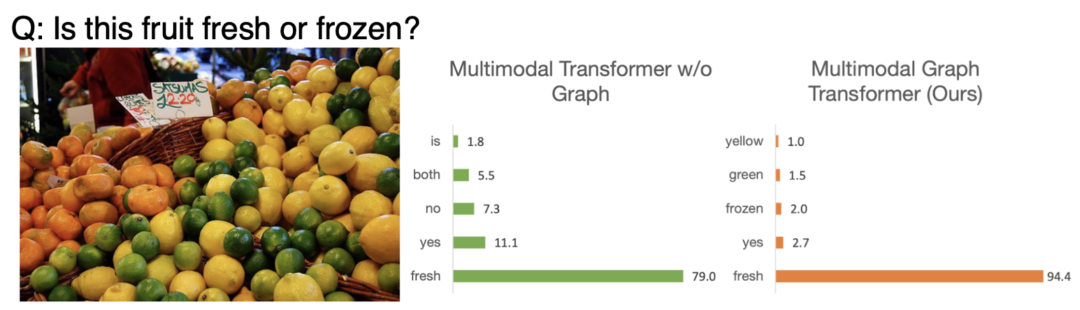
与 VQA v2 的定性比较。fresh 是基本事实。来自多模态图变换器(我们的)的预测与输入图像的内容更相关,并且获得了比基本事实更高的置信度分数。
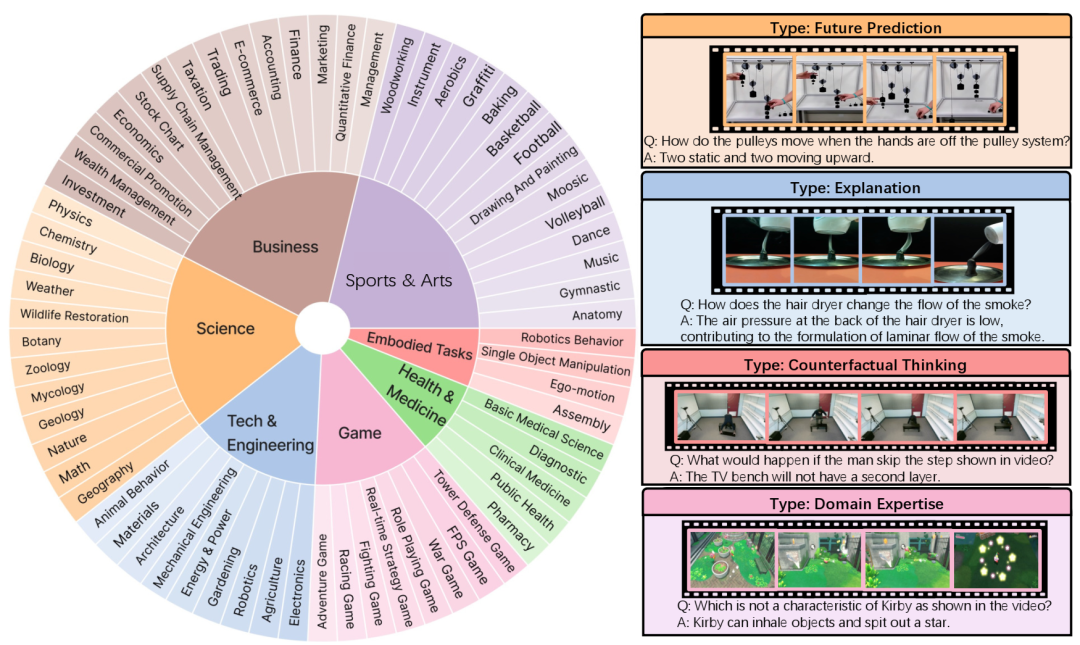
MMWorld 涵盖七大学科和 69 个子学科,专注于评估超越感知的多层面推理能力(例如,解释、反事实思维、未来预测、领域专业知识)。右侧是来自科学、技术与工程、具身任务和游戏学科的四个视频样本。
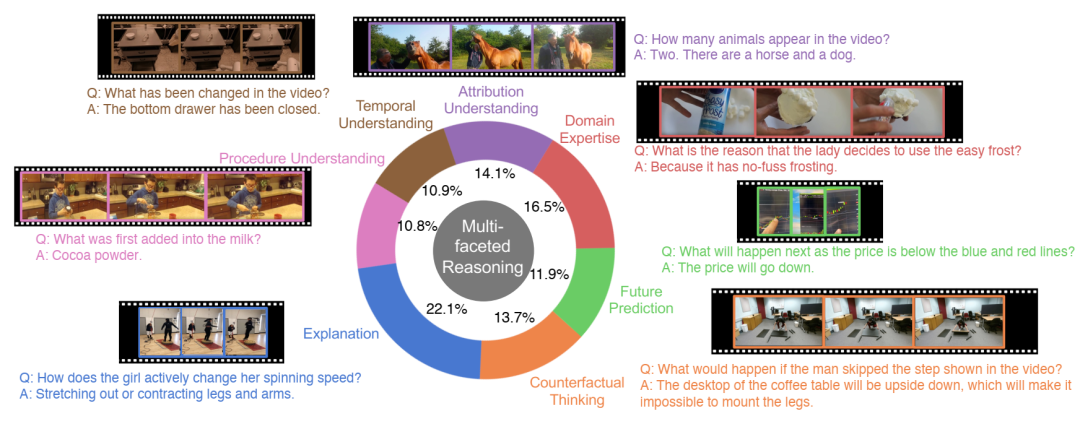
MMWorld 中的问题旨在评估模型的七种主要理解和推理能力。每个问题都标注了所有相关类别。图中展示了每个推理类别的一个示例问题,并基于其主要类别。
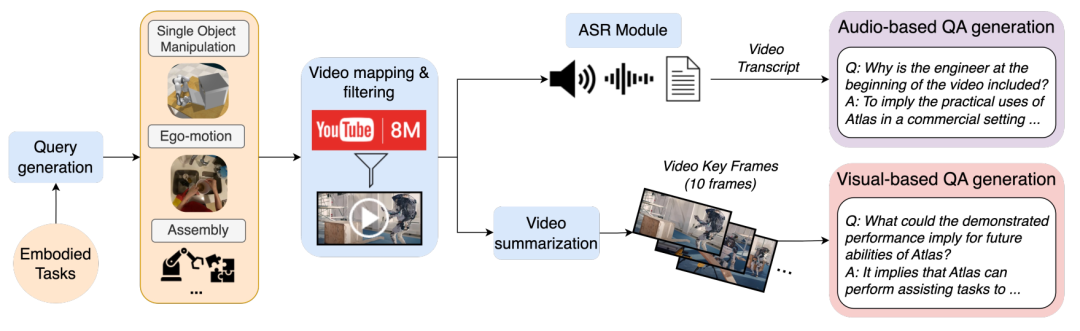
MMWorld 中合成数据生成流程的示意图。首先生成特定子学科的查询,然后从 YouTube-8M [2] 和 YouTube 检索视频。提取关键帧用于基于视觉的问答生成,并使用 ASR 模块转录视频用于基于音频的问答生成。

数据集生成和注释流程。我们的数据集是通过收集真实视频并生成合成数据构建的,然后进行人工参与的质量审核,以解决视频和注释中的模糊问题。在进行时间对齐和质量保证之后,创建了人工注释的问题和答案,并辅以由大型语言模型 (LLM) 生成的多项选择题。最终数据集包含真实视频数据和合成视频数据,并采用全面的 VLM 评分指标。
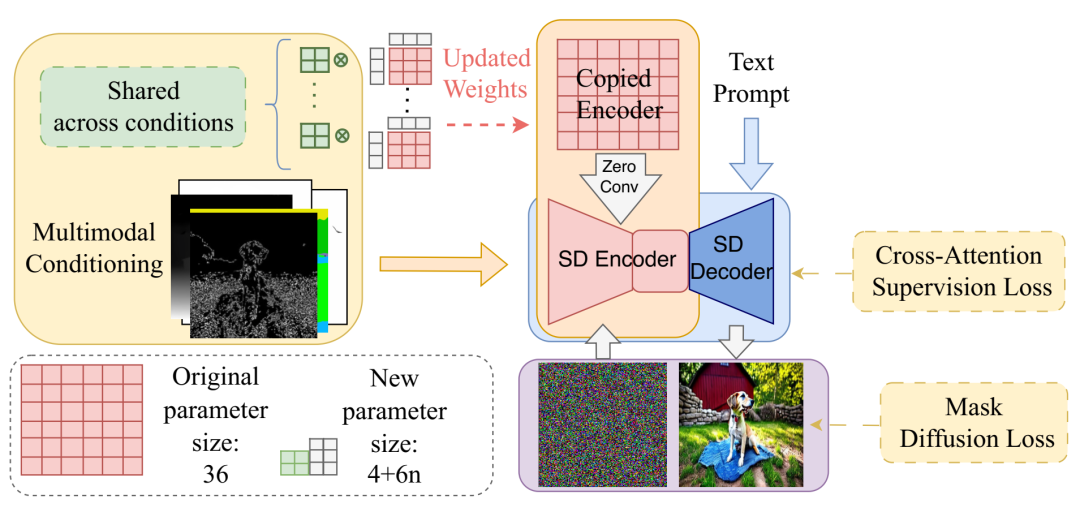
FlexEControl 概述:分解后的绿色矩阵在不同的输入条件下共享,这显著提升了模型的效率,并保留了图像内容。在训练过程中,我们集成了两个专门的损失函数,以实现灵活的控制并巧妙地处理冲突条件。在此处所示的示例中,新的参数大小被有效地压缩为4 + 6n,其中 n 表示分解矩阵对的数量。
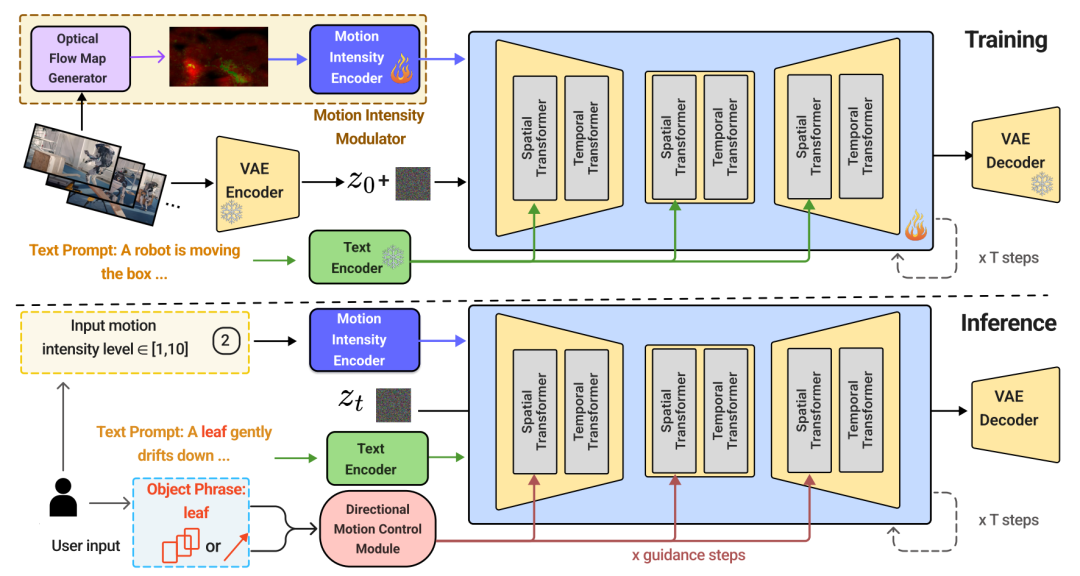
Mojito 框架概览。在训练流程(顶部)中,Mojito 使用 VAE 编码器将输入帧转换为潜在特征,并由 U-Net 中的空间和时间变换器进行处理。运动强度控制通过运动强度调制器引入,该调制器由光流图生成器和运动强度编码器组成。方向性运动控制模块会解读提示中的物体短语,使注意力与指定的轨迹保持一致。在推理过程中(底部),Mojito 会根据用户定义的运动强度和方向性引导生成视频。
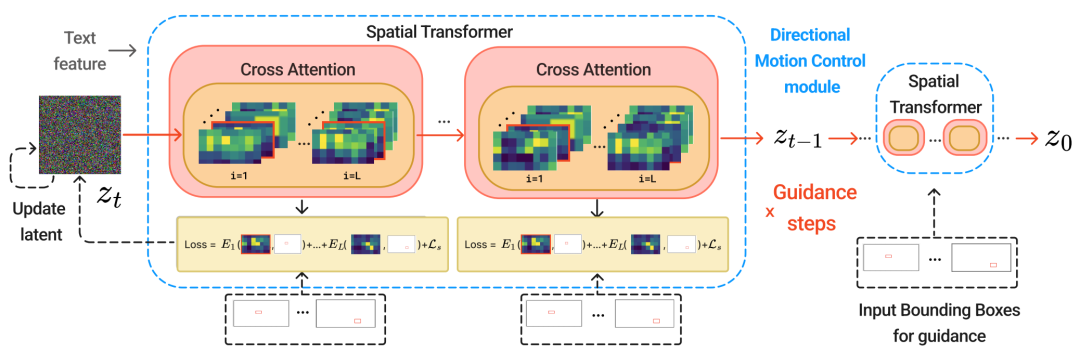
定向运动控制模块概览。给定引导步骤中所选单词标记的交叉注意力图以红色边框标记。我们计算能量函数,并在推理过程中执行反向传播以更新潜在向量。
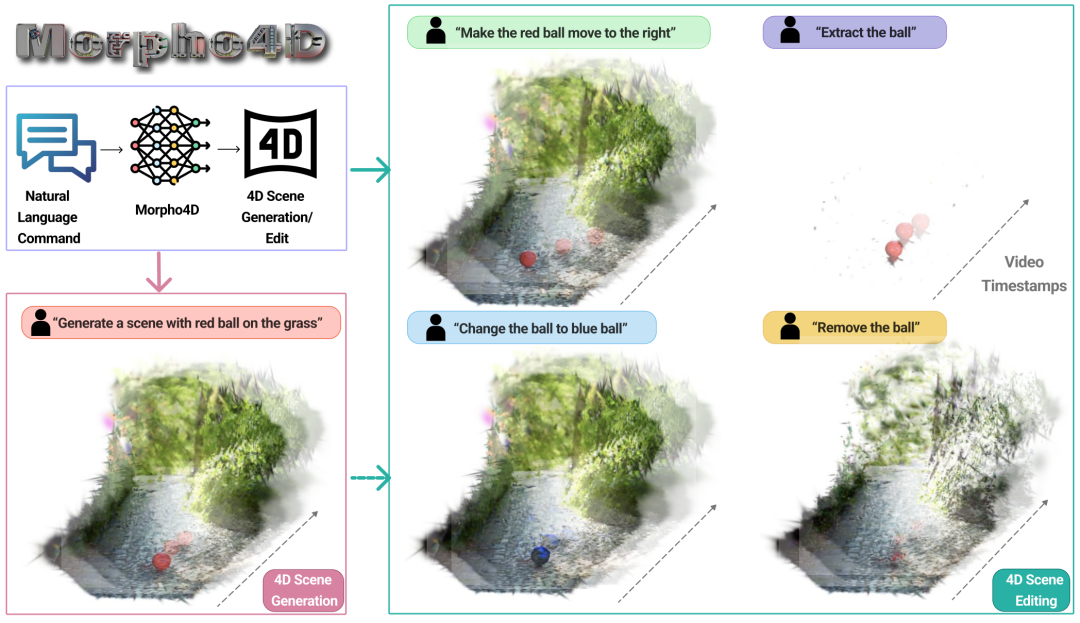
Morph4D 是一款完全由自然语言驱动的 4D 场景生成引擎,能够基于语言命令生成和编辑 4D 场景。Morph4D 能够根据自然语言输入构建 4D 场景,并为多项任务提供统一的框架,包括高质量场景生成、对象运动和外观的交互式修改以及对象提取或移除。
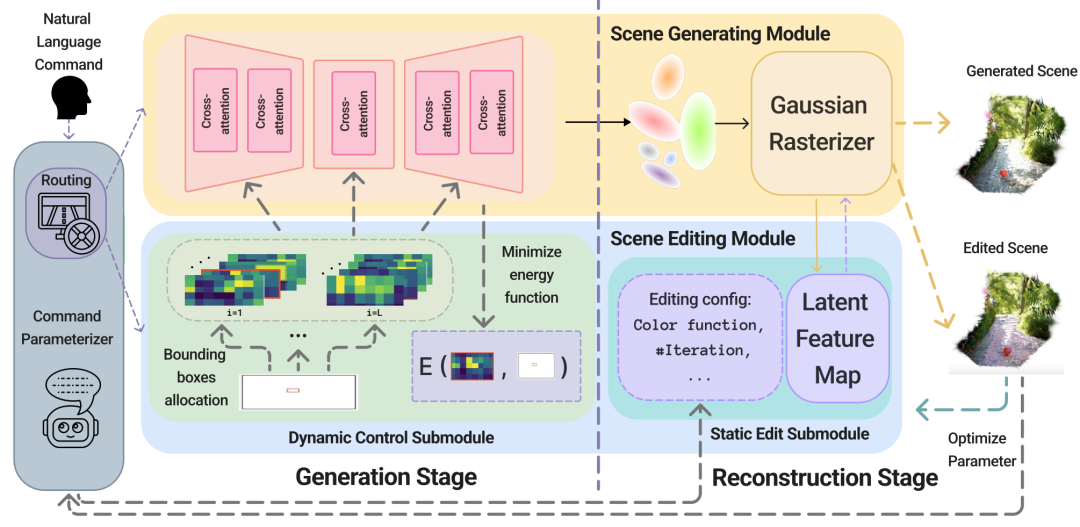
Morpho4D 流程概述。它由一个用于自然语言理解的命令参数化器、一个可控的场景生成模块(支持根据动态物体运动引导生成 4D 场景)以及一个用于执行编辑的交互式场景编辑模块组成。











内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢