

医药情报知识库是当前药企在AI智能化落地中的第一站。为什么药企要建立自己的医药情报知识库呢?现在已有的数据库无法使用吗?核心原因有以下三点:
数据不全:无论是全球TOP0的数据库,还是多么贵的数据库。都无法逃避数据确实的问题。毕竟每家数据库来源不同、供应商不同,总之对于药企这种在专业赛道深耕多年的客户来讲,数据不全也是正常现象。例如对于一个靶点领域而言,有专业统计指出全球最全的商业数据库管线覆盖只有40%。再加上很多药企还有自己的一些私有数据,只有自建医药情报知识库才能用好这些私有数据。
数据不深:一个医药商业数据库是面向所有药企的,那对某个特定领域的疾病自然深不到哪里去。有的药企专供肺癌,对于EGFR-TKI都需要分的很细,不同基因位点的跳突,不同代别的药物疗效差异,不同PD-1 CPS表达的程度,MRD的指证,这些都需要分的细致且深入,一般数据库难以达到。
数据不符合决策逻辑:每个药企决策逻辑不同,那么要看的数据自然也就不同。有的只关注大额的BD交易,有的一个也不会放过。药企分析专利中活性数据维度也不一样,并不一定是活性最高的毒性最小的分子才是PCC。这些判定逻辑应该说都不一样。
所以,由此看来,用的真正实用的医药情报体系还需要自己来建。

药企医药情报知识库的分析
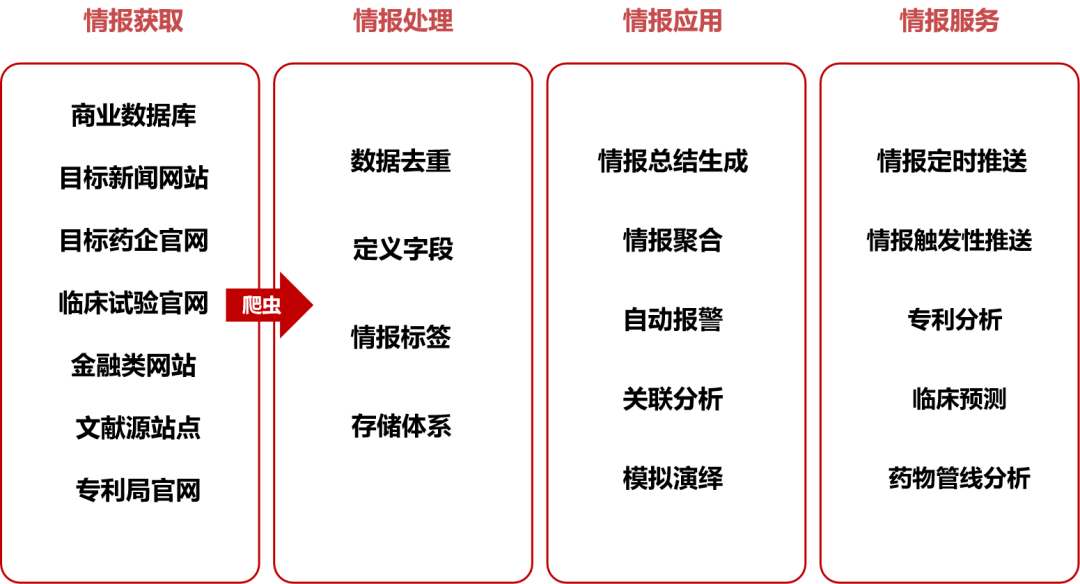
首先我们来看看整体数据处理过程,是从情报获取一直到情报服务4个部分。对于商业数据库有API接口直接应用,也可以导出excel表格转化为XML格式。
对于不同的数据需要分解成哪些重点的字段要素,请看下表(选自《医药大模型》一书中的内容)
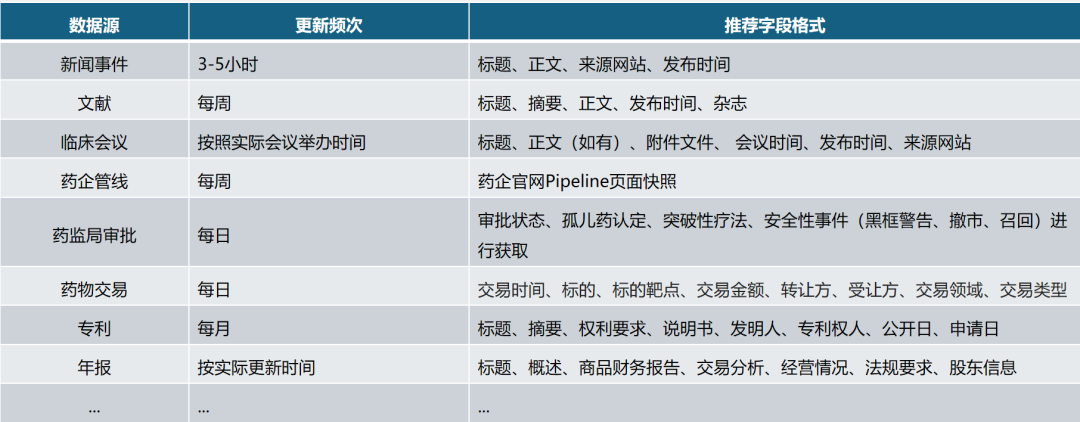
将不同的数据类型总结为上表中的字段,就可以实现情报洞察的生成。
首先可以确定哪些是需要总结和重点监控的情报。例如对于药物交易,标的>5亿美元的需要直接将此信息发邮件给特定员工。对于专利,凡是Pfizer的专利,专利权利要求属于药物分子或序列类型的(如何判定权利要求分类,请找助理询问),需要发邮件给专利部门与研发部门的同事。这些都是需要洞察的情报资料,可以自主进行设计。这些提取过程,都可以使用大语言模型实现。

药企医药情报知识库的建设
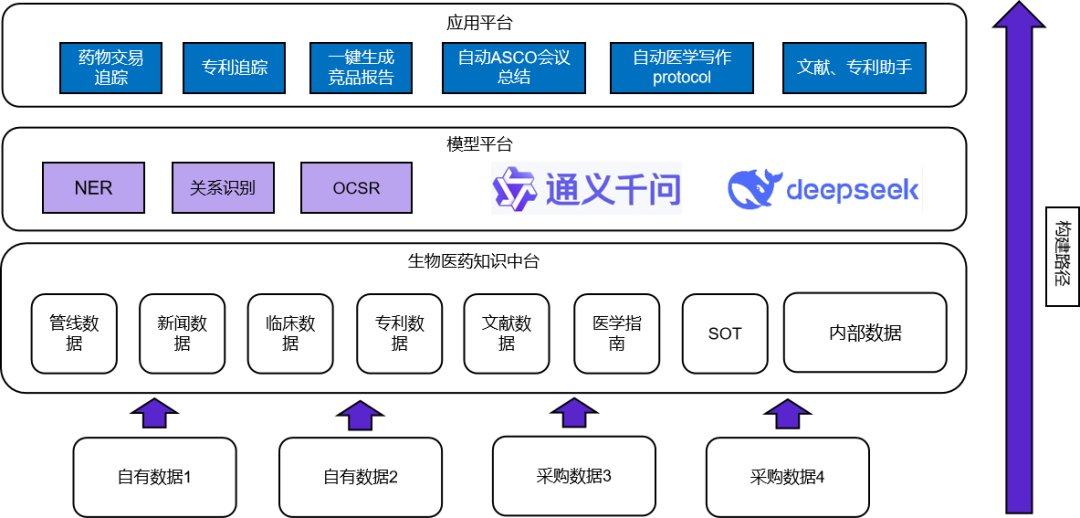
格式统一:对从不同渠道采集到的多样化格式的数据(如 HTML、PDF、纯文本等)进行格式转换和标准化处理,同时提取关键信息,如文献的标题、作者、发表时间等,资讯的标题、发布来源、发布时间等(后续提供全部模版) 。
按照需求的描述变成统一类型的文本,这个都不难理解。但是对各类数据类型统一就需要我们来做解决方案了。比如药企客户要求的如文献的标题、作者、发表时间等,资讯的标题、发布来源、发布时间等。但是新闻、专利、临床如何整理出相应字段呢?这里药企说要给出模版,其实都是需要供应商帮助梳理。这部分我放到解决方案中讲。
自动化分类标签:结合医药行业的专业知识体系,对情报内容按照不同维度进行分类,如按照疾病领域(自免疾病、肿瘤疾病等)。每个药企都有自己需要的分类体系,这种分类是由AI自动完成的。
比如专利的分类,有结构、序列、组合物、晶型、制剂、医药用途、技术平台等。医药新闻的分类,有审批、交易、研发进展、科学发现、专利诉讼、高管变动等。临床的分类,有临床分期、IIT研究、阳性结果、阴性结果、RCT研究、RWS研究等,这类标签从从不同维度是非常多的。
情报聚合:对从不同渠道采集到的情报数据,支持根据同一主体(药企、药物、疾病领域、靶点等)进行信息整合。
自动化洞察生成:结合数据情报分析结果和行业专家经验,智能体自动生成有价值的情报洞察和小结。主要场景有,新闻摘要汇总、靶点报告生成、交易的自动化报告、临床报告、专利报告等。支持每天/周增量更新的情报内容,可自动实现对应场景类型的小结生成。既往的存量情报内容,支持勾选多篇情报内容,选择生成对应场景类型的情报内容。
关于我的图书

关于药番茄科技
青蒿君是药番茄科技的联合创始人,我们一支致力于医药企业数智化解决方案的团队,在医药数据智能与大语言模型应用方面具有多年经验与落地的项目案例。药企AI解决方案,医药竞争格局调研咨询与解决方案业务,欢迎联系助理进一步沟通。欢迎关注药番茄公众号。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢