
近日,全球首个大规模、多任务的在真实物理环境中由真实机器人执行操作任务的基准测试——RoboChallenge重磅推出;通过科学的评估体系构建一个开放、公正、可复现的「真实考场」,克服真实环境下的性能验证、标准化测试条件、公开可访问测试平台等关键挑战,RoboChallenge为视觉语言动作模型(VLAs)在机器人的实际应用提供更加可靠和可比较的评估标准,推动具身智能从「实验室智能」走向「现实世界智能」。据知,RoboChallenge由Dexmal原力灵机联合Hugging Face共同发起。

官网:https://robochallenge.ai
论文:https://robochallenge.ai/robochallenge_techreport.pdf
GitHub:https://github.com/RoboChallenge/RoboChallengeInference
Hugging Face:https://huggingface.co/RoboChallengeAI
▏全球首个大规模多任务的真机基准测试平台
机器人正逐步融入现实世界,但目前仍缺乏统一、开放且可复现的基准测试方法,难以衡量技术进展或公平比较不同方法的优劣。改变这一现状需要构建一个大规模多任务的具身智能真机测试集,使得研发人员在统一环境中验证对比机器人算法,实现从基础任务到复杂现实应用场景的全面覆盖。

在此背景下,RoboChallenge应运而生。这一开放式机器人基准测试平台通过集成多款主流机器人(UR5、Franka Panda、Aloha、ARX-5)实现远程评测,为研究社区提供大规模、标准化、可复现的测试环境,推动具身智能算法在公平、可靠的基准下持续进步。
系统架构设计:集成经过工业验证的机器人硬件,每台均配备2–3台RGB-D相机,并部署统一软件栈实现机器人与视觉系统的高可靠性联动;所有系统均通过数月真实任务测试,确保长时间稳定运行。
基准任务设计:采用端到端任务成功率与过程评分相结合的评估机制;测试集所有任务均提供约1000条演示数据,并已完成基线模型的任务级微调。
开放与可扩展:面向社区开放,支持用户基于公开演示数据微调自有策略并参与评测;发布任务中间数据与评测结果,推动建立透明、公平的算法评估标准。
▏机器人选型
为精准评估VLA算法核心能力,RoboChallenge首期采用配备夹爪的机械臂作为标准化平台,未来会支持更多执行器类型。在感知方面,传感方案同步输出多视角RGB与对齐深度信息,以利于二维识别与三维推理需求,将来计划集成力控或触觉传感器。
机器人选型坚持高可靠性与学术通用性原则,最终在第一个测试集中集成UR5、Franka Panda、COBOT Magic Aloha及ARX-5四类主流机型,确保系统具备7×24小时持续运行能力,为社区提供稳定可复现的基准评测服务。
▏远程机器人测试
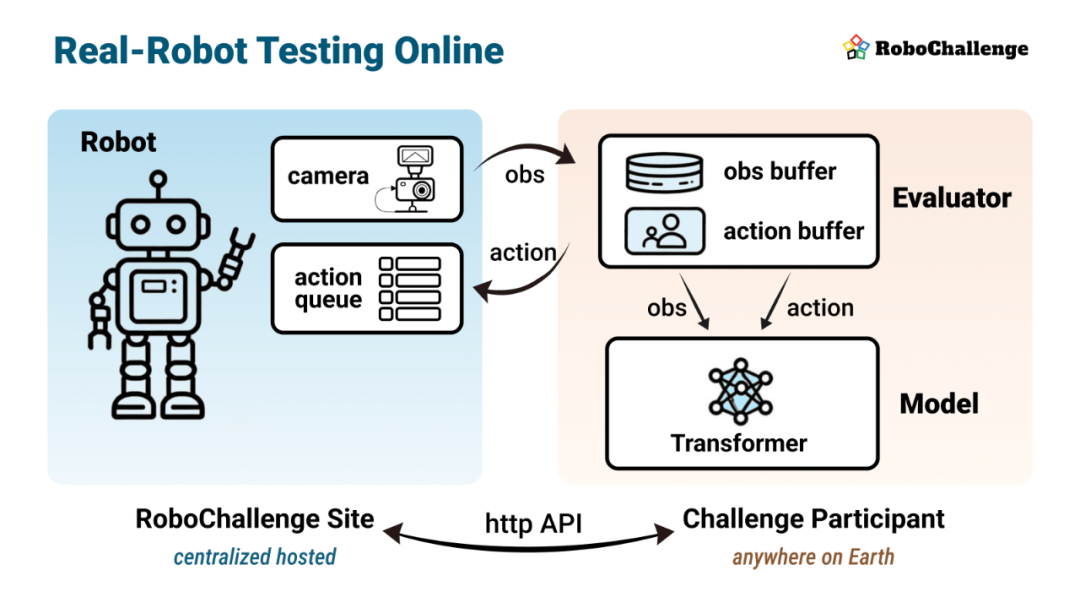
RoboChallenge通过创新的「远程机器人」方法,为学术界和产业界提供高精度、易用、免费的在线机器人测试服务。该平台最大的特点之一是以云端化服务突破机器人测试的硬件资源限制,实现「没有机器人,一样做实验」的效果,为具身智能研究提供高效、可靠的算法验证环境。
无容器化服务架构:系统采用标准化API接口,用户无需提交Docker镜像或模型文件即可直接调用;所有观测数据(RGB图像、深度信息、本体感知)均提供毫秒级时间戳,支持复杂的时间对齐策略与多模型集成。
双向异步控制机制:通过http API实现动作指令的异步提交与图像获取的分离处理;系统支持自定义数据块长度与动作持续时间,并提供实时队列状态反馈,确保控制指令的精准同步,用户无需暴露本地接口即可完成全流程测试。
智能作业调度系统:给用户提供任务调度状态接口,使其可以提前预估运行时,支持模型预加载与多任务并行管理,大幅提升测试效率。
▏基准测试方法
为建立严谨可靠的机器人算法(尤其是 VLAs)评估体系,RoboChallenge在设计基准测试方法时重点关注人为因素控制、视觉一致性保证、模型鲁棒性验证以及不同评估目标的协议设计。
为此,RoboChallenge创新性地提出「视觉输入匹配」(visual inputs reproduction)方法:从演示数据中抽取参考图像,并实时叠加于测试画面。测试人员通过调整物体位置使实时场景与参考图像完全吻合,确保每次测试的初始状态一致。该方法不仅降低了测试人员的技术门槛,其稳定性甚至优于依赖经验人员的传统模式,为大规模评测提供了可扩展的解决方案。
Table30是RoboChallenge的首套桌面操作基准测试集,包含30个精心设计的日常情境任务,相比之下,行业内真机竞赛或评测的任务数量一般仅为 3-5 个;这些任务由位置固定的双手或单臂机器人执行;通过科学的任务设计与评估体系,Table30为机器人算法发展提供可靠衡量标准,系统地评估算法在多维度场景下的泛化能力。
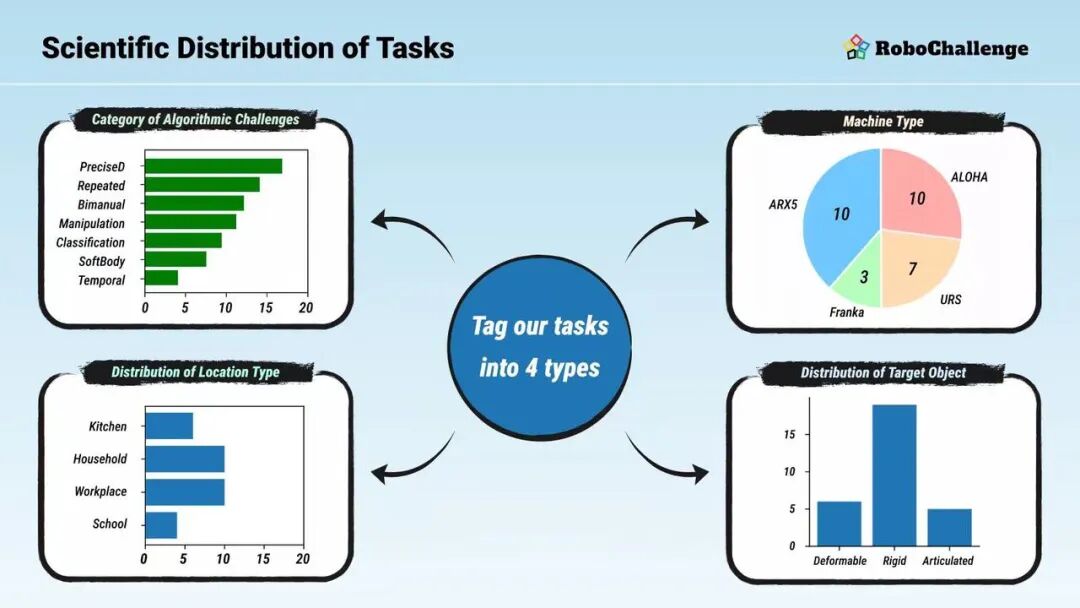
多维任务设计:Table30从四个关键维度构建评估体系:VLA解决方案难点、机器人类型、任务场景环境和目标物体属性。测试数据表明,即使最先进的基础模型也难以实现全面高分,印证该基准可作为通用机器人算法的「试金石」。
多能力任务测试:这些任务测试了模型的多种能力,包括:精准定位抓取点、理解物体间空间关系、多视角协同运用、双臂交替协作操作、杂乱环境中重复执行技能、记忆多步骤任务阶段。
创新性评分机制:Table30突破传统二值化评估局限,采用进度评分系统:对复杂任务认可分步进展,对简单任务优化完成效率;这一设计能更精准反映算法性能的代差。当算法实现突破性进展,评分体系将给予增量认可。
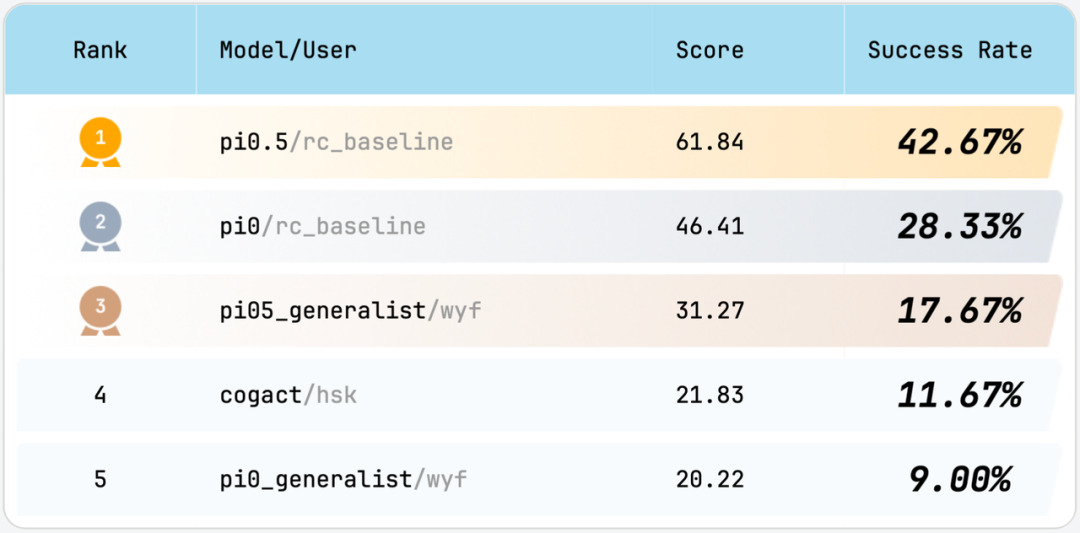
通过对主流开源VLA模型算法进行测试,结果显示最新发布的Pi0.5相较其他模型取得显著优势,但也无法在所有任务上都取得较高的成功率。由此可见:RoboChallenge基准测试可以作为迈向通用机器人技术的必要性检验。
▏模型提交
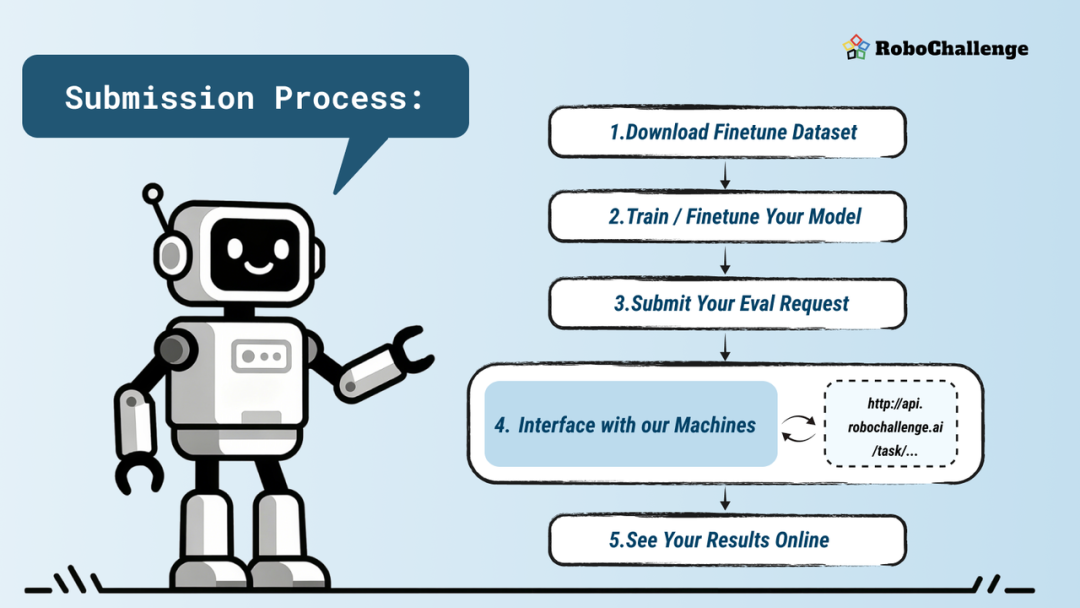
RoboChallenge参与者提交模型至测试平台的标准流程包含四个核心环节。
参与者首先从Hugging Face平台下载结构清晰的任务示范数据集,包含分开放置的视频文件与JSON格式状态数据,并可利用工具脚本转换为LeRobot格式。
随后选择训练模式:通用型模式需使用提示词区分任务并进行多任务联合训练;微调型模式则无特定限制。基于同一基础模型的多个提交可共享显示名称,在排名时合并为单一算法条目。
提交前需对接平台API:通过提供框架代码,演示观察-推理-停止的完整交互逻辑,支持评估前的模型预热与动作队列稳定控制,并配套模拟测试以供验证。提交评估时需注明密钥、任务集及模型名称,多任务提交将视作通用模型处理。
评估请求进入人工调度队列,因场景布置需数小时至数日完成。结果发布后,参与者可通过rerun.io查看器分析RRD格式的机器日志与视频。平台默认公开所有结果以促进交流,若对评分存疑可申请重新计算。
RoboChallenge坚持全面开放原则,向全球研究者免费提供评测服务,并公开所有任务演示数据及测试中间结果,确保研究的可复现性与透明度。后续,RoboChallenge将通过举办挑战赛、研讨会及数据共享,积极推动社区共建,鼓励研究者参与任务设计与优化,共同推进具身智能核心问题的解决。此外,平台还提供多维度细分排行榜,支持算法性能的深度分析。
▏迈向通用机器智能
Join RoboChallenge, This Is Your Opportunity To Shine!
RoboChallenge 全球首发同时还有相关主题的重磅直播,欢迎预约观看!

本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注公众号
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢