
摘要大语言模型(Large Language Models, LLMs)正在重塑化学信息学的研究范式。然而,模型生成的化学文本常常“语法无误、化学错误”。这种看似流畅却不可靠的输出,在科研场景中可能造成严重误导。本文介绍的 MolErr2Fix 是首个系统性评估 LLM 化学可信性的基准数据集,覆盖错误检测、定位、解释和修复四个阶段,旨在让模型不止“能说”,更要“说对”。
研究背景:语言模型的“化学幻觉”

随着 GPT-4、Claude、Gemini 等大模型的迅速发展,它们在分子描述生成(molecule captioning)、反应预测、药物设计等任务中展现出惊人的语言与模式学习能力。然而,研究者很快发现:这些模型往往能生成流畅自然的分子描述文本,但其内容在化学上却存在明显错误。
例如,在给定一个分子的 SMILES 结构后,模型可能:
错误判断了取代基位置或官能团;
混淆了母体结构与衍生物关系;
将立体化学 (R/S 或 E/Z) 方向反转;
甚至未能识别自身错误。
更严重的是,这些“化学幻觉”往往无法被传统自然语言评测指标发现。诸如 BLEU、ROUGE 等分数主要衡量文本表层相似性,而非科学事实的准确性。一个句子即使与参考描述在词汇层面高度相似,也可能在化学上完全错误。
正如论文所指出的,这类现象在药物描述、反应机制解析和材料性质预测等场景中尤其危险。因此,我们需要一个能量化模型“化学理解能力”的新型评测框架。
MolErr2Fix:化学可信性的新评测范式
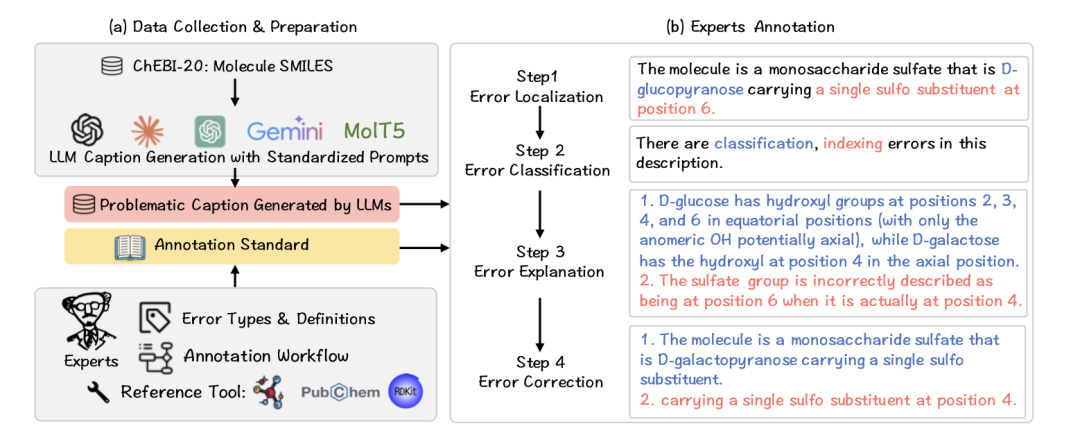
MolErr2Fix 由卡内基梅隆大学 (Carnegie Mellon University) 和香港科技大学联合提出,旨在系统评估语言模型在化学文本理解与修正中的表现。它将任务从单一的文本生成转化为化学错误分析链条,包括四个核心阶段:
错误检测(Error Detection)
判断文本中是否存在化学错误,并归类到六种错误类型:官能团/取代基、化学分类、衍生关系、立体化学、组成计数、编号定位。
错误定位(Error Localization)
通过标注文本跨度 (text span),指出具体错误所在的句段或词组。评估指标采用 IoU (Intersection over Union) 与 Recall@IoU≥0.5。
错误解释(Error Explanation)
让模型用化学语言说明“为什么错”。这一环节要求模型具备符号推理与专业知识结合的能力。
错误修复(Error Correction)
模型需对错误片段进行修改,而非重写整段描述,输出化学上正确的版本。
这套“从发现到修正”的链式流程,模拟了科研人员审阅论文、修改实验报告的真实过程。MolErr2Fix 不仅考查模型的生成能力,更考查其逻辑一致性与科学推理能力。
数据构建:人工精标的错误实例体系
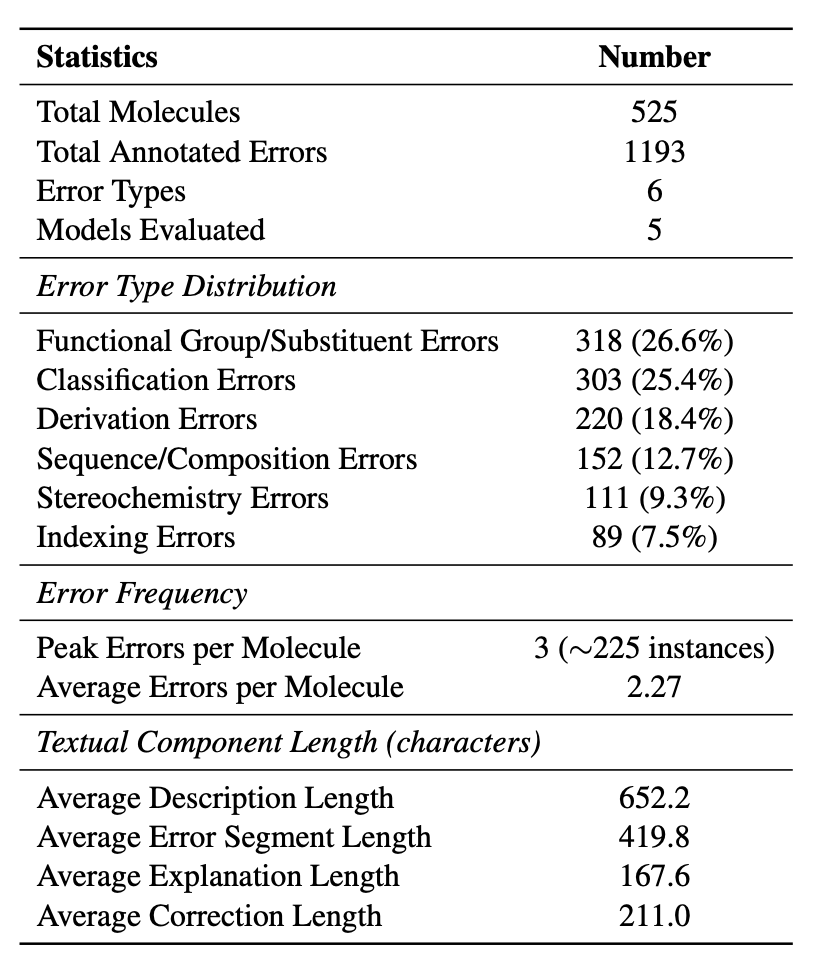
MolErr2Fix 数据集共包含 525 个分子、1,193 条精标错误实例。每个实例由三位具备有机化学背景的专家独立标注,注释内容包括:(错误类型、错误位置、错误解释、正确修复)
这些分子样本来源于 ChEBI-20 数据库中小于 100 个原子的分子,涵盖糖类、甾体、芳香化合物、酯类及胺类等常见结构类型。在标注过程中,研究者有意引入了多种“语言正确但化学错误”的描述样例。例如:
“A D-glucopyranose carrying a sulfo substituent at position 6”表面上语法正确,但缺少立体构型描述。
“A steroid ester that is methyl (17E)-pregna-4,17-dien-21-oate”名称正确,却遗漏了关键的酮官能团。
这些“陷阱式样本”构成了 MolErr2Fix 的核心测试难点,迫使模型必须具备结构级的化学理解,而非简单的语言匹配。
实验设计:让大模型接受化学审判
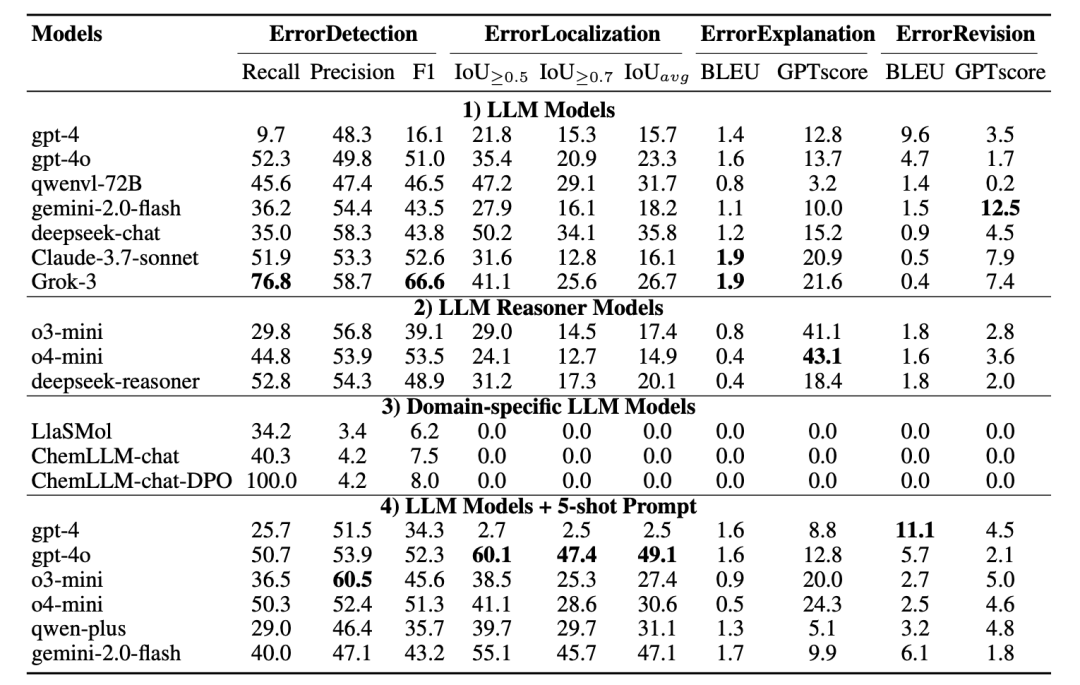
研究团队评估了包括 GPT-4o、Claude-3.7-Sonnet、Gemini-1.5-Pro、LlaSMol、ChemLLM 在内的多个主流模型。实验采用少样本提示 (few-shot prompting) 的统一框架,每个任务独立评测。
关键发现如下:
检测容易
修复困难在错误检测任务上,部分模型可达 F1≈66%;但在修复任务上,BLEU 分数普遍低于 2,几乎无法生成与专家一致的修正结果。
定位环节表现参差
模型对明显错误(如官能团类别)定位准确率较高,但在涉及数字编号、取代位次的文本中准确率急剧下降。
解释任务暴露推理短板
虽然模型能识别“这是官能团错误”,但往往无法解释“为何羟基不能出现在该位点”。
修复任务几乎全军覆没
模型在生成修改文本时缺乏一致性,甚至出现“改错越多”的现象。
总体结果显示,当前 LLM 在化学语言任务中仍主要依赖表层模式识别,缺乏系统的化学符号推理与错误自诊能力。
分析与讨论:为什么化学如此难?
MolErr2Fix 的结果揭示出 LLM 化学推理困难的三大根源:
专业知识稀疏化
分子结构规则(如环系编号、取代位次)在通用语料中极为稀少,即便在教材中也未形成系统表达。
符号表示隐含性
SMILES 的手性信息仅由 “@” 符号隐式表达,模型需通过邻接顺序与原子优先级反推结构关系。这类信息对基于文本的 Transformer 架构而言极难捕捉。
命名歧义与语义漂移
化学命名体系允许多种等价表达(如 IUPAC 与通俗名),而模型往往将其视为不同概念,导致语义混淆。
从认知层面看,LLM 的语言建模目标与化学知识的符号逻辑天然存在张力:语言追求“连续的语义流”,而化学知识强调“离散的结构逻辑”。MolErr2Fix 正是为了逼迫模型在这两者之间建立桥梁。
六、应用价值与未来展望
MolErr2Fix 的意义不仅在于评测,更在于推动化学领域 LLM 的“可信智能化”。
(1) 为模型改进提供方向
研究者可利用 MolErr2Fix 作为训练目标,结合自反思(self-reflection)机制与强化学习(RLHF),实现“检测→解释→修复”的闭环优化。
(2) 支撑多模态任务扩展
未来版本计划引入分子结构图(2D/3D)与语义文本联合输入,实现跨模态错误检测。
(3) 推动化学NLP标准化
MolErr2Fix 建立了一套通用错误分类体系,为化学自然语言处理的后续研究提供统一评测规范。
(4) 实际科研场景的可靠助手
在药物开发与文献自动审阅中,LLM 若能通过此类评测,意味着其输出结果更具“可验证性”与“可追溯性”。
结论与展望
MolErr2Fix 并非简单的评测任务,而是一种新的研究理念:让语言模型像科学家一样对待错误。
它要求模型不仅能识别问题,更能阐明原理并提出合理修改方案。通过这一体系,我们得以衡量模型是否真正理解了化学语义,而非仅仅复述语料。
未来,作者团队计划在以下方向继续推进:
扩展分子规模与类别,涵盖大分子与多肽体系;
引入基于图神经网络的辅助验证模块;
构建更贴近实验室场景的“多轮错误修复对话”任务。
正如论文结语所言:
“MolErr2Fix maps today’s limits and charts a path toward scientifically trustworthy LLMs.”——它不仅揭示了今天模型的局限,也为“科学可信语言智能”指明了方向。
论文信息与开源资源
论文Wu, Yuyang, Ye, Jinhui, Zhang, Shuhao, Dai, Lu, Bisk, Yonatan, Isayev, Olexandr.MolErr2Fix: Benchmarking LLM Trustworthiness in Chemistry via Modular Error Detection, Localization, Explanation, and Revision.EMNLP 2025 (Oral).
数据与代码
GitHub: https://github.com/HeinzVonHank/MolErr2Fix
Dataset: https://huggingface.co/datasets/YoungerWu/MolErr2Fix
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢