

科学知识是通过研究出版物和专利文献构建、解释和验证的。然而,这些文献格式不标准、布局多样、内容多模态,这给自动化分析带来了障碍。这些挑战降低了信息检索系统的效率,并限制了在大规模文档集上训练机器学习模型的能力。自然语言处理技术将文档视为纯文本,忽略了视觉信息的关键作用。这在化学领域是一个限制,因为化学结构图和马库什结构等视觉元素对于理解文档内容至关重要。为了弥补这一缺陷,本论文引入了新的机器学习方法,用于从文档中提取化学结构和马库什结构。此外,还创建了一个从专利文献中提取化学结构的大型数据库。该数据库支持对专利文献进行高级分析,并用于专门的机器学习模型训练。
论文的第一部分介绍了MolGrapher,这是一个旨在将化学结构图像转换为分子图的模型。 MolGrapher 分三个阶段处理输入图像:使用卷积神经网络检测分子中原子的位置,构建候选原子和键的超图,以及结合卷积神经网络和图神经网络对超图的节点进行分类。该架构能够在低分辨率图像和复杂的大分子图像上实现高效的训练和稳健的性能。
论文的第二部分基于 MolGrapher,介绍了一套完整的从文档中提取化学结构的流程。它集成了页面分割、图像分类和使用 MolGrapher 的分子图识别功能。该工作流程应用于大量专利文献,创建了 PatCID 数据库,该数据库包含从超过一百万份文献中提取的超过八千万个化学结构。PatCID 使用户能够识别提及特定分子的文献,并可作为下游机器学习任务的宝贵训练数据来源。实验表明,PatCID 在质量和覆盖范围方面均优于现有的自动生成的数据库,并且对于补充手动创建的数据库具有重要意义。
论文的最后一部分探讨了马库什结构的识别,马库什结构是文档中用来定义相关分子类别的表示形式。这项具有挑战性的任务需要对视觉图表和文本成分进行联合解读。为了解决这个问题,论文引入了MarkushGrapher,这是一个结合了视觉-文本-布局编码器和光学化学结构识别编码器的模型。MarkushGrapher将马库什结构转换为由图形和表格组成的结构化表示:图表示结构的视觉成分,表格代表其文本定义。实验结果表明,MarkushGrapher 在多种评估设置中的表现均显著优于专门的化学模型和通用的视觉语言模型。

论文题目:Multimodal Document Understanding for Chemical Structure Extraction
作者:Morin, Lucas
类型:2025年博士论文
学校:ETH Zurich(瑞士苏黎世联邦理工学院)
下载链接:
链接: https://pan.baidu.com/s/1M0_81a-bhbY_AIVHijzloQ?pwd=ajxc
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
1.1 动机
科技出版物是创造、传播和验证知识的主要渠道。然而,出版物数量的快速增长,增加了重要发现在浩如烟海的文献中湮没的风险。如果没有高效的信息搜索工具,关键洞见可能会被忽视,从而导致重复或误导性的研究工作。知识与索引它的算法(例如谷歌搜索[13])和访问它的生成模型(例如GPT[99])密不可分。
科学知识高度分散,缺乏标准化。虽然一些知识存储在结构化数据库中,但大多数知识以非结构化格式存在,例如期刊文章、书籍、专利文献和公司内部文件。这些文档的结构因出版商、地区和出版年份而异。此外,它们通过各种形式(包括文本、表格和图表)传达信息,这使得标准化和自动化处理具有挑战性。
将科学知识统一为机器可读的格式可以加速研究。首先,它使搜索引擎能够帮助研究人员更有效地识别相关文献。搜索功能在增强大型语言模型方面也发挥着重要作用,无论是通过检索增强生成[72]还是通过使代理能够调用外部工具[149]。其次,对科技文献的大规模分析使我们能够更深入地探索现有知识,例如,通过链接相关概念并通过知识图谱揭示模式[58]。第三,将非结构化文档转换为机器可读格式对于训练机器学习模型至关重要。鉴于机器学习的最新进展很大程度上得益于对大型高质量数据集的获取,这一点尤为重要。例如,AlphaFold [42] 能够准确预测蛋白质结构,这得益于蛋白质数据库 [10] 的海量数据。
实现这种统一需要技术创新和出版实践的转变。一方面,新标准应鼓励在出版物的同时提交结构化、机器可读的内容。开发平台以支持科学家存储新类型的数据也十分必要 [43,49, 63]。虽然通用数据存储库提供了基本的存储空间,但它们缺乏对特定领域数据(例如化学结构或光谱测量)所需的结构理解。另一方面,能够从文档中提取信息的算法的进步对于提高搜索引擎和生成模型的性能至关重要。
从文档中自动理解科学知识仍然是一个具有挑战性的研究课题。自然语言处理方法将文档视为纯文本,但它们本质上是多模态的,即它们结合了文本和视觉信息。它们通过页面布局传达含义,通过表格传达结果,并使用图形描述工作流程。为了真正理解这些文档,模型必须超越文本,并整合这些不同的模态。这一挑战推动了文档理解模型的发展。

化学结构表示。文献中使用的化学结构有多种表示方式。单个分子可以用以下方式表示:(a) 化学结构图或 (b) 文中的名称。(c) 描述一类相关分子的马库什结构,可以用图像和文本描述表示。视觉表示用红色表示。文本表示用蓝色表示。
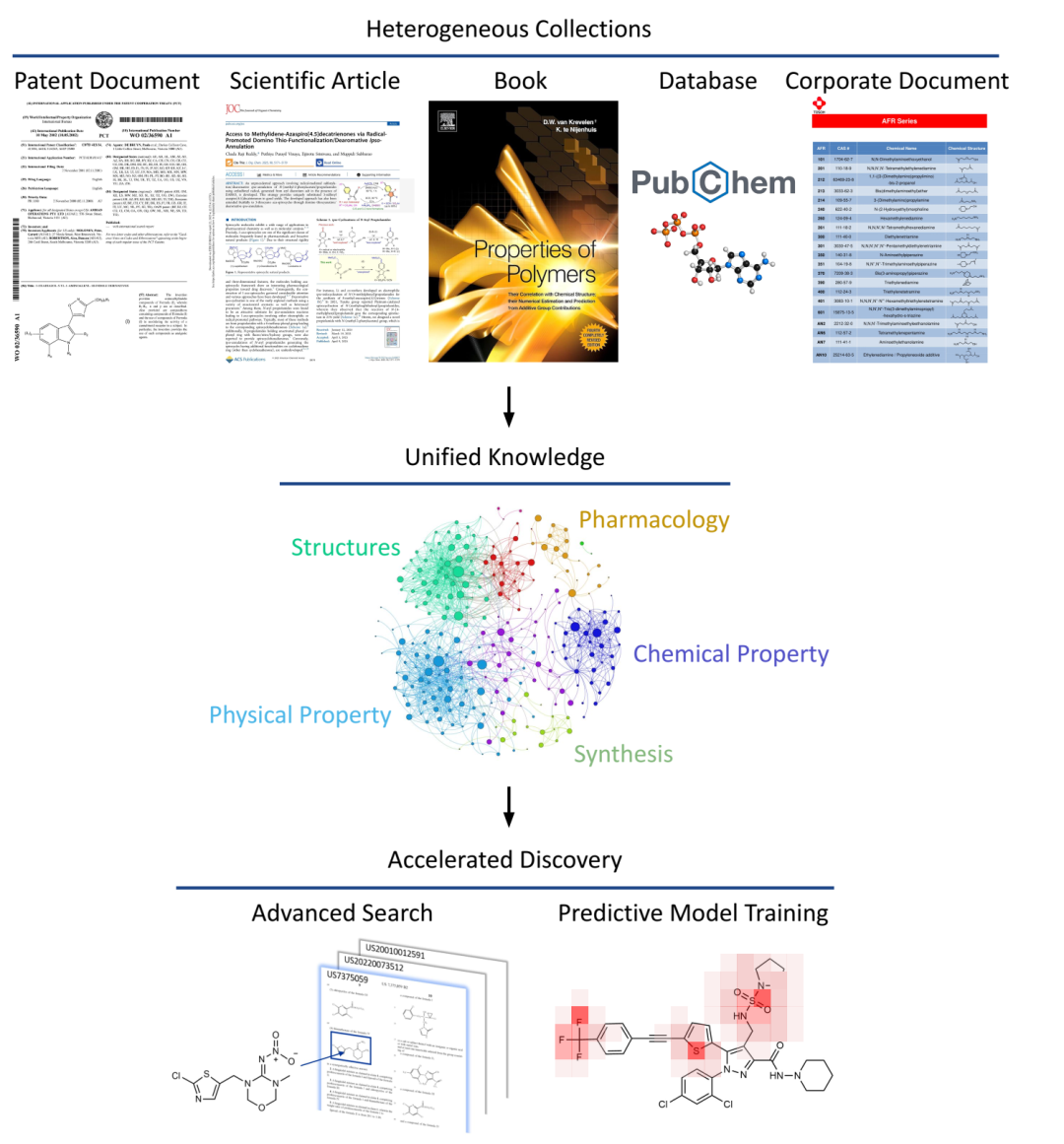
化学领域的多模态文档理解旨在将非结构化文档(例如专利文献、科学论文、书籍和公司文档)转换为结构化的机器可读格式,从而统一化学知识。这种统一的知识能够实现文献的高级分析和机器学习模型的训练。
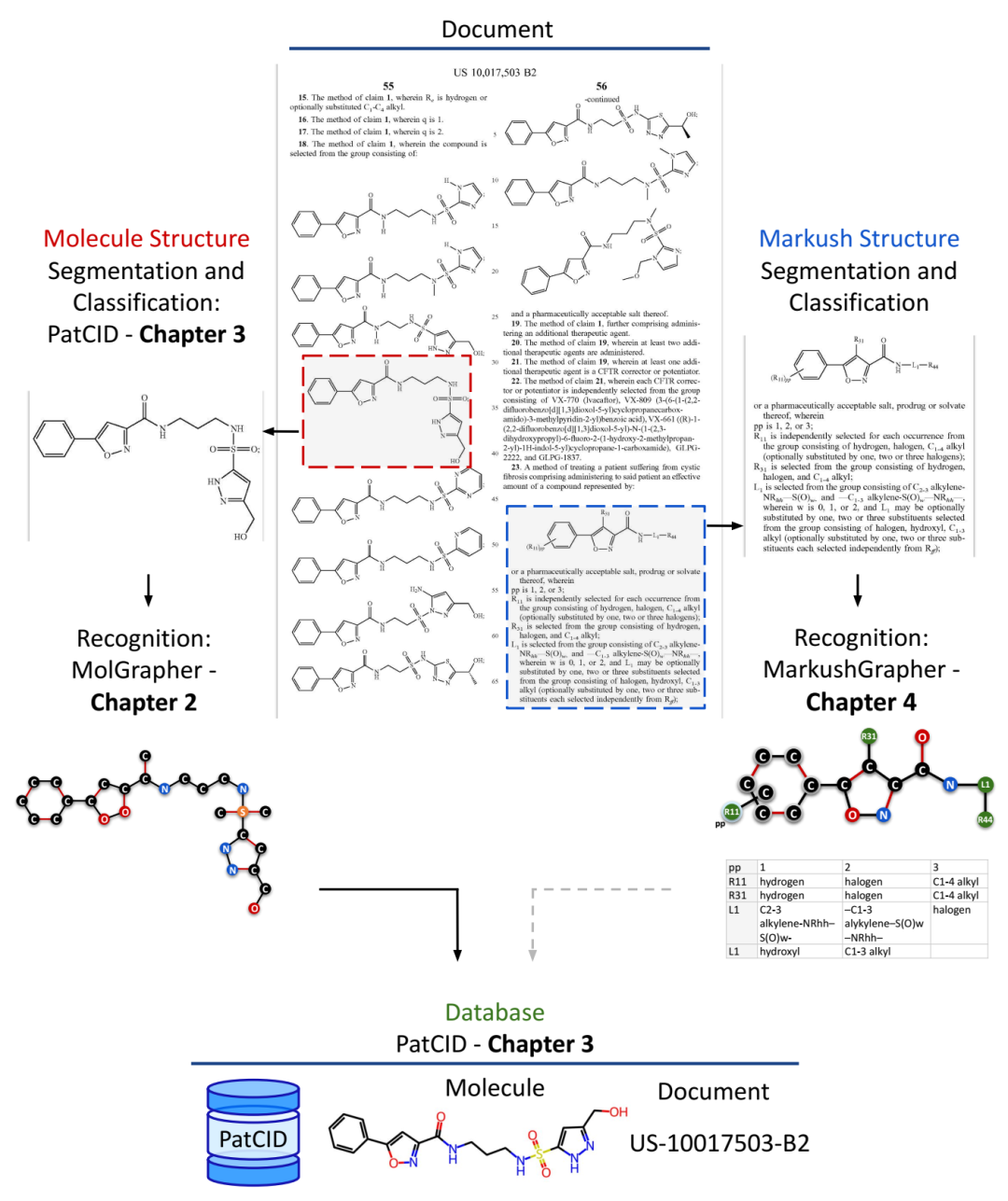
论文概述。专利文献示例页,包含化学结构图像和马库什结构。本论文分为三个主要章节。第二章介绍了一种用于识别化学结构图像的模型。第三章展示了一个从专利文献中提取的化学结构数据库,以及完整的文档到分子的转换流程。第四章提出了一种用于识别马库什结构的模型。
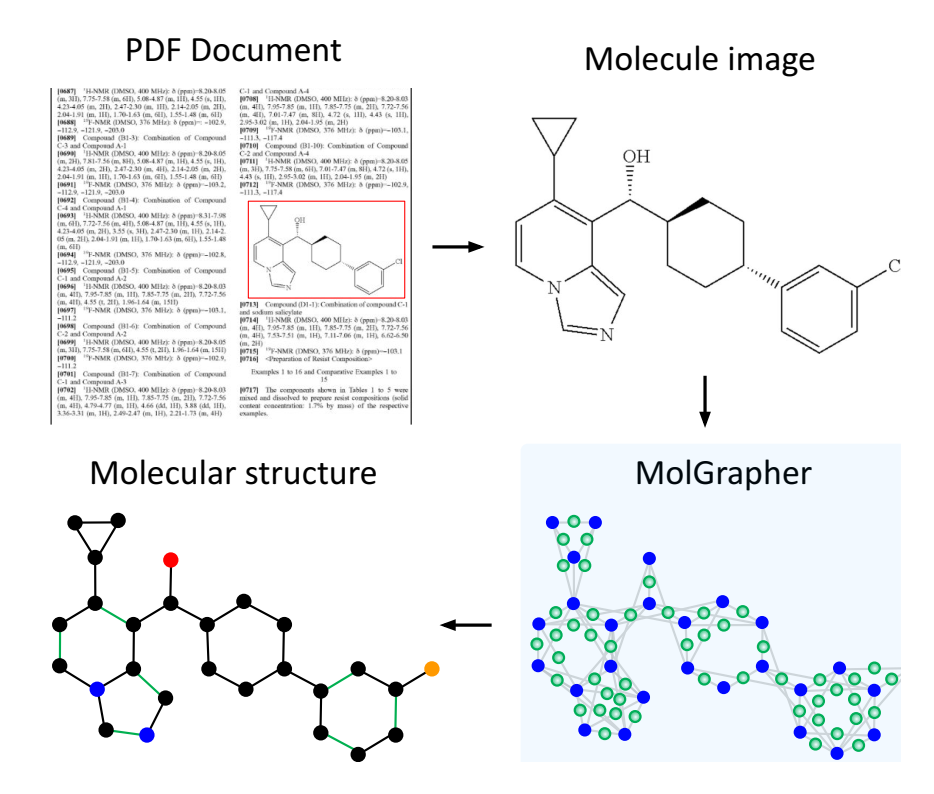
MolGrapher 从文档中的分子图像中提取化学结构,包括所有原子和键。我们的方法构建了分子的超级图(右下角),其中包含所有检测到的原子和键候选。然后,这些节点通过图神经网络进行分类,以检索化学结构。
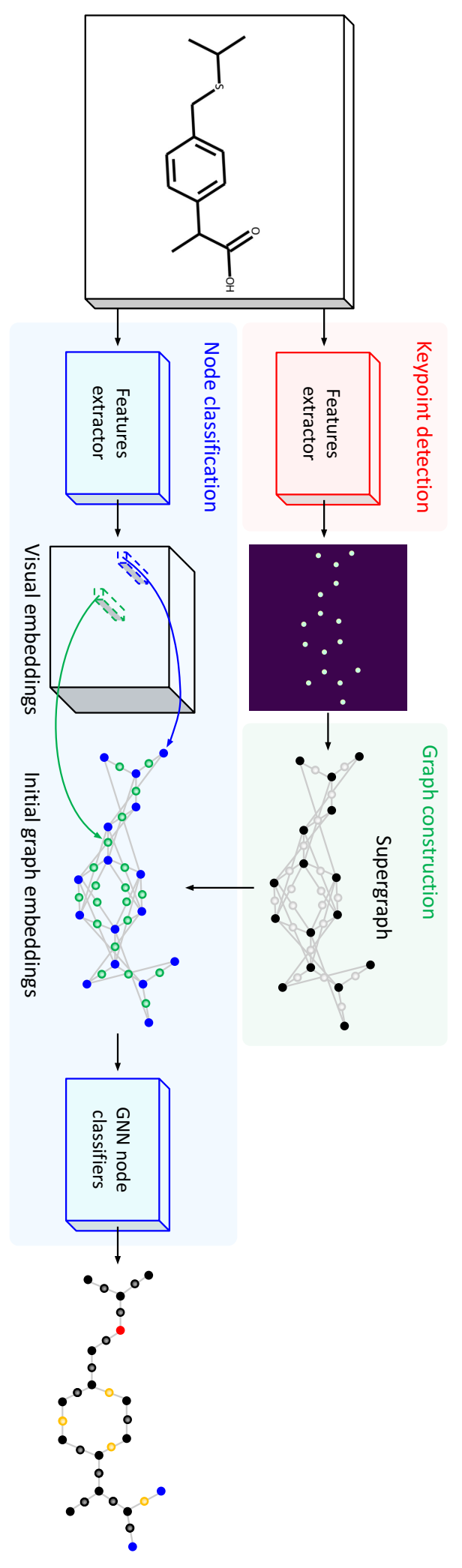
分子图识别架构。我们展示了 MolGrapher 的架构,这是一个基于图的网络,用于光学化学结构识别。关键点检测器(红色)定位分子中的原子节点。构建包含原子和键候选的超图(绿色)。使用图神经网络(蓝色)对原子和键进行分类。
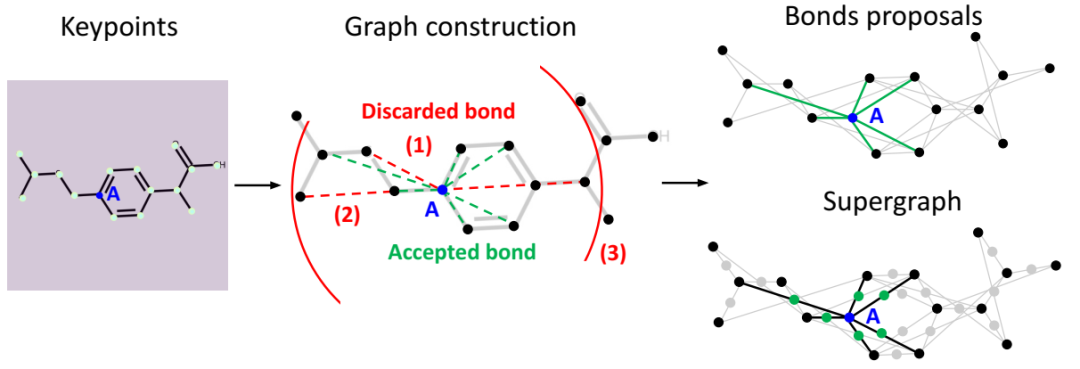
超图构建。该图展示了原子 A 的键合方案的构建过程。考虑的键合用虚线表示。绿色键在超图中被接受,而红色键被丢弃,因为:(1) 它们的中心点周围没有填充像素,或 (2) 它们被其他关键点遮挡。
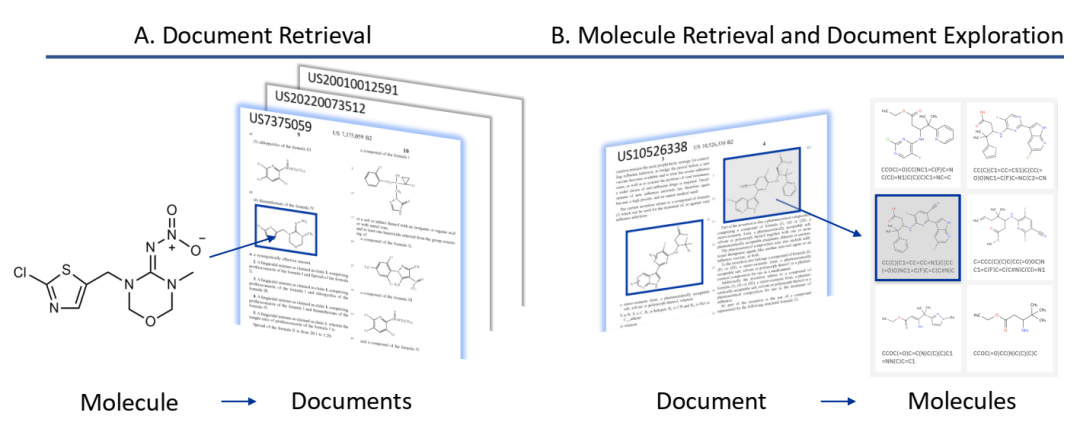
PatCID 用于文档和分子检索。PatCID 可以 (A)通过相似性、子结构或原图检索,检索与查询分子相关的专利文献。它还可以 (B) 检索文档中包含的分子,并用于交互式探索文档集合。
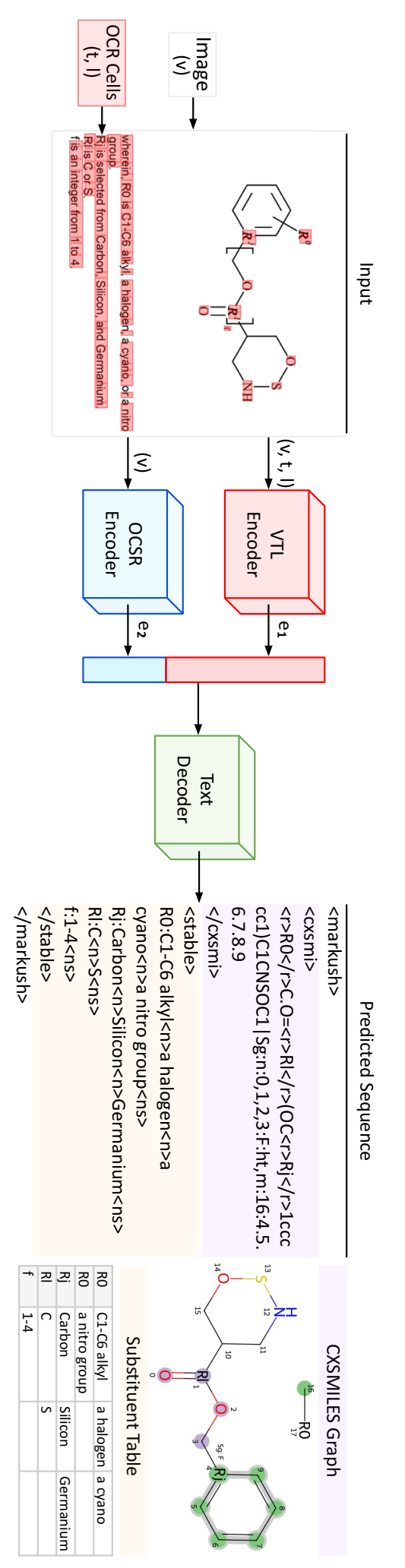
马库什结构识别架构。MarkushGrapher 使用 VTL 编码器(蓝色)和 OCSR 编码器(红色)对输入图像及其文本进行联合编码。VTL 输出 (e1) 和 OCSR 输出 (e2) 连接在一起。最后,此联合编码经过文本解码器处理,预测马库什骨架(紫色)及其取代基表(橙色)的顺序表示。
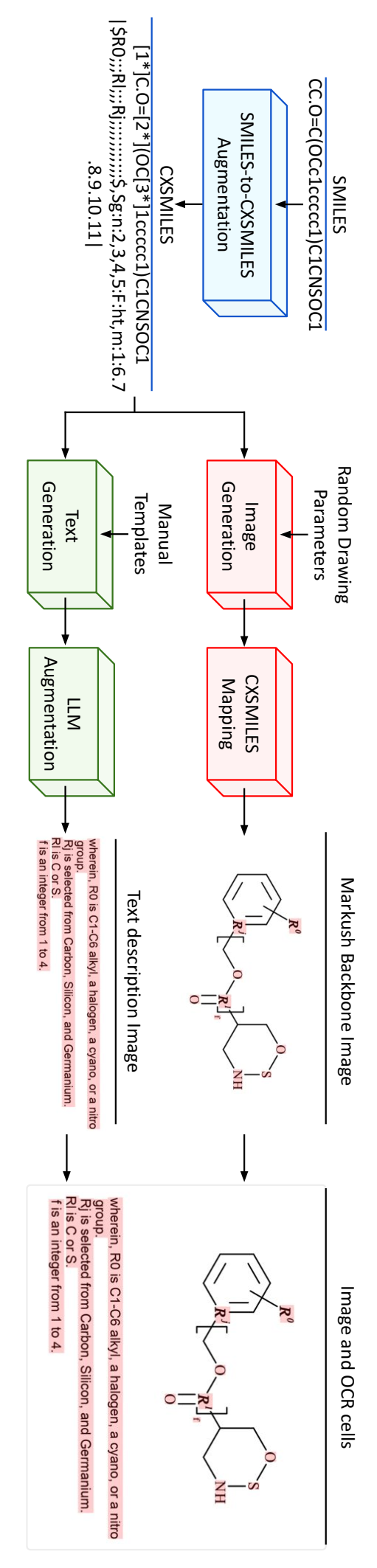
合成训练数据生成。该图展示了生成合成训练样本的流程。首先,从 PubChem 数据库中采样一个分子,并对其进行增强以创建 CXSMILES 库。其次,使用 CXSMILES 库联合生成马库什骨架及其 OCR 单元的图像(红色),以及文本描述及其 OCR 单元的图像(绿色)。最后,整理图像以创建训练样本。






内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢