


关键词:镜像神经元,表征对齐

导 读
从模仿父母挥手,到观看视频学会一道新菜,人们似乎天生就拥有一种“看样学样”的神奇能力。这背后隐藏着大脑的一项深刻机制,而它的发现,要从一个关于猴子和花生的故事说起。上世纪90年代,镜像神经元这一偶然发现,揭示了生物智能的深刻奥秘:“看别人”与“自己做”并非各自为营,而是通过一个镜像系统被紧密地联系在一起。然而,当前的人工智能却常常忽略这一点,割裂了动作理解与具身执行的内在联系。我们不禁要问:在深度神经网络内部,这种“看”与“做”的神经表征之间,是否也存在着类似镜像神经元的“自发默契”?更进一步地,我们能否设计一种机制来主动加强这种联系,让 AI 的理解与行动像生物一样相互启迪、协同进化?
这篇发表于计算机视觉顶会 ICCV 2025 的研究论文 Embodied Representation Alignment with Mirror Neurons 深入探索了这些问题。该研究由北京大学王亦洲课题组与宁波东方理工大学、高通人工智能研究院(Qualcomm AI Research)合作完成,第一作者朱文韬博士现任宁波东方理工大学助理教授。
论文链接:
https://arxiv.org/abs/2509.21136
01
引 言
上世纪90年代,神经科学家在研究猕猴大脑时有了一个偶然却意义深远的发现:他们观察到,当猴子伸手抓取花生时,其大脑运动皮层的特定神经元会放电;而当它仅仅是看着研究人员做同样的动作时,这些神经元竟然也同样活跃起来。这便是镜像神经元(Mirror Neurons)的首次发现。随后的研究在人类大脑中也发现了类似的系统。这一发现意义非凡,科学家们进一步猜想,这套镜像系统可能正是我们模仿学习、理解他人意图甚至产生共情能力的基础。它构成了连接感知与行动的天然桥梁,使我们得以设身处地、感同身受。

图1. 镜像神经元的经典图示:无论是自己做(左),还是看着别人做(右),猴子大脑的同一区域都表现出相似的神经活动。
这一生物机制是具身认知(Embodied Cognition)理论的有力佐证,它揭示了一个核心思想:认知并非独立于身体的抽象计算,而是深深根植于身体与环境的物理交互之中,简而言之,我们的理解源自于我们行动的能力。然而,当前的人工智能研究常常并非如此,将用于观察的动作理解(Action Understanding)与用于行动的具身执行(Embodied Execution)作为两个独立的任务来处理,从而忽视了它们之间潜在的协同作用。这种分离忽视了它们之间深刻的相互依存关系:理解为行动提供蓝图,指导技能学习;而行动则通过第一手的实践经验,反过来修正和深化理解。实际上,二者本应构成一个不断强化的良性循环:就像学徒需要观察师傅(理解)来指导实践,也需要通过亲手实践(执行)中获得的感悟,反过来更深刻地看懂师傅的门道。
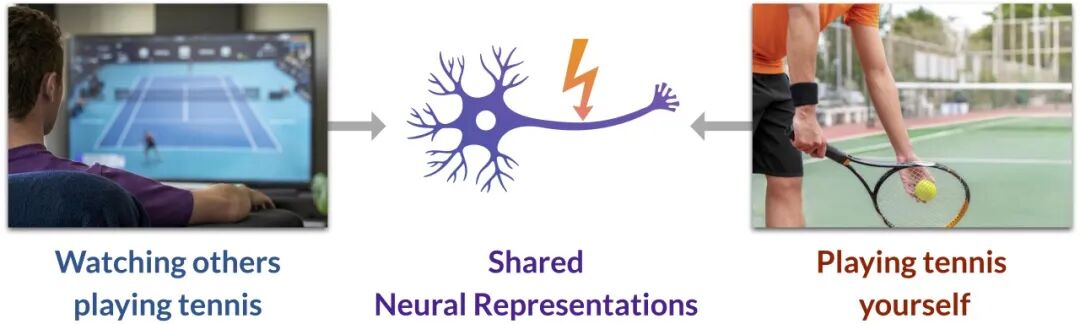
图2. 镜像神经元的核心作用:它提供了一套共通的神经表征,使得“观察”他人动作(左)与“执行”自身动作(右)之间建立了深刻的内在联系。
正是这种现状与生物智能的割裂,促使我们提出了两个核心的研究问题:
首先,在没有显式引导的情况下,为观察和行动而独立训练的模型,其内部神经表征是否会自发地产生对齐?
其次,如果存在这种对齐,我们能否设计一种机制来主动加强它,并借此反过来提升两个任务的性能?
02
独立模型的自发默契
我们首先进行了一项探索性实验。我们分别独立训练两个模型:一个用于从视频中理解动作,另一个用于控制机器人执行指令。我们通过对齐探测(Alignment Probing)方法分析它们在处理相同任务时的内部神经表征,等价于估计两者的互信息。
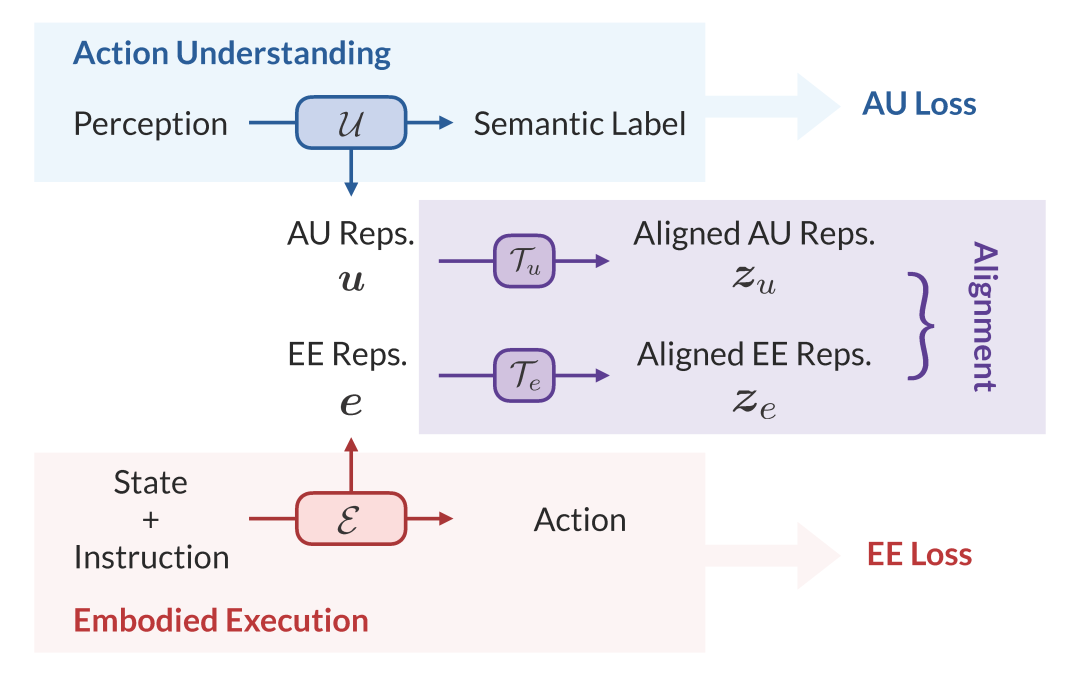
图3. 我们首先冻结两个独立训练的动作理解和具身执行模型,并测量其表征对齐程度。
我们观察到一些有趣的现象:
发现1:我们发现,即使没有经过任何协同训练,这两个模型在处理语义上相同的任务时,其神经表征会自然地表现出一定的相似性。
发现2:我们进一步发现,这种默契的程度与任务表现直接相关。对于两个模型而言,其任务成功集合的表征相似度显著更高。
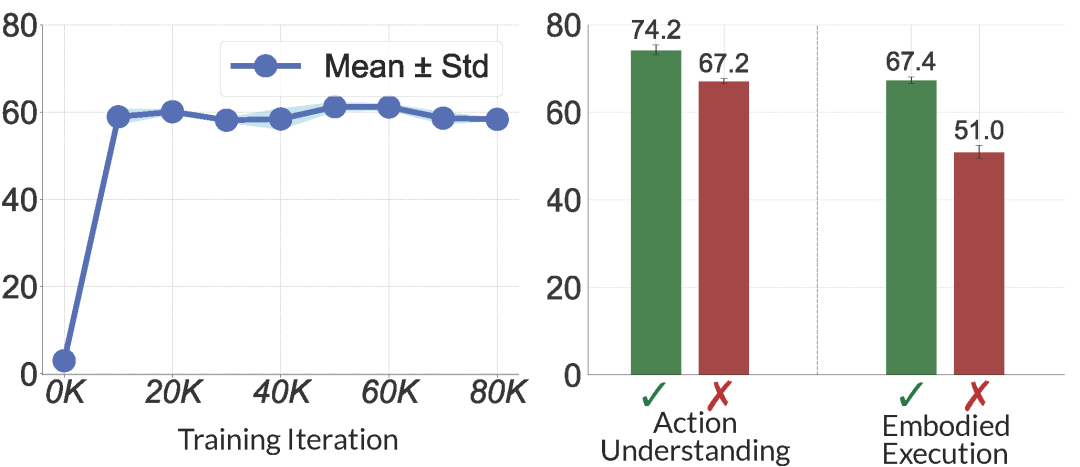
图4. 模型表征对齐探测结果。 左图: 对齐程度在模型训练过程中的变化趋势。右图: 针对两个预训练模型,分别在其任务成功和失败的子集上计算出的对齐程度。
这些发现验证了我们的初步猜想:观察与行动之间确实存在着深刻的内在联系。这也促使我们思考,如何将这种自发的联系转化为一种有目的的设计。
03
镜像神经元启发的表征对齐
基于上述洞察,我们设计了一个统一的学习框架,其核心是表征对齐(Representation Alignment),也就是让两个模型在学习时,学会用一种更共通的内部语言来描述同一个动作。
图5. 受镜像神经元启发,我们让 AU 与 EE 模型在优化各自任务的同时,通过两个线性层对齐内部表征。
为此,我们在动作理解(AU)和具身执行(EE)两个模型之间,加入了一个由两个线性层构成的轻量级对齐模块,将其内部表征映射到一个共享的特征空间。然后采用对比学习(Contrastive Learning),在处理相同动作时(例如“把杯子放在架子上”)鼓励它们的内部表征在特征空间中相互靠近,而不同动作的表征则互相远离。我们将这个对齐目标与两个模型各自的原始任务目标结合,进行端到端的联合训练。从信息论的视角来看,我们证明这个对齐过程等价于最大化两个模型表征之间的互信息(Mutual Information)。通过这种方式,我们的框架促使观察到的视觉信息与执行该动作所需的物理知识相互印证和补充,从而学习到更鲁棒、更全面的动作表征。
04
实验成果:双任务性能协同提升

图6. 镜像神经元设计让 AI 的动作更精准,尤其是在复杂的精细操作上,效果明显优于传统基线模型。
实验结果证明了所提出框架的有效性:
动作理解更精准:得益于具身执行经验的引入,动作理解模型的识别准确率从71.6%提升到74.9%。
机器人执行更可靠:在包含18个任务的复杂机器人操控基准测试中,把基线方法平均成功率从85.3%提升到88.8%,尤其在需要精细操作的任务上改进更为明显。
表征质量更高:通过可视化分析,我们发现经过对齐训练后,不同动作的表征在特征空间中形成了更清晰、有序的聚类,证明我们的方法能学习到更好的特征解耦,从而提升了模型的泛化能力。

图7. 镜像神经元对齐后的模型,相同任务(同色点)的内部表征聚类更紧密,不同任务间的界限也更清晰。
05
总 结
在这项工作中,我们受镜像神经元的启发,提出了一个连接 AI 感知与行动的统一表征学习框架。我们的研究表明,这两项能力并非孤立的,而是可以通过共享表征实现相互协同、共同进化。我们相信这项工作为构建更接近生物智能的具身认知系统提供了有价值的参考。

图文 | 朱文韬
Computer Vision and Digital Art (CVDA)
About CVDA
The Computer Vision and Digital Art (CVDA) research group was founded in 2007 within the National Engineering Research Center of Visual Technology at Peking University led be Prof. Yizhou Wang. The group focuses on developing computational theories and models to solve challenging computer vision problems in light of biologically plausible evidences of visual perception and cognition. The primary goal of CVDA is to establish a mathematical foundation of understanding the computational aspect of the robust and efficient mechanisms of human visual perception, cognition, learning and even more. We also believe that the marriage of science and art will stimulate exciting inspirations on producing creative expressions of visual patterns.
CVDA近期科研动态

CVPR 2025 | SAT-HMR:实时的多人3D人体网格估计

— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

点击“阅读原文”转论文链接
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢