

DeepSeek 昨天开源的 OCR 新模型在 AI 圈内小火了一把。
项目地址:https://github.com/deepseek-ai/DeepSeek-OCR
简单来说,DeepSeek-OCR 模型是一个专门能「读懂」图片里文字的 AI 模型。但厉害的地方不是简单的「识字」,是采用了一种非常新颖的思路:把文字当成图片来处理和压缩。
你可以把它想象成一个超级高效的「视觉压缩器」。传统的 AI 模型是直接「读」文本,但 DeepSeek-OCR 是先「看」文本的图像,然后把一页文档的图片信息高度压缩成很少的 visual tokens。
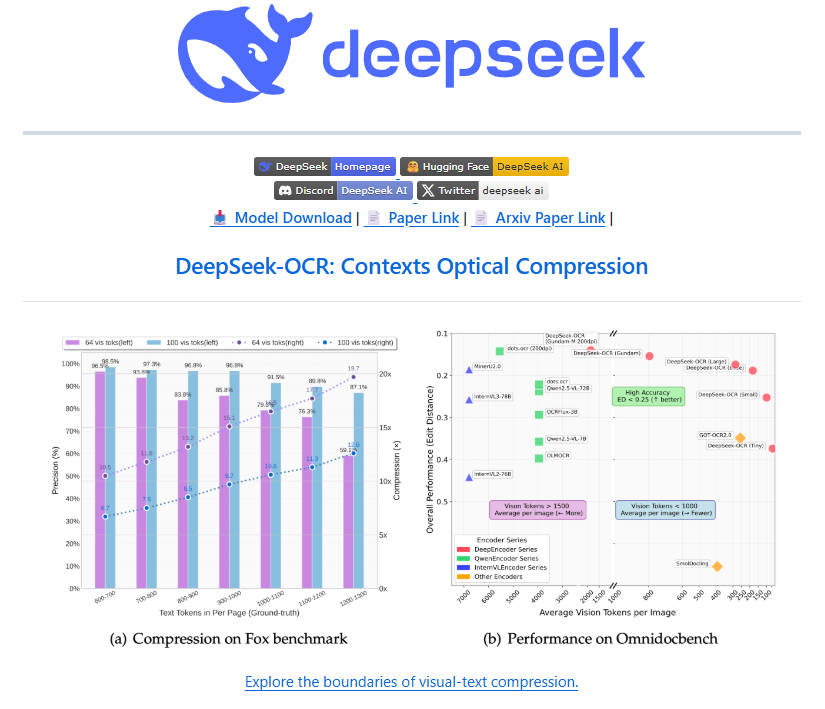
DeepSeek-OCR 的能力强在,能把一篇 1000 字的文章,压缩成 100 个视觉 token。在十倍的压缩下,识别准确率可以达到 96.5%。
Karpathy 在 X 上表达了对 DeepSeek-OCR 研究工作的肯定,同时思考了对于 LLM 信息处理的未来范式:也许未来所有输入大模型的信息都应该是图像形式,哪怕是纯文本,也先渲染成图片再喂给模型。
Remio 创始人、前网易副总裁汪源对于DeepSeek-OCR 有一点不一样的想法,在他看来,不能只把 DeepSeek-OCR 当做一个 OCR 模型来看待。
最新、最值得关注的 AI 新品资讯;
不定期赠送热门新品的邀请码、会员码;
最精准的AI产品曝光渠道
作者介绍:汪源,久痕科技创始人,前网易副总裁、杭州研究院执行院长。久痕科技曾推出 AI 办公助手产品 remio。
文章转载自汪源个人公众号,Founder Park 授权转载。
超 15000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。

Karpathy:或许 LLM 的所有输入都应该是图像
DeepSeek 刚发的 OCR 模型有点小火,一方面是突出的性能,号称压缩 10 倍还有 97%准确率,另一方面关于用分辨率来压缩信息和模拟遗忘机制的假想,恰巧 AK 在最近的访谈中说人的遗忘是一个 feature 而不是 bug。
这个模型引起了很多人的关注,不少人惊呼太牛逼了,一张图只需要几十个 token,有些人认为是最近最惊喜的模型,有些人认为 DeepSeek 团队思路清奇,堪称鬼才。AK 昨天也发了一个长推,对 DeepSeek 使用视觉模型来处理和压缩文本信息的思路表示欣赏,他认为或许 LLM 的所有输入都应该是图像,因为文本输入的 tokenizer 有挺多问题。AK 说他骨子里是搞视觉的,只是现在 LLM 大火也不得不参与。作为李飞飞的高徒和特斯拉自动驾驶 AI 负责人,AK 确实骨子里是视觉派。
研究思路不算是首创,
核心是把研究成果进一步做扎实,产品化
我认为,作为一个 OCR 模型,DeepSeek OCR 的性能和思路可能不算很大的突破,但产品化的贡献值得肯定。
DeepSeek OCR 模型很有意思的一点是提供了好多个「分辨率」选项,并且看起来用的 token 很少。最低的 512 x 512 一张图只需要 64 个 token,稍大一点的 1024 x 1024 是 256 个 token。复杂版面还组合使用多种分辨率,首先是整张图用 i 个 1024 x 1024,此外重点区域可能用多个 640 x 640。
其实至少在学术界,这样的视觉编码效率并不算很大的突破。效果上,AK 的评价是 DeepSeek OCR 是一个不错的 OCR 模型,但感觉略弱于 dots.ocr,这个是前段时间小红书搞的。
DeepSeek OCR 多分辨率的搞法,和去年字节的那篇 best paper 的思路有相似(还记得去年字节有个实习生搞破坏被公司索赔 800 万吗,他就是 paper 的作者)。那篇 paper 是去年顶会 NeurIPS 的 best paper,提出的 Visual Autoregressive Modeling(VAR)方法就是采用"粗到细"的多尺度预测,逐步从低分辨率扩展到高分辨率。另外,去年豆包团队也有一篇 paper,把 512 x 512 的图片也是编码到了 64 个 token,和 DeepSeek OCR 一模一样。那篇 paper 还能把 256 x 256 的图片编码到更小的 32 个 token。DeepSeek OCR 模型毕竟是要做文字识别而不是场景理解的,可能因此舍去了不太实用的 256 x 256 尺寸。
所以有可能 DeepSeek OCR 也是受到了这两篇 paper 的启发,把它进一步工程化产品化了。从过往的记录看,DeepSeek 团队特别把其它实验室的研究成果进一步做扎实,产品化。
一个有潜力的方向,
不能只当成 OCR 模型看
但 AK 提到的用图像代替文本作为 LLM 输入的想法,我认为确实有可能成为一个有潜力的方向,因为如果技术能成熟的话,会很有用。大量的网页和文档都是图、文、表格等混排的,很多 SaaS 软件都有一堆有一堆的 Dashboard,PPT 也是非常典型的有很多版面布局。这些信息都是有效的视觉传达,如果强行转化成文本会有很多信息损失。但因为现在视觉大模型在处理这类图文表混排的场景时效果还不够好,成本还很高,导致应用还是只能采取转文本的方式。如果 DeepSeek OCR 这次引起业界对图文表混排场景优化的研究热潮,把这块的效果快速提上去,成本快速降下来,就已经非常有意义了。
至于 DeepSeek 团队用分辨率来模拟遗忘机制的假想,确实是个有点意思的想法,但也感觉有点不太对。越来越模糊的分辨率,感觉模拟的更像是越来越高度的近视,这是一种很好的遗忘机制吗?另外,人脑的遗忘机制可能适合人脑,未必适合数字的第二大脑。人脑要遗忘也可能是因为一个人的脑容量毕竟有限,数字系统容量可以一直扩,是不是一定要遗忘呢。这些都是问题。这得多想想。
DeepSeek OCR,不要只当作 OCR 模型看,可能是醉翁之意不在酒。

ARR 突破 1 亿美元,HeyGen 创始人公开了他们的内部增长手册,全是干货
硅谷一线创业者内部研讨:为什么只有 5%的 AI Agent 落地成功,他们做对了什么?
转载原创文章请添加微信:founderparker
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢