

作者:派大星行
编辑:李宝珠
转载请联系本公众号获得授权,并标明来源
「HuMo-1.7B:多模态视频生成框架」现已上线 HyperAI超神经官网(hyper.ai)的「教程」板块,不妨来试一下,当你给出更充足的信息,模型能产出令你满意的视频吗?
如今,由 AI 生成的视频变得越来越逼真,初见时总令人震撼,细究却又觉得哪里不太对劲?那种介于真实与虚假之间的「恐怖谷」效应,让人惊叹之余又难免出戏。
联想到创意工作中常见的场景,如果甲方只抛出一句模糊的想法,最终作品往往难以符合预期。只有当需求细化到风格、出镜人物、语气氛围等维度,结果才更贴近理想,视频生成亦是如此。区别于图文,视频同时承载着声音、人物与动作的多重信息,这意味着模型不仅要「看懂」文本语义,还要「协调」视觉与听觉的表达。
然而,当前多数模型大多依赖单一模态输入。近期一些尝试多模态控制的方法,也往往难以让声音、表情、动作三者有效协作。如何让不同模态真正协同工作,生成自然可信的人物视频,仍是一块难啃的骨头。
针对于此,清华大学与字节跳动智能创作实验室联合发布了 HuMo 框架。HuMo 提出「协同多模态条件生成」的理念,将文本、参考图像与音频三种输入纳入同一生成模型中,并通过渐进式训练策略与时间自适应引导机制,通过在去噪步骤中动态调整引导权重,它不仅在人物外观保持与音画一致性上有所突破,也推进视频生成从「多阶段拼接」迈向「一站式生成」。
论文地址:
https://arxiv.org/abs/2509.08519
原始仓库:
https://github.com/phantom-video/humo
除此之外,HuMo 在文本跟踪、图像一致性等多项子任务中的表现达到了 SOTA。该项目提供了 1.7B 和 17B 两种规格的模型,轻量可玩专业可研,适合创作者和开发者的不同需求。下面让我们一起看看,17B 模型的生成效果吧:
「HuMo-1.7B:多模态视频生成框架」+「HuMo-17B:三模态协同创作」现已上线 HyperAI超神经官网(hyper.ai)的「教程」板块,不妨来试一下,当你给出更充足的信息,模型能产出令你满意的视频吗?
教程链接:
HuMo-1.7B:https://go.hyper.ai/BGQT1
HuMo-17B:https://go.hyper.ai/RSYA
Demo 运行
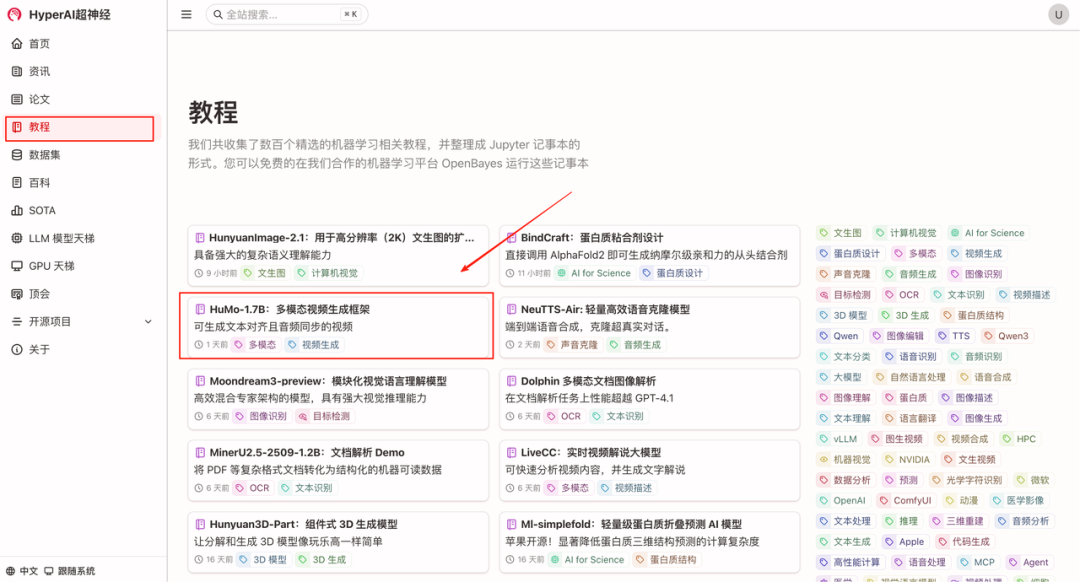
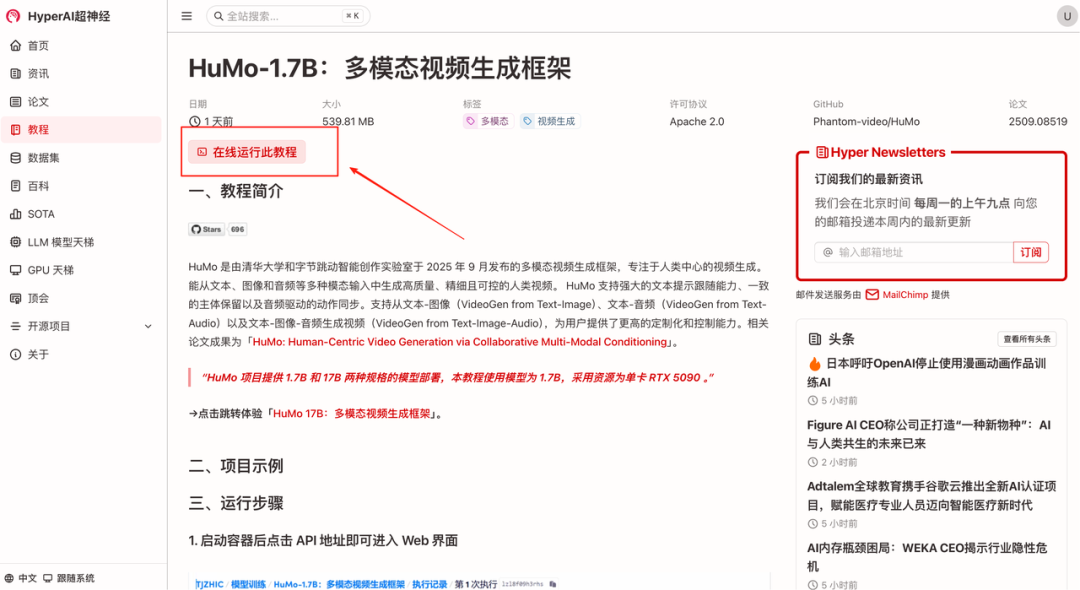
1. 进入 hyper.ai 首页后,选择「教程」页面,并选择「HuMo-1.7B:多模态视频生成框架」,点击「在线运行此教程」。
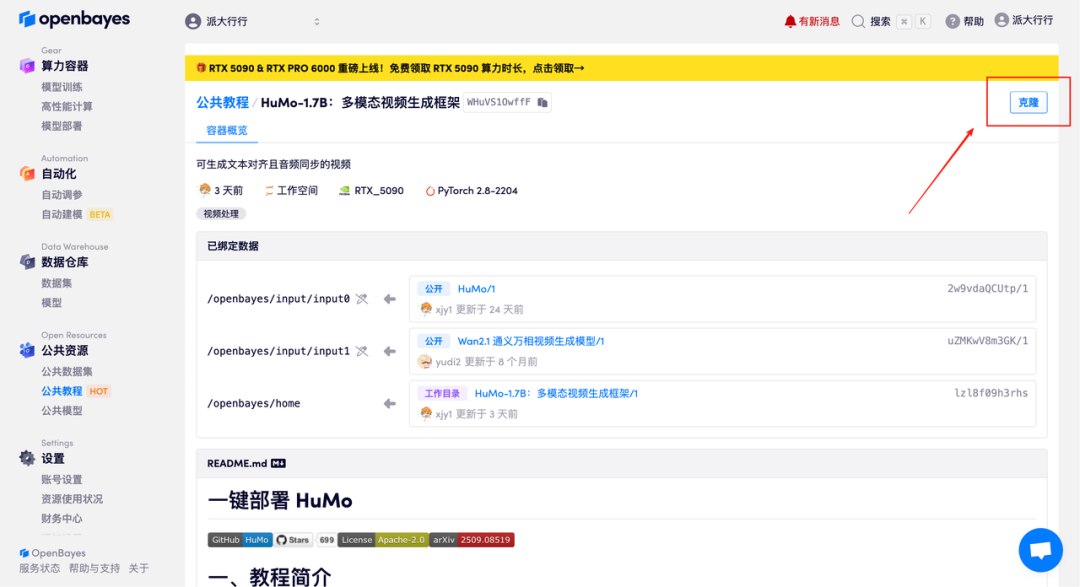
2.页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
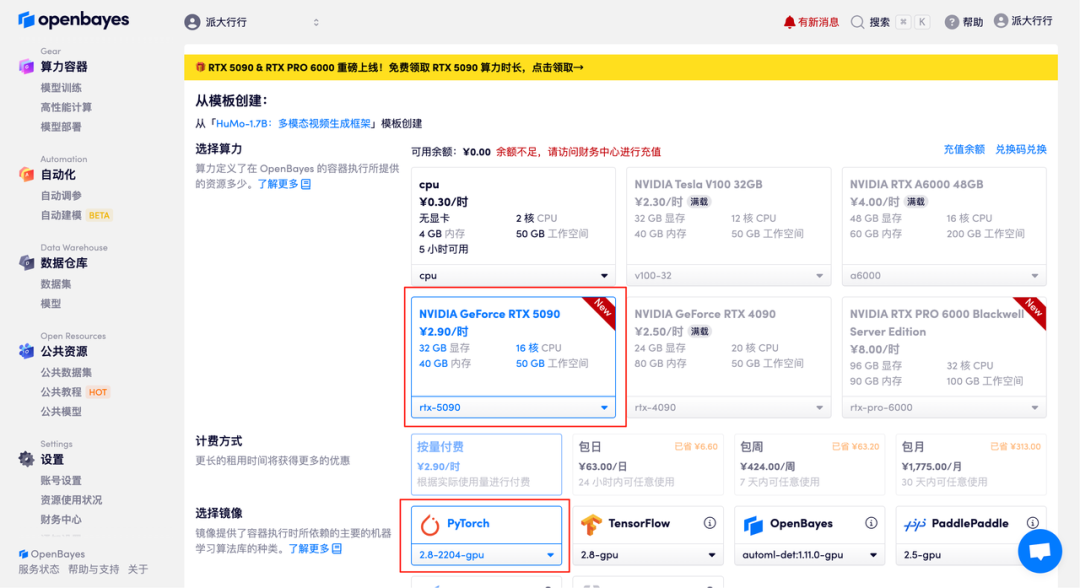
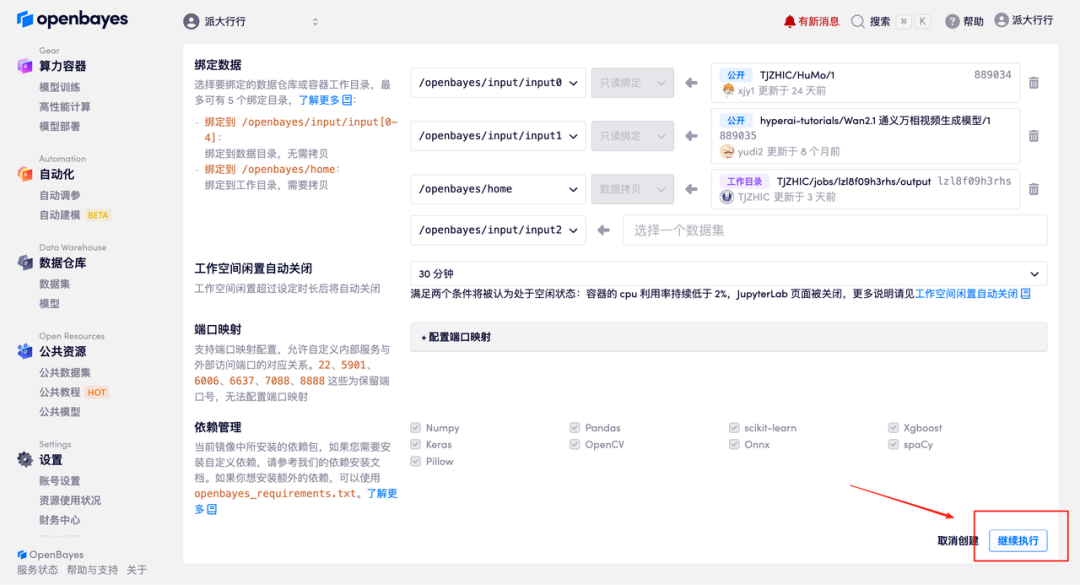
3. 选择「NVIDIA GeForce RTX 5090」以及「PyTorch」镜像,并点击「继续执行」。OpenBayes 平台提供了 4 种计费方式,大家可以按照需求选择「按量付费」或「包日/周/月」。新用户使用下方邀请链接注册,可获得 4 小时 RTX 5090 + 5 小时 CPU 的免费时长!
HyperAI超神经专属邀请链接(直接复制到浏览器打开):
https://openbayes.com/console/signup?r=Ada0322_NR0n
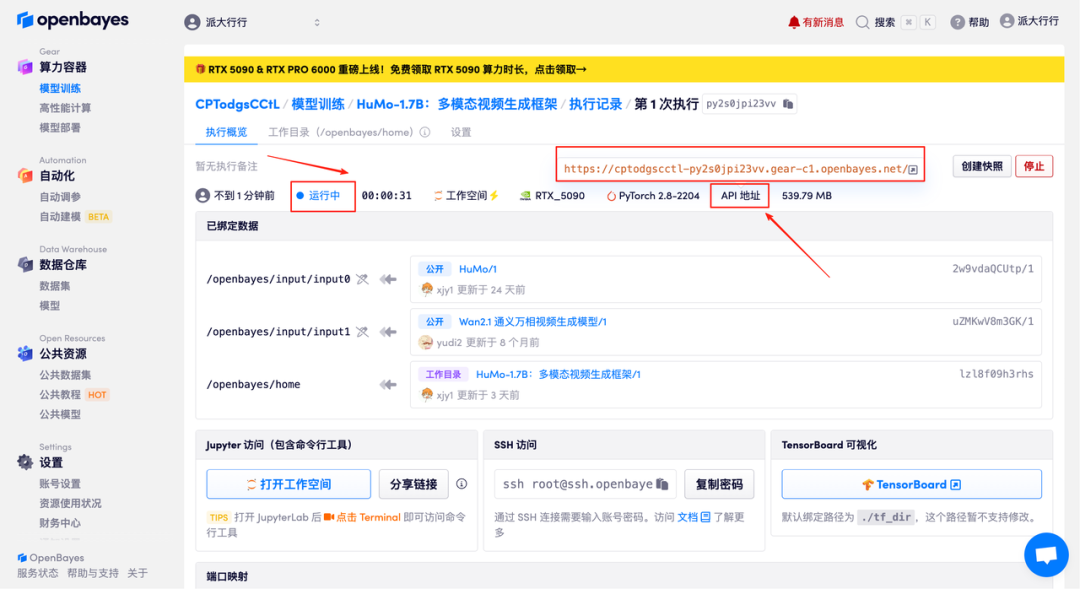
4.等待分配资源,首次克隆需等待约 2 分钟左右的时间。当状态变为「运行中」后,点击「打开工作空间」,即可跳转至 Demo 页面。
效果演示
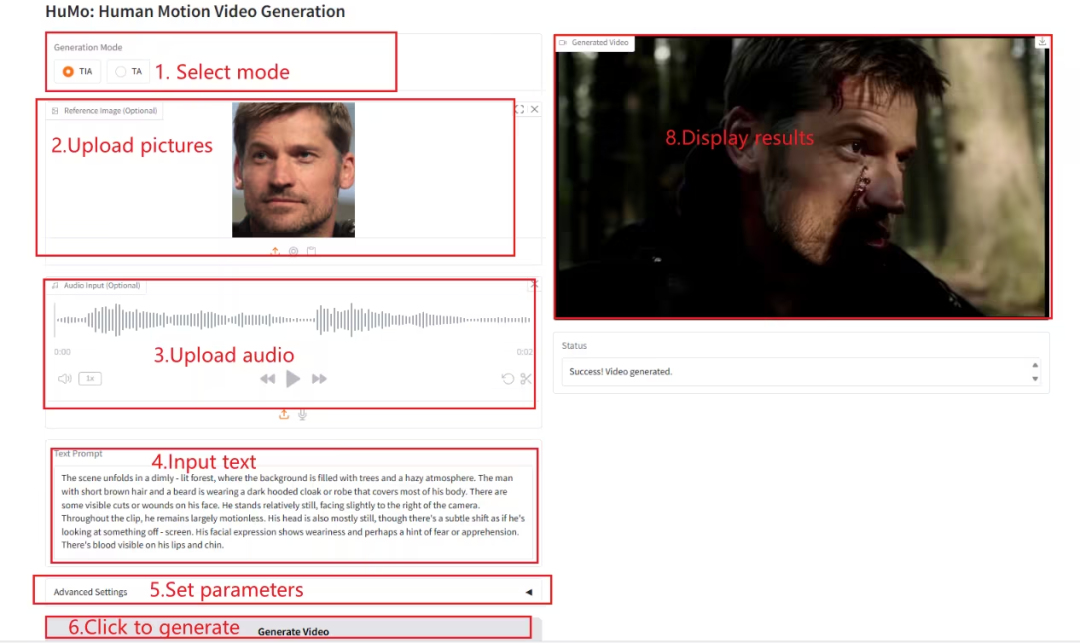
进入 Demo 运行页面后,在文本框内输入相关文字描述,并上传图片以及音频,根据需求调整相关参数,点击「Generate Video」即可生成视频。(注意:当 Sampling Steps 设置为 10 时,生成结果大约需要 3-5 分钟。)
生成示例
以上就是 HyperAI超神经本期推荐的教程,欢迎大家前来体验!
教程链接:
HuMo-1.7B:https://go.hyper.ai/BGQT1
HuMo-17B:https://go.hyper.ai/RSYA






戳“阅读原文”,免费获取海量数据集资源!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢