

大语言模型在模拟人类社会行为与互动方面展现出强大潜力,但在评估其与现实社会态度的一致性方面,仍缺乏大规模、系统化构建的基准。为弥补这一空白,我们提出SocioBench—一个基于国际社会调查计划(International Social Survey Programme,ISSP)收集的标准化调查数据所构建的综合基准。该基准汇集了来自30余个国家的超过48万条真实受访者记录,覆盖10个社会学领域与40多项人口统计学属性。我们对比了开源/闭源的20余个大模型在sociobench上的额表现的实验表明,大模型在严肃社会科学调查方面的存在三个局限性。(1)个体模拟精度不足:社会科学研究中的个体扮演能力不足,平均准确率仅为30-40%。(2)场景模拟能力有显著差异:大模型在社会不公、环境议题等领域的行为模拟表现显著低于其它领域。(3)区域模拟能力有显著差异:大模型对于非洲地区个体的模拟精度显著低于其它区域,包括亚洲、大洋洲等。
*本论文已被EMNLP 2025 录用为短文。
引言
随着大语言模型(LLM)在自然语言生成、认知行为模拟与复杂多轮对话等方面的持续进展,其在社会科学中的应用潜力日益凸显,可作为“计算智能体(Computational Agents)”来模拟人类行为与决策,从而支持因伦理、组织或经费限制而难以在真实世界场景中开展的社会实验与调查。在社会计算相关评测基准(Benchmark)中,既有研究多聚焦于个体层面的社会能力(如角色一致性、语言风格与人格特质等),或群体层面的任务(如社会推理、社会偏见识别与多智能体协作等)。然而,系统评测LLM对于模拟宏观社会态度与识别跨文化差异能力的工作仍相对缺乏。
为此,上海创智学院、复旦大学联合同济大学、浙江大学、上海交通大学构建了社会调查中的人类行为模拟基准SocioBench,这是一个规模宏大的、多社会学议题的、跨国际的社会计算评测基准。它建立在ISSP精心构造的标准化问卷及481,629条真实受访者调查记录之上,覆盖10个研究领域,包括“公民身份(Citizenship)”,“环境(Environment)”,“家庭与性别角色变迁(Family and Changing Gender Roles)”,“健康与医疗保健(Health and Health Care)”,“国家认同(National Identity)”,“宗教(Religion)”,“政府角色(Role of Government)”,“社会不平等(Social Inequality)”,“社交网络(Social Networks)”,“工作取向(Work Orientations)”。

Github地址:
https://github.com/JiaWANG-TJ/SocioBench.git
arxiv地址:
https://arxiv.org/abs/2510.11131
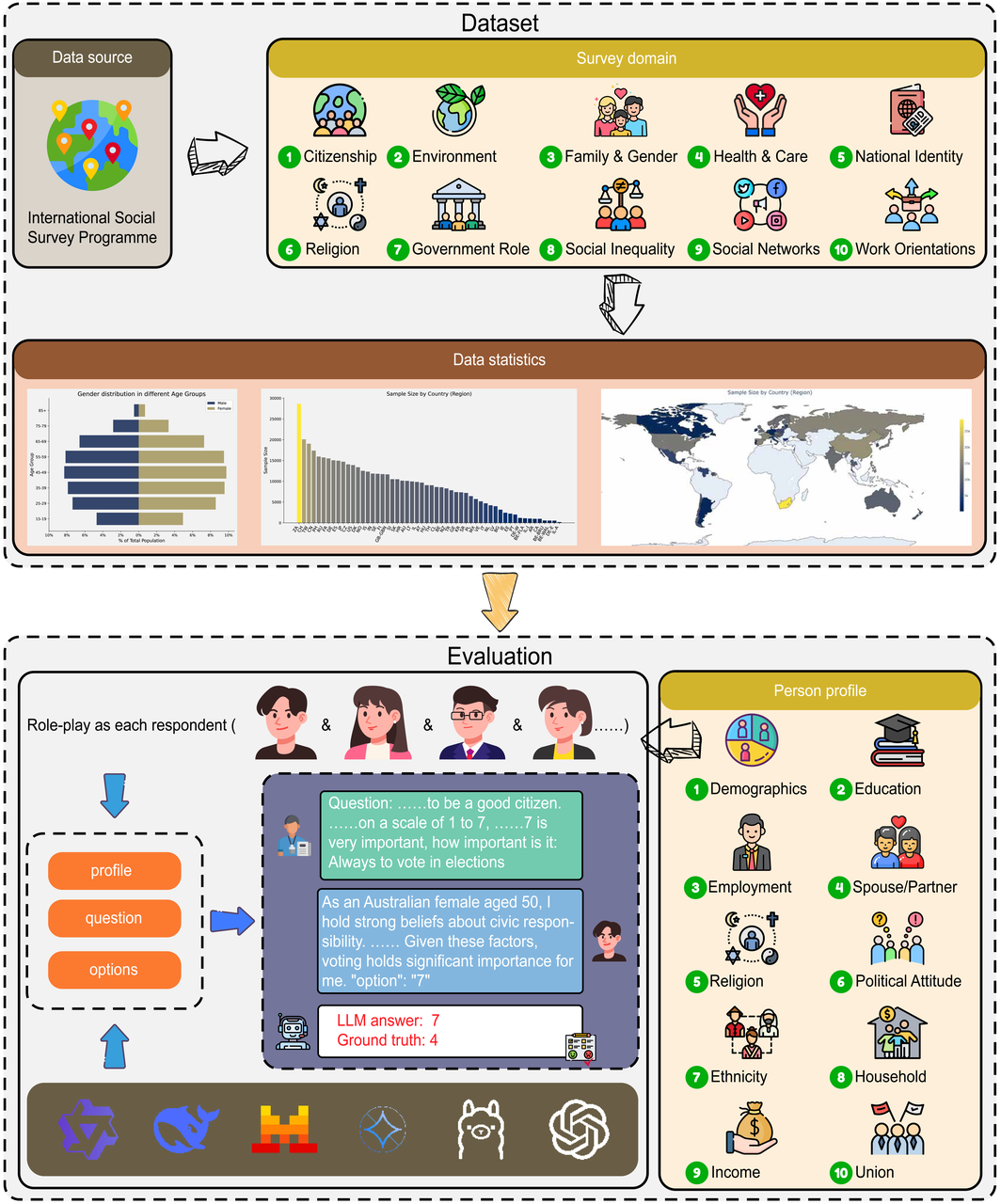
SocioBench:数据集
数据处理
SocioBench包含问卷Q&A、受访者的真实人口统计学标签以及问卷作答两部分数据集。数据处理流程包括两步:首先,过滤开放式问题与无效作答选项(例如“Not applicable”),以仅保留可量化的封闭式问题。然后,采用两阶段抽样方案抽取1%的数据(先按国家进行分层抽样,再在各国范围内进行随机抽样),以在计算资源约束与调查覆盖度之间取得平衡。
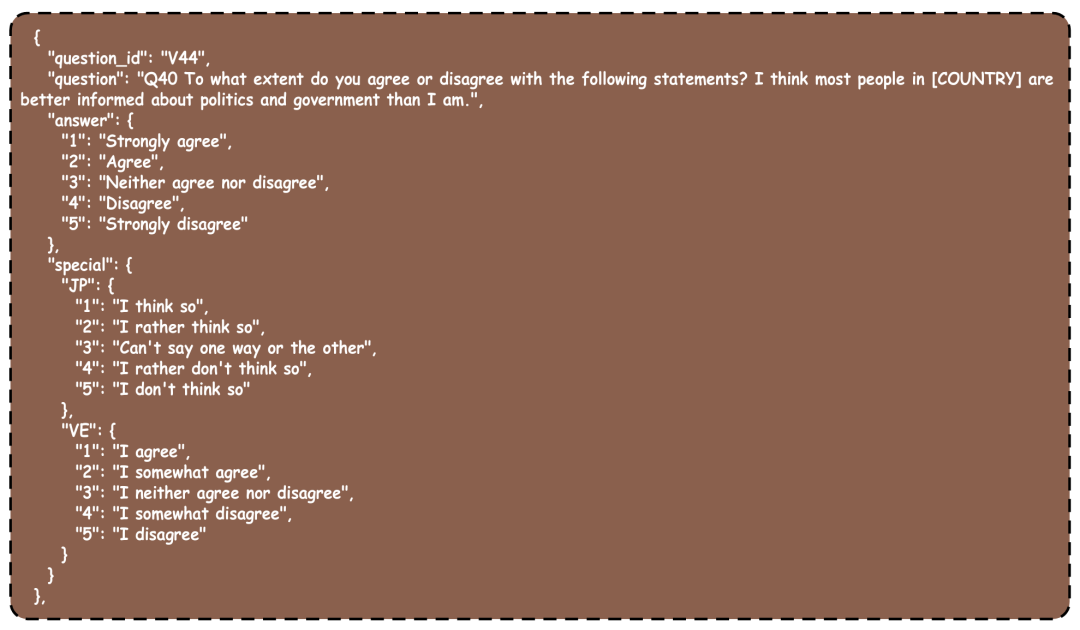
SocioBench数据示例:社会调查问卷Q&A示例

SocioBench数据示例:真实人口统计学标签以及问卷作答
数据统计
SocioBench构建基于ISSP,这是一个历史悠久的跨国合作项目,由GESIS (Leibniz Institute for the Social Sciences,莱布尼茨社会科学研究所)每年收集标准化的社会态度数据。SocioBench覆盖30余个国家的10个社会学议题,共包含481,629份受访者记录。为提高评测效率,实验采用约1%采样的子样本(5,000名受访者)。每位受访者关联40余项人口统计学特征,包括年龄、性别、受教育程度、职业、收入、宗教信仰与政治取向等,从而支持多维度的子群分析。
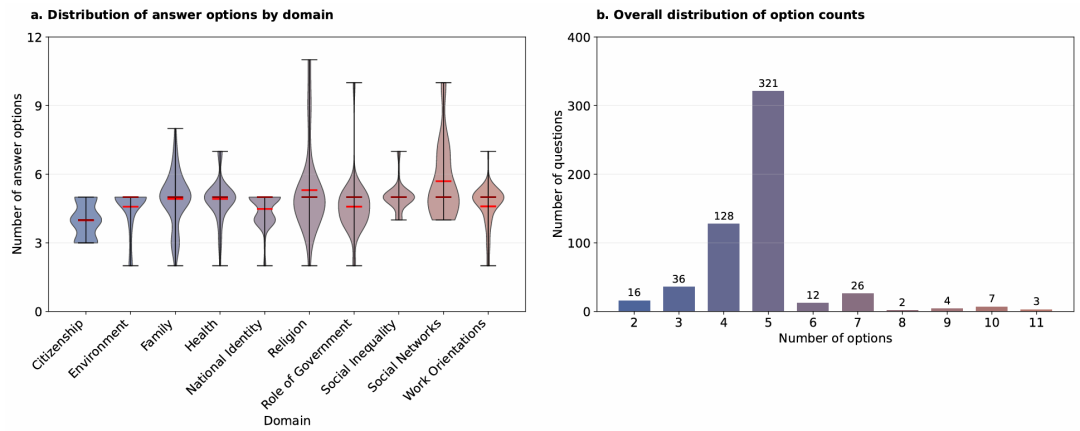
社会调查问卷Q&A分布统计
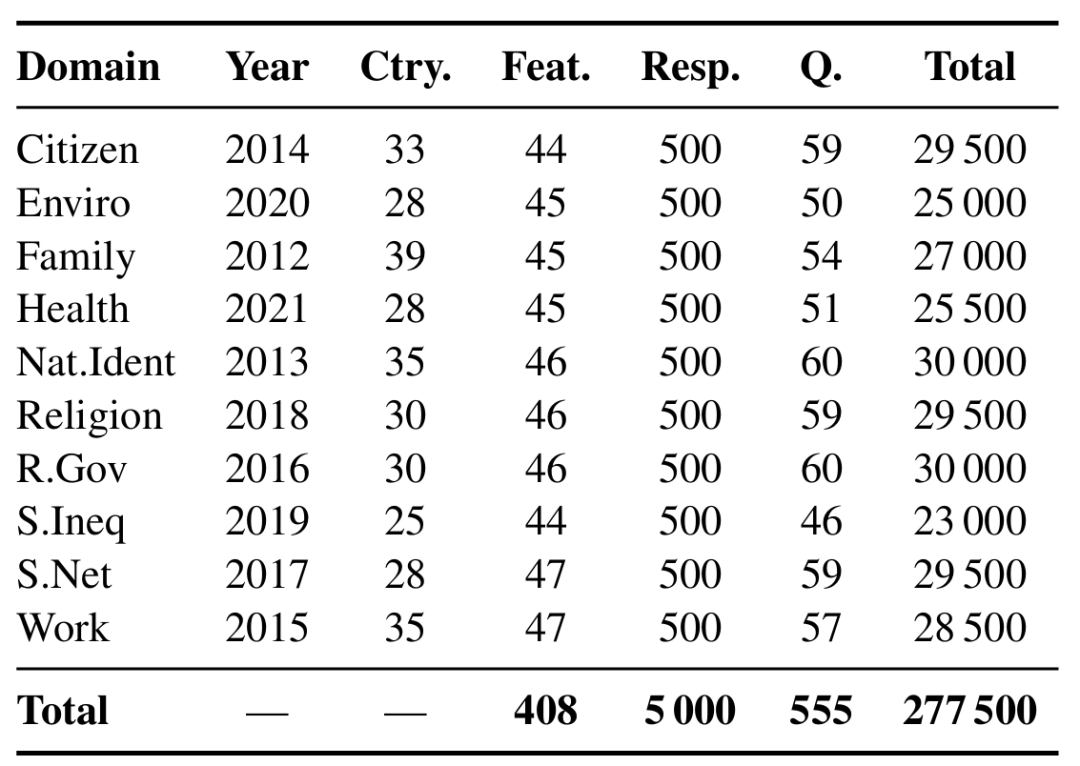
受访者档案信息与问卷信息统计情况
SocioBench:评测实验
实验设置
评测流程:
评测流程是让LLM进行角色扮演,仅基于prompt之中传入的人口统计学信息来对社会调查问卷作答(例如,“您是一位 31 岁的澳大利亚女性,已完成高中至 10 年级的教育,有伴侣,无宗教信仰,并且是澳大利亚裔(您出生于澳大利亚,父母也出生于澳大利亚)…………”。然后让LLM输出答案选项和作答理由,并基于真实受访者的答案选项与LLM输出的答案选项计算准确率并作为评测指标。
评测模型:
实验覆盖广泛的开源模型与闭源模型,包括GPT-4o、Qwen 2.5系列(Qwen2.5-7B-Instruct、Qwen2.5-32B-Instruct、Qwen2.5-72B-Instruct);Qwen 3系列(Qwen3-8B、Qwen3-32B);Llama 3系列(Llama-3.1-8B-Instruct、Llama-3.3-70B-Instruct);GLM-4-9B;DeepSeek-R1-Distill-Llama-70B;Gemma-3-27B-it;Mistral系列(Mistral-7B-Instruct-v0.3、Mixtral-8x22B-Instruct-v0.1);InternLM3-8B-Instruct。
实验结果
总体实验结果
1. 在模拟复杂社会调查场景中的个体行为时,LLM的准确率通常仅在30%至40%之间。这一结果表明了当前LLM对个体层面的建模能力不足、数据缺失。
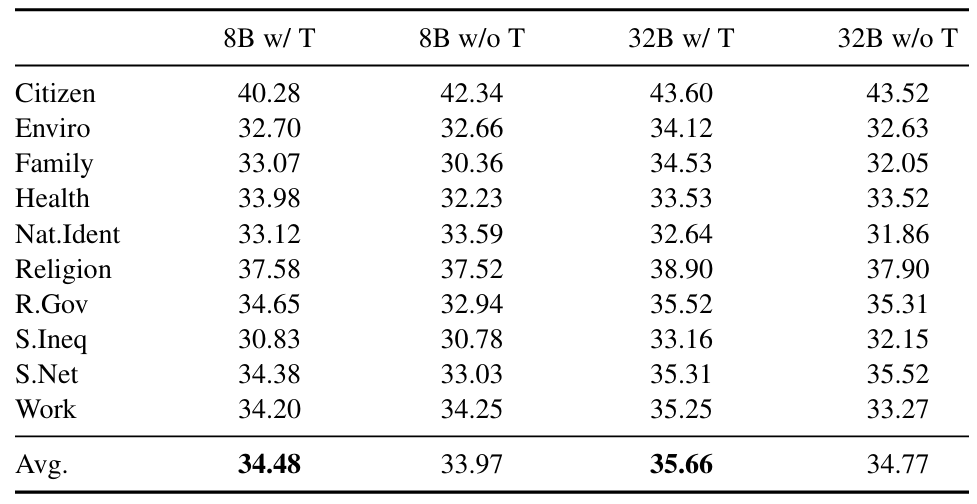
2. 模型的性能随着参数规模的增大而提升。例如,在Qwen2.5系列模型中,Qwen2.5-7B-Instruct、Qwen2.5-32B-Instruct和Qwen2.5-72B-Instruct的平均准确率分别为33.35%、36.03%和37.24%。
3. 在不同的模型家族之中,GLM-4-9B-chat、Qwen2.5-32B-Instruct和DeepSeek-R1-Distill-Llama-70B分别在参数规模小于10亿、约30亿和约70亿的类别中表现最佳,其平均准确率分别为35.60%、36.03%和38.52%。
4. 不同领域模型的性能差异显著。例如,在“Citizenship”领域,模型准确率最高可达44.30%,但在“Health and Health Care”领域仅为36.16%。且这一趋势广泛地出现在不同模型中,可能是LLM预训练语料库中数据分布不均衡造成的。某些领域数据缺失导致模型在处理相关内容时,其语义理解能力存在差异。
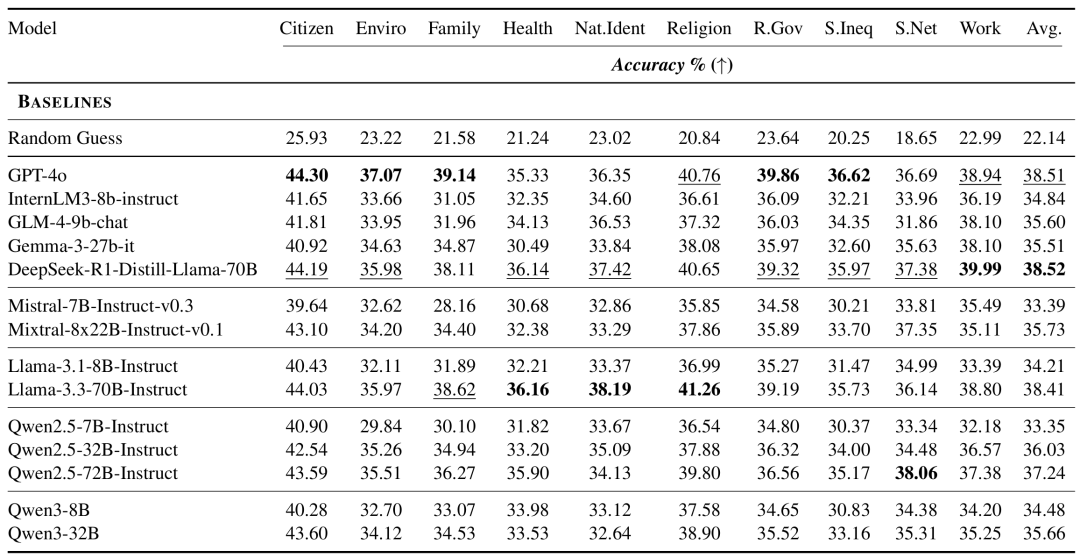
亚组分析
大洲亚组分析结果:我们选择“Religion”和“Social Inequality”两个领域开展了分析。具体而言,与欧洲、北美和澳大利亚的受访者相比,LLM在模拟非洲受访者行为时的准确性普遍较低,这反映出模型性能与区域经济发展程度、模型训练语料之间的关联。
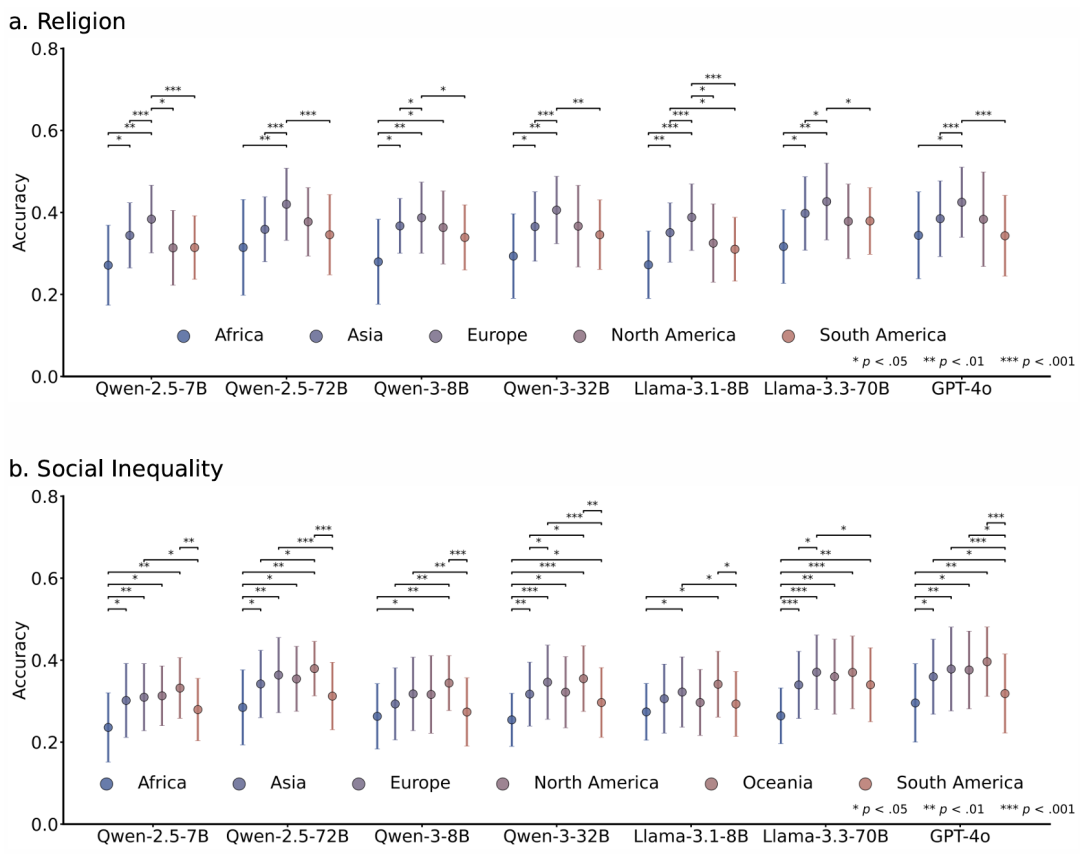
性别亚组分析结果:我们对“Citizenship”和“Family”这两个领域开展了分析,发现女性角色扮演的准确性始终高于男性角色扮演的准确性—在“Citizenship”领域分别为43.04%±1.72%(均值±标准差)和41.87%±1.97%,在“Family”领域分别为35.50%±3.29%和34.09%±3.55%,这些结果反映了训练语料库的数据不平衡,即在某些社会领域,女性角色具有更清晰的语义关系。
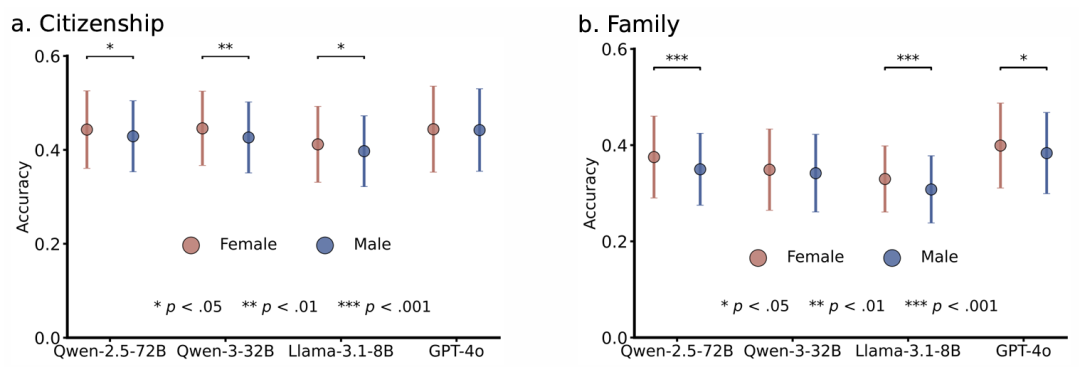
年龄亚组分析结果:我们对“Role of Government”和“Social Networks”这两个领域开展了分析,发现在“Role of Government”领域,56-65岁年龄段的准确性,为37.52%±2.27%显著高于其他年龄段;而在“Social Networks”领域,66岁及以上年龄段的准确性,为37.91%±1.45%,始终优于18-25岁(35.13%±2.21%)和36-45岁(35.43%±2.21%)等年轻年龄段。结果表明,这些领域与中老年群体关系更密切,或者他们的社交网络和政治参与度更高,从而使得模型能够更准确地模拟这些群体。
深入实验结果
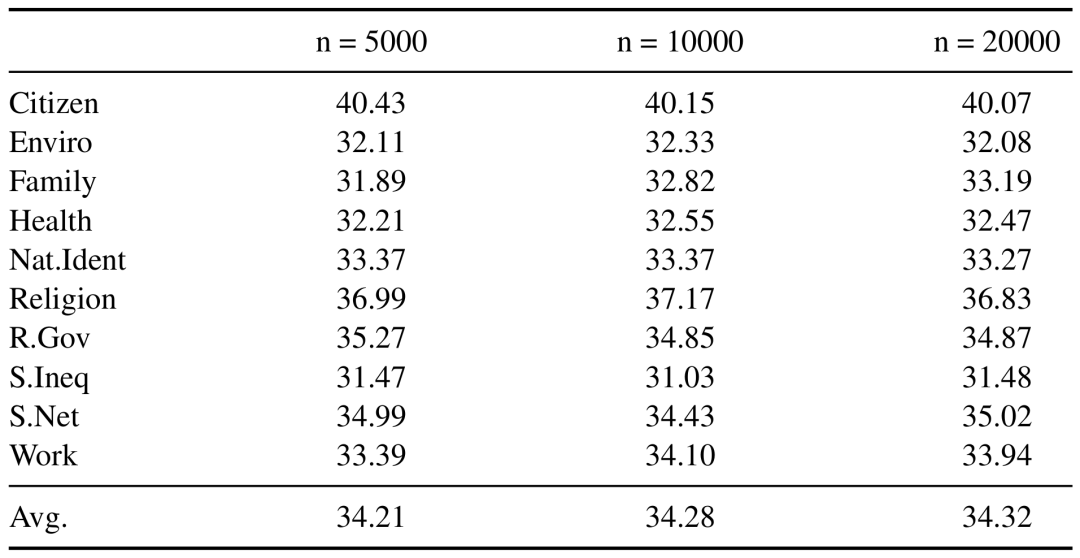
不同采样比例对比:为了评估模型在不同数据规模下的鲁棒性,我们进一步从完整数据集中采样了2%和4%,构建了两个子数据集:SocioBench-10000和SocioBench-20000。在SocioBench-5000、SocioBench-10000和SocioBench-20000这三个数据集上,Llama-3.1-8B-Instruct模型分别达到了34.21%、34.28%和34.32%的平均准确率,最大偏差低于0.11个百分点。这些结果表明,使用相对较小的数据样本,SocioBench也能获得相对稳定可靠的评测结果。
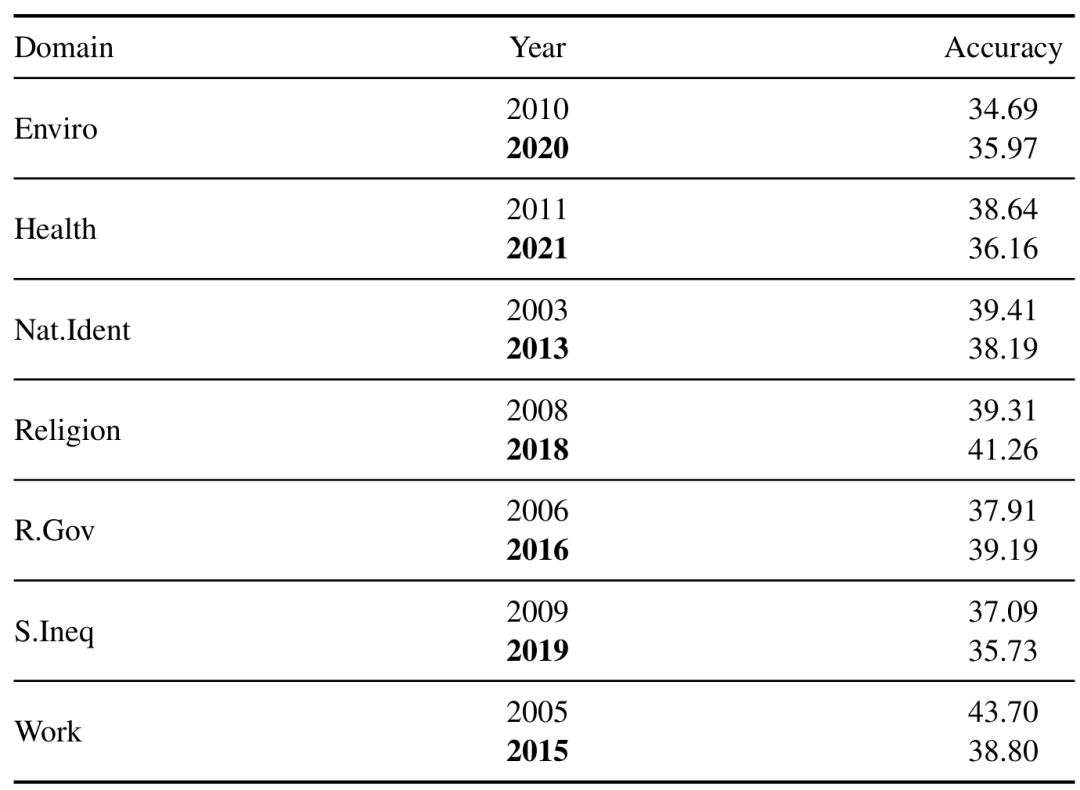
不同调查轮次对比:由于ISSP通常每年会选择一个主题开展调查,且一般以十年为周期重复对一个领域开展调查,因此我们基于Llama-3.1-8B-Instruct进行了额外的大规模实验,以比较同一主题下不同年份调查结果对基准结果的影响。结果表明,各个领域下两轮调查结果之间的评测结果在时间范围上无明显的规律,准确率变化大多为1-2个百分点,表明评测结果受到特定领域中的调查问卷结构的影响更大,而不是调查轮次的影响。
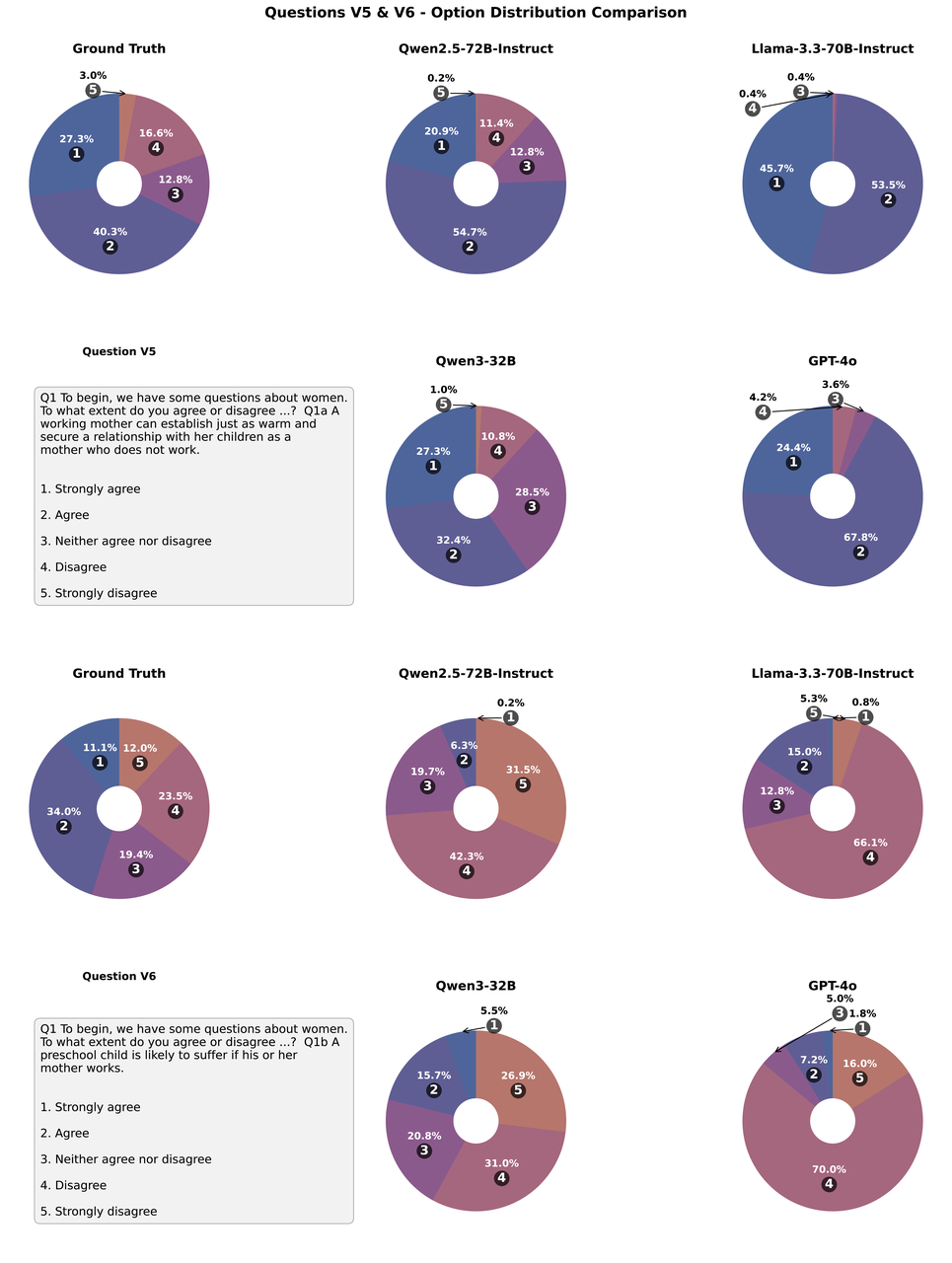
LLM与真实受访者回复中的选项分布情况对比:结果表明,虽然真实数据呈现出偏态分布(即选项集中在某些类别中),但LLM生成的回复使得这种不均衡现象更加明显,特别是Llama-3.3-70B-Instruct,而Qwen3-32B生成的选项分布相对更加均衡。
END
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区计算中心

点击“阅读原文”跳转至Github
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢