
OnePoseViaGen无需物体模型估计精确位姿
助力真实机械臂精细抓取任务
随着具身智能的快速发展,机器人在诸如物品搬运、家务整理等常规任务中已展现出令人瞩目的自主能力。然而,对于空间感知和操作精度要求较高的任务,比如“抓取一个从未见过的充电枪并插入插槽”,现有系统的成功率仍严重受限。其核心障碍在于,机器人难以获得物体在三维空间中的精准位姿(6D pose)与真实尺度(metric scale),尤其是在缺乏预设3D模型、仅有单视角观测的开放环境下。
传统6D位姿估计方法大多依赖高质量CAD模型或多视角重建,难以满足动态、实时的实际需求。现有的单张图像推理方法则普遍受限于尺度、外观和姿态的模糊性。正因如此,尽管近年来视觉-语言-动作(VLA)模型在宽容度较高的任务中取得进展,但在毫米级精度的操作场景中,感知—控制链条仍难以闭合,制约了机器人通用操作能力的进一步提升。
针对这一挑战,北京智源人工智能研究院(BAAI)可控世界模型创新中心赵昊团队提出了OnePoseViaGen:该方法无需预设 3D 模型,仅依赖单张RGBD参考图像,即可在未知物体上实现高精度 6D 位姿估计。相关论文 “One View, Many Worlds: Single-Image to 3D Object Meets Generative Domain Randomization for One-Shot 6D Pose Estimation” 入选 CoRL 2025 Oral。
实验结果显示,OnePoseViaGen 在多个国际权威基准上显著优于现有主流方法,并在真实机械臂精细抓取任务中实现了73.3%的成功率,刷新了领域纪录。
这项工作首次验证了生成式AI在三维结构推理和机器人操作感知中的协同潜力,推动机器人从“看得见”迈向“看得准、抓得稳”,为家庭服务、智能制造等复杂场景的泛化操作能力开辟了全新路径。
1
OnePoseViaGen:
三步破解“一眼识物”难题
要让机器人仅凭“第一眼”就精准理解一个从未见过的物体,系统必须同时突破三个技术瓶颈:
缺乏3D模型:如何在没有现成CAD数据的情况下重建物体结构?
尺度未知:如何确定物体的真实尺寸(大小)?
虚实差异:生成的模型和现实不一样如何应对?
针对上述挑战,赵昊团队提出了“建模 → 对齐 → 适配”三阶段框架,逐步突破单样本6D位姿估计的核心瓶颈。
首先要明确任务的核心定义:已知单张 RGB-D 锚点图像和查询图像,需估计物体从坐标系到坐标系的相对刚性变换(包含旋转R和平移t),同时需确定尺度因子s,将生成的标准化模型校准到真实世界尺度。
这一定义直接决定了后续方法需同时解决 “模型生成” “尺度—位姿对齐”和“域适配” 三个关键问题。
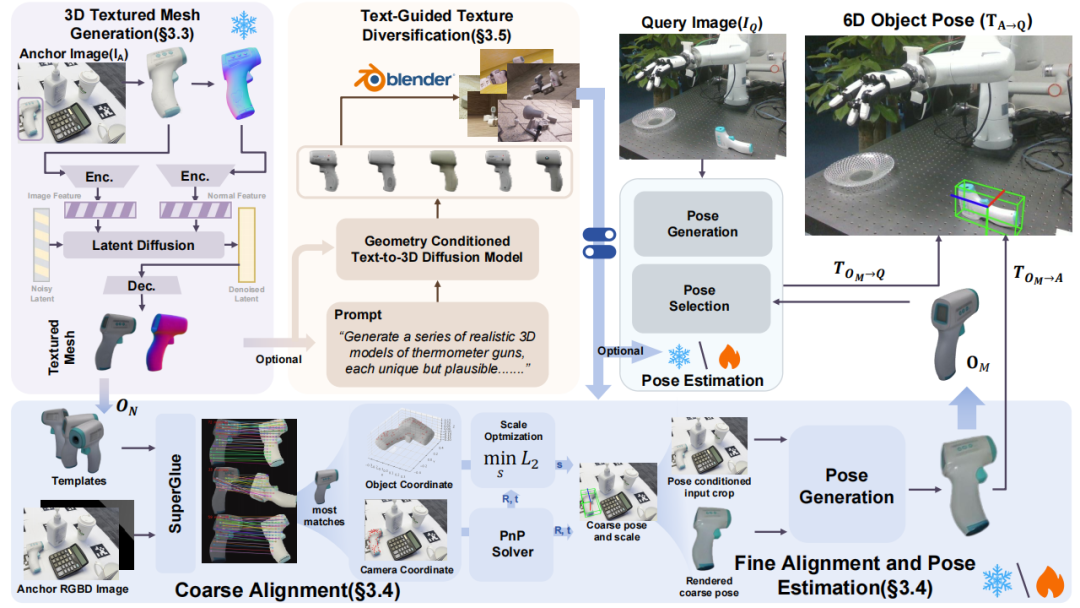
OnePoseViaGen“建模 → 对齐 → 适配”三阶段框架,
逐步突破单样本6D位姿估计的核心瓶颈
第一步:单图生成三维模型 —— 解决“无模可用”难题
传统方法依赖预先扫描的高精度CAD模型,但在真实世界中,绝大多数物体都没有现成的3D数据。OnePoseViaGen创新地采用生成式方法,让AI“脑补”出物体的完整三维结构。
具体而言,系统以一张RGB-D图像作为输入(即“锚点图像”),首先进行前景分割,去除背景干扰;随后利用法向量预测技术提取物体表面几何信息,引导改进版Hi3DGen模型生成一个高保真的标准化3D纹理网格——这相当于给陌生物体快速构建了一个“数字孪生体”,尽管它尚未与真实世界对齐。
第二步:粗到精联合对齐 —— 还原真实尺度与姿态
有了3D模型,下一步是将其“摆”在正确的位置和方向上,并还原真实尺寸。由于生成模型是归一化尺度的,直接使用会导致严重偏差。为此,团队设计了一套粗到精的联合迭代优化策略,将尺度恢复融入端到端位姿估计流程,先快速初始化位姿(粗对齐),再通过迭代优化最终达到毫米级精度(精对齐)。
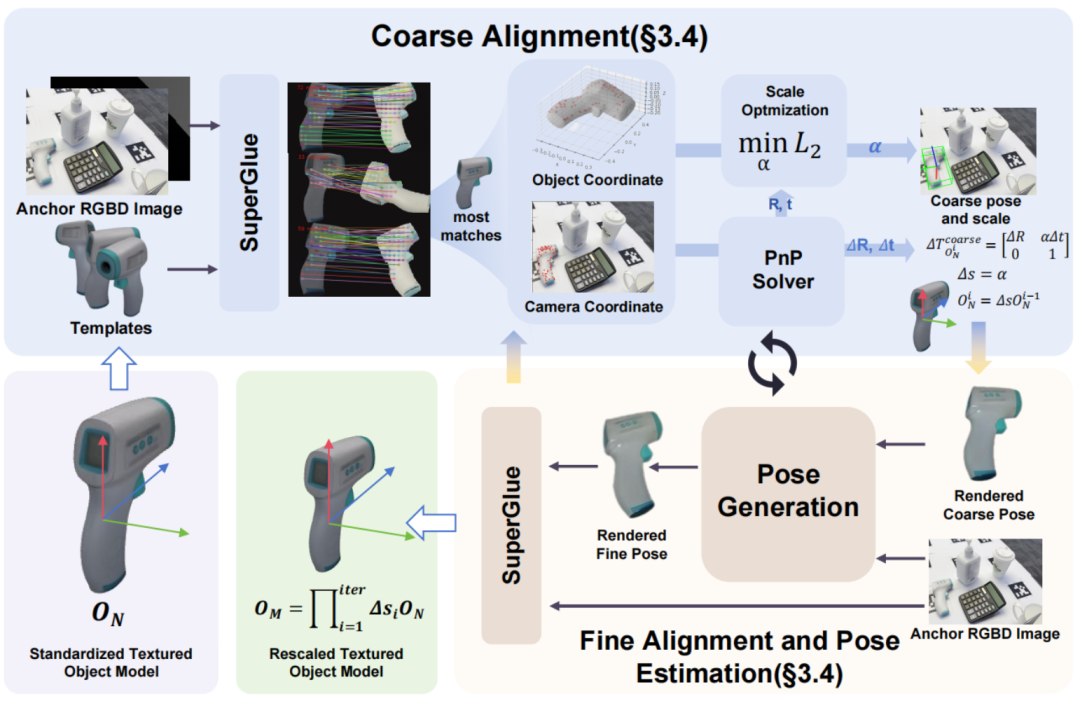
由粗到细的循环对齐策略,在一步步优化尺度和
位姿更新中逐步得到精确的物体尺度与位姿
第三步:文本引导生成式域随机化 —— 让AI学会应对现实复杂性
生成的3D模型再逼真,也只是“理想状态”。真实环境中,光照变化、材质差异、遮挡和噪声都会导致模型与实际图像之间存在巨大“域差距”。
为此,团队提出文本引导的生成式域随机化(Text-guided Generative Domain Randomization),融合自然语言描述与生成式建模,自动生成无限多样化的训练样本,涵盖丰富纹理、背景和环境变化。

使用多样化纹理模型生成的数据集,包含了丰富的背景、物体姿态、遮挡关系以及光照条件的变化,有助于缩小训练数据与真实世界场景之间的域差距
2
基准评测与真实操作的
系统性验证
OnePoseViaGen在主流公开基准与实际机器人操作中均实现了显著的性能飞跃,系统性验证了其技术创新与应用潜力。
基准数据集全面领先
OnePoseViaGen在多个知名的数据集上,包括YCBInEOAT、TOYL和LM-O,均展现出了显著的性能提升,特别是在处理高挑战场景时。
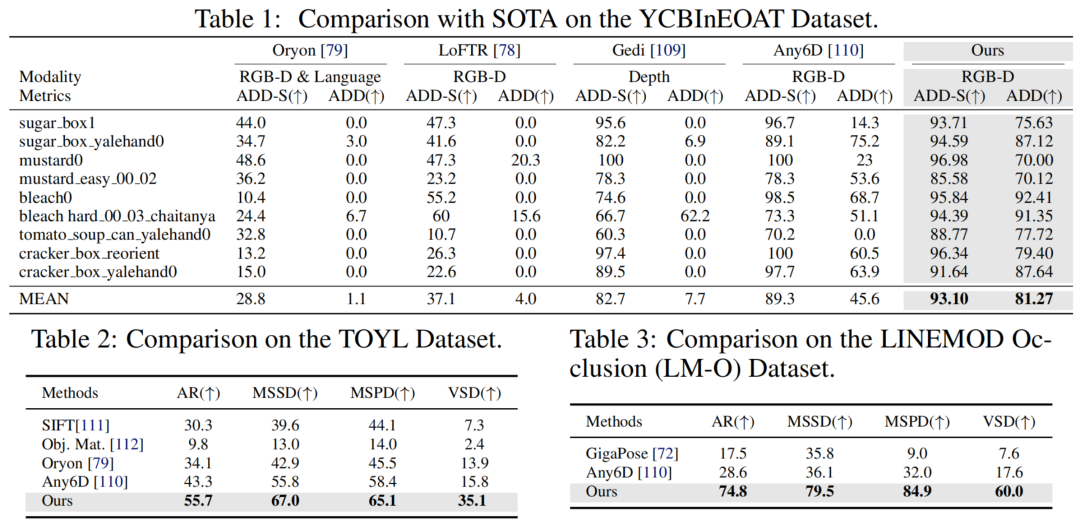
YCBInEOAT 数据集:OnePoseViaGen在ADD和ADD-S指标上平均分别达到了81.27%和93.10%,远超其他方法如Oryon(1.1%)、LoFTR(4.0%)等。
TOYL 数据集:专注于复杂光照和远距离挑战,OnePoseViaGen在所有BOP指标上领先,例如AR指标达到55.7%,比次优方法高出至少12.4个百分点。

TYOL 定性结果直观展示了性能:红色 / 绿色 / 蓝色线为模型坐标轴,粉色线为估计位姿的渲染轮廓,可见即使物体在背景光照变化剧烈的情况,渲染轮廓仍与真实物体边缘高度重合,验证了方法的抗遮挡能力
LM-O 数据集:针对高遮挡无纹理场景,OnePoseViaGen同样表现出色,整体AR达到了74.8%,超越了GigaPose和Any6D等多个竞争对手。

LM-O 定性结果直观展示了性能:红色 / 绿色 / 蓝色线为模型坐标轴,粉色线为估计位姿的渲染轮廓,可见即使物体被严重遮挡(如 “driller” 被盒子遮挡),渲染轮廓仍与真实物体边缘高度重合,验证了方法的抗遮挡能力
真实机器人操作的端到端验证
为评估实际应用价值,智源团队在真实机械臂平台上借助估计物体位姿开展了单臂抓取-放置与双臂交接两类任务。
OnePoseViaGen实现了73.3%的成功率,远高于基线方法SRT3D(6.7%)和DeepAC(16.7%),充分证明了其对复杂物体和场景的泛化能力。

实验过程:左列为锚点图像,中列为生成的 3D 模型,右列为机器人抓取时的位姿估计结果,可见生成的模型与真实物体纹理、结构高度一致,估计的位姿能精准指导机械臂抓取
3
从“被动感知”
到“主动理解”的探索
OnePoseViaGen 以“单图3D生成+联合对齐+域适配”创新范式,为机器人在无模型、单样本、复杂场景下的精确感知与鲁棒操作带来了新的可能。我们相信,这一工作不仅是对现有技术瓶颈的突破,也是对机器人认知方式的一次有益探索。
当先验信息缺失(如无CAD模型、无多视角数据)时,系统不再被动等待理想输入,而是主动“生成-对齐”,利用生成式 AI 补全物体的完整3D结构,并通过几何与尺度的联合优化,将其精准锚定在真实空间中。
生成式模型不仅可以用于内容创作,也能转化为机器人执行物理交互所必需的精确几何与度量信息。这种“以生成赋能感知”的思路,为应对机器人领域长期存在的“长尾物体”难题——如何应对海量未知、非标、罕见物体——提供了可扩展的技术路径。
作为智源 RoboBrain 具身智能愿景的关键一环,OnePoseViaGen 正在推动“感知—决策—执行”一体化智能闭环的构建,让机器人不止于“看见”,更能“看懂”、“会用”。
我们期待与全球同行携手,持续推进生成式 AI 与机器人系统的深度融合,进一步拓展机器人在家庭、工业、应急等真实场景中的能力边界,共同迈向自主、通用的具身智能。
欢迎访问项目主页,获取代码和更多信息:
One View, Many Worlds: Single-Image to 3D Object Meets Generative Domain Randomization for One-Shot 6D Pose Estimation [CoRL 2025 Oral]
论文链接:https://arxiv.org/abs/2509.07978
项目主页:https://gzwsama.github.io/OnePoseviaGen.github.io
阅 读 更 多

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢