
【论文标题】Extracting Training Data from Large Language Models
【作者团队】Nicholas Carlini, Florian Tramèr, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Úlfar Erlingsson, Alina Oprea, Colin Raffel
【发表时间】2020/12/14
【论文链接】https://arxiv.org/pdf/2012.07805.pdf
【推荐理由】本文来自谷歌、斯坦福、UC伯克利等机构。如今发布基于私有数据集训练的大型(十亿级参数)语言模型已经非常普遍。本文证明,在这种情况下,攻击者可通过查询语言模型,进行训练数据提取攻击,恢复单个训练样本。
本文演示了对GPT-2的攻击,GPT-2是基于公共互联网上的碎片训练的语言模型,通过攻击能提取出训练数据中数百个逐字文本序列。这些提取的样本中包括(公开的)个人身份信息、IRC对话、代码和128位UUID。文中对提取攻击进行全面评估,以了解导致其成功的因素。例如,较大的模型比较小的模型更容易受到攻击。该工作为大型语言模型的训练和发布敲响了警钟,说明在敏感数据上训练大型语言模型可能存在的隐患,同样的技术也适用于其他所有语言模型。由于随着语言变得更大,记忆的情况会变得更糟,预计这些漏洞将在未来变得更加重要。用差分隐私技术进行训练是一种缓解隐私泄露的方法,然而,有必要开发新的方法,可以在这种极端规模(例如,数十亿参数)下训练模型,而不牺牲模型精度或训练时间。更普遍的是,有许多开放性问题,有待将进一步研究,包括模型为什么记忆,记忆的危险,以及如何防止记忆等。 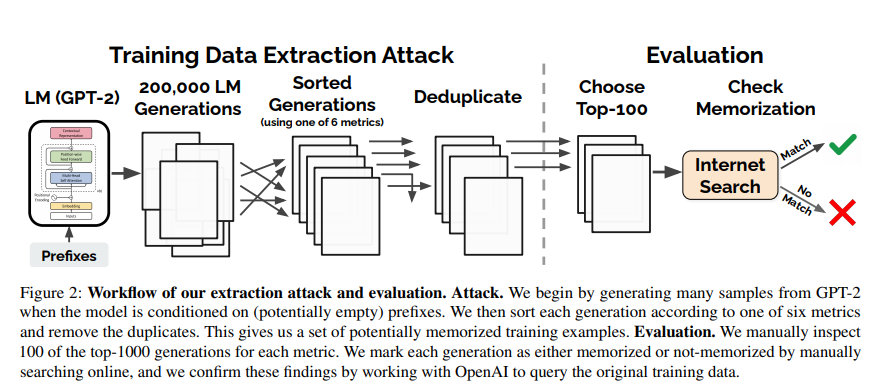
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢