
EMNLP(Empirical Methods in Natural Language Processing)是计算语言学和自然语言领域的顶级国际学术会议之一,是由计算语言学协会(ACL)下属的语言数据特别兴趣小组(SIGDAT)主办。2025年,这场全球 NLP盛会首次落地中国苏州,将于11月4日-11月9日在苏州国际博览中心举办。届时,来自学术界与工业界的顶尖研究者、工程师与创新者将齐聚一堂,共同探讨语言智能的最新突破与未来方向。
今年,淘天集团将深度参与本次盛会,不仅有多篇高质量论文被接收,涵盖大语言模型、模型幻觉、复杂指令遵循等热门方向,还有专属展台,带来最新技术成果展示、产品互动体验,以及与核心研发团队面对面交流的机会,更有机会在现场直通面试,与我们共创未来!
📍 展台位置:C3厅 4号展位
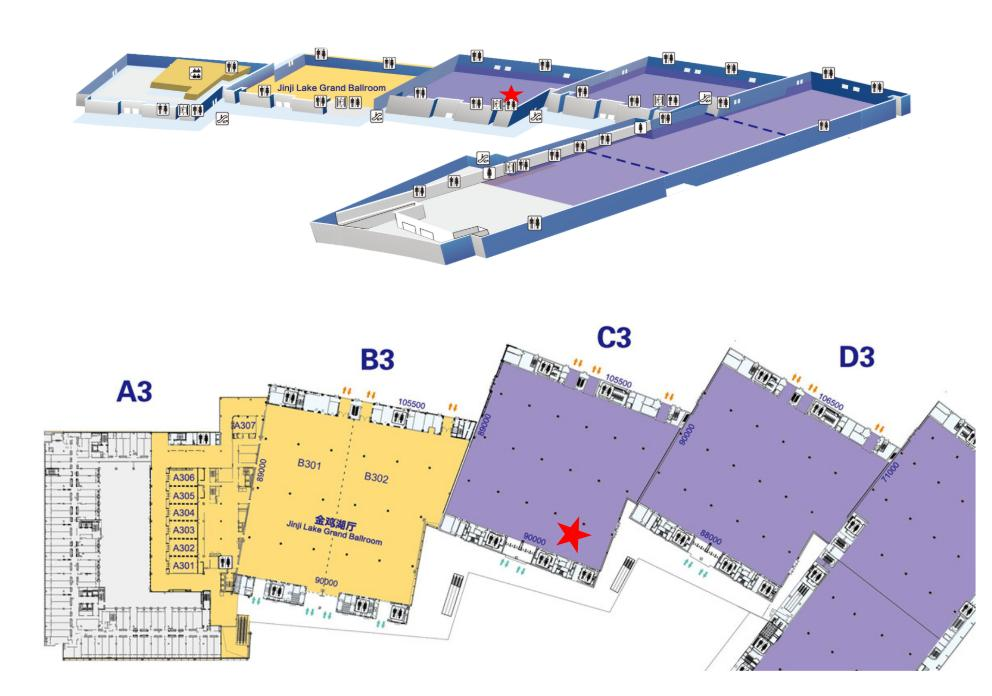
🎁展台现场会有惊喜周边福利大放送哦,先到先得!
📘部分Poster论文展示
《SMEC:Rethinking Matryoshka Representation Learning for Retrieval Embedding Compression》
所在团队:淘天集团算法技术团队
大型语言模型(LLMs)生成的高维嵌入(embeddings)能够捕捉丰富的语义和句法信息,广泛应用于文本分类、检索、推荐系统等下游任务。然而,高维嵌入(embeddings)带来了显著的计算开销和存储压力,限制了其在资源受限场景下的实际部署。为此,淘天-商品价格力&营销算法团队提出了串联式俄罗斯套娃嵌入压缩框架(SMEC),用于高效压缩高维嵌入。该框架包含三个核心组件:一是串联式俄罗斯套娃表征学习(Sequential Matryoshka Representation Learning, SMRL),通过串行训练策略降低梯度方差,提升收敛速度与模型性能;二是自适应维度选择(Adaptive Dimension Selection, ADS),动态识别重要维度,缓解传统截断方式带来的信息损失;三是可选跨批次记忆(Selectable Cross-batch Memory, S-XBM),增强高低维嵌入间的无监督对齐能力。在图像、文本和多模态数据集上的实验表明,SMEC 在保持性能的同时实现了显著的降维。例如,在BEIR 数据集上,与 Matryoshka-Adaptor 和 Search-Adaptor 模型相比,该方法分别将压缩的 LLM2Vec 嵌入(256 维)的性能提高1.1个百分点和2.7个百分点。
Poster Session:Hall C,Session 11
Session Time:11月6日,16:30-18:00
《AIR:Complex Instruction Generation via Automatic Iterative Refinement》
所在团队:未来生活实验室
随着大型语言模型的发展,其遵循简单指令的能力显著提升。然而,如何遵循复杂指令仍然是一项重大挑战。目前生成复杂指令的方法通常与当前的指令需求不相关,或者在可扩展性和多样性方面存在局限性。此外,诸如反向翻译等方法虽然在生成简单指令时有效,但未能充分利用大型网络语料库中的丰富内容和结构。本文提出了一种新颖的自动迭代细化框架AIR(Automatic Iterative Refinement),用于生成带约束的复杂指令,这不仅更好地反映了实际场景的需求,而且显著增强了LLMs(大型语言模型)执行复杂指令的能力。AIR框架包含两个阶段:(1)从文档中生成初始指令;(2)通过将模型输出与文档进行比较,并在LLM作为评判者的指导下迭代地细化指令,以纳入有价值的约束条件。最后,我们构建了含有10000个复杂指令的AIR-10K数据集,并证明了使用我们方法生成的指令能够显著提高模型执行复杂指令的能力,优于现有的指令生成方法。
Poster Session:Hall C,Session 15
Session Time:11月7日,14:00-15:30
《How to inject knowledge efficiently? Knowledge Infusion Scaling Law for Pre-training Large Language Models》
所在团队:未来生活实验室
大语言模型在通用任务上展现出强大的能力,但在专业领域常因缺乏特定知识而表现不佳,甚至产生幻觉。在预训练阶段注入领域知识是提升其专业能力的关键,但这面临一个权衡难题:注入过少则专业化不足,而注入过量则会导致对先前获得的知识的灾难性遗忘。本文针对过量知识注入导致的记忆坍塌(Memory Collapse)现象展开了系统性研究。通过对不同规模模型和训练语料量的大量实验,团队得到两个关键观察结果:1)临界坍塌点:每个模型都存在一个知识注入的阈值,一旦超过该阈值,其知识记忆能力会急剧下降。2)规模相关性:该临界点与模型规模存在稳定的缩放关系,即更大的模型在相对更低的注入频率下便会达到饱和。基于这些发现,团队提出了知识注入缩放定律(Knowledge Infusion Scaling Law)。通过分析规模较小的LLM模型,预测向更大模型注入领域知识时的最优数量。广泛的实验验证了该缩放定律的有效性和泛化能力。这项工作为高效地进行领域大模型预训练提供了可行的指导,有助于在提升模型专业领域能力的同时,显著节约计算成本。
Poster Session:Hall C,Session 15
Session Time:11月7日,14:00-15:30
《VC4VG: Optimizing Video Captions for Text-to-Video Generation》
所在团队:阿里妈妈技术团队
高质量的视频-文本对在视频模型训练中发挥着关键作用,它保障着连贯且指令对齐的视频生成。然而针对T2V(文本到视频)训练专门优化视频字幕的策略仍然探索不足。本文提出了一个用于视频生成的字幕优化框架VC4VG(Video Captioning for Video Generation),专为满足T2V模型的需求而设计。团队首先从T2V的角度分析字幕内容,将视频重构所需的基本元素分解为五个维度,并提出了一种有原则的字幕设计方法。为了支持评估,团队构建了VC4VG-Bench,这是一个包含1000个问答对的新自动评测基准,具有细粒度、多维度和根据必要性分级的指标,与T2V特定要求相一致。广泛的T2V微调实验表明,字幕质量的提高与视频生成性能之间存在强烈的相关性,验证了方法的有效性。
Poster Session:Virtual
更多前沿成果、技术演示与互动体验,尽在淘天集团EMNLP 2025 展台!我们在苏州等你,一起探索语言智能的无限可能~

💡 关于我们
📢中稿团队在招岗位
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢