
随着大语言模型和多模态技术的快速发展,人工智能已从理解文本、生成内容,迈向对真实世界动态的感知与推理。
然而,要真正理解复杂多变的物理世界,仅依靠语言还远远不够。
人类主要依靠视觉来观察世界、洞悉因果,并与环境进行交互。因此,统一视觉与语言,让模型学会对现实世界的动态与因果进行推理,是通往通用人工智能的必由之路。
今天,北京智源人工智能研究院(BAAI)发布“悟界·Emu3.5”,这是我们构建世界大模型(World Foundation Model)的开创性实践。
作为悟界·Emu 系列的最新成员,Emu3.5 延续了将图像、文本和视频等多模态数据统一建模的核心思想,并实现了从“下一Token 预测”(Next-Token Prediction)到“下一状态预测”(Next-State Prediction)的能力跃迁,通过海量视频等多模态数据,让模型自发学习世界演变的内在规律。
这项工作首次指明了“多模态 Scaling 范式”:随着模型参数、多模态数据和计算规模的增长,我们观察到模型对物理世界动态、时空关系与因果逻辑理解与预测能力的涌现与增强。
Emu3.5 在生成高质量图文内容的基础上,展现出了世界模型的核心能力:能够连贯地推演长时程的视觉叙事,在虚拟探索中保持时空一致性,甚至为开放世界中的具身智能体规划行动。
我们相信,这预示着一个新时代的开启:人工智能正从语言学习(Language Learning)迈向多模态世界学习(Multimodal World Learning)。
悟界·Emu3.5 建立了一个理解、预测乃至与物理世界交互的统一框架,揭示了多模态 Scaling 范式,开启多模态世界大模型新纪元
1
从第一性原理出发:
Emu3.5 如何学习成为“世界大模型”
在此前 Emu3 的探索中,我们已经验证了自回归预测范式的强大:通过持续优化 Next-Token Prediction(NTP)这个简单而单一的目标,一个 80 亿参数的 Transformer 模型就能够在多模态理解与生成任务上取得领先性能。这一结果也揭示了 NTP 作为“第一性原理”蕴藏的巨大潜力。
对 Emu3 视频处理过程的分析表明,当预测目标从离散的文本符号转向连续的视频帧时,为了最小化预测误差,模型被迫超越像素层面的模仿,开始内隐地学习和模拟物理世界动态演变的规律。换句话说,模型为了准确预测“下一个状态”,必须构建一个关于“世界如何运转”的内在模型。我们将这种蕴含了时空和因果演变的预测范式称之为 “Next-State Prediction”(NSP)。
基于这一洞察,Emu3.5 的目标是构建一个世界基座模型,能够原生预测交错的视觉与语言序列的“下一个状态”。这意味着模型在一个统一的框架内,同时预测视觉状态的演变和生成关于这些状态的语言描述。
为此,我们对模型架构、数据构成、训练与推理流程等进行了全面的优化与提升。
原生多模态自回归架构
悟界·Emu3.5 是一个拥有 340 亿参数的稠密自回归 Transformer 模型。继承 Emu3 的极简架构,通过将视频帧、图像、文本等所有模态统一离散化为 Token 序列,模型能够以单一 NSP 任务,实现统一的原生多模态学习。这赋予了模型前所未有的通用性与可扩展性,也是我们将其称之为“世界大模型”的一个重要原因。
以视频为核心的学习范式
在所有数据形态中,视频是模拟真实世界最高效的载体,也是唯一同时蕴含时间(Time)、空间(Space)、物理(Physics)、因果关系(Causality)和意图(Intent)这五大核心要素的数据形态。
我们构建了一个超过 10 万亿 token 的多模态数据集,其关键组成部分是由总时长约 790 年的视频及其对应的语音转录文本所构成的视频-文本交错数据(Video-Text Interleaved Data)。通过将视频帧与其对应的语音转录文本交错排列进行训练,我们为模型提供了学习视听同步、事件发展的训练数据,使其能够沉浸式地接触到时空、物理、因果等世界信息。
三阶段训练流程
为了将模型潜力充分激发并使其能力可用,我们设计了以下训练流程:
大规模预训练:在超过 10 万亿 token 的多模态数据上,训练一个 340 亿参数的稠密 Transformer 模型,执行 NSP 任务,让模型自发地学习视觉与语言的基本对齐,以及对世界基本规律的初步认知。
指令微调:我们构建了涵盖视觉叙事、视觉指导、世界探索等多种任务的高质量指令数据,对模型进行微调。这使得模型学会遵循人类指令,将预训练阶段学到的泛化能力应用到具体任务上。
大规模多模态强化学习:为了进一步提升生成质量和多模态推理能力,我们构建了一个多维度的奖励系统,并首次在多模态领域通过大规模强化学习对模型进行微调,使 Emu3.5 在美学、逻辑性、有益性和创造性等方面更加符合人类偏好。
高效的混合推理预测
针对自回归模型在图像生成中逐 token 解码速度慢的固有挑战,我们提出了“离散扩散自适应”(Discrete Diffusion Adaptation,DiDA)技术。DiDA 将传统的串行逐 token 生成过程,转变为一个多步并行的预测过程,在不牺牲性能的前提下,将每张图片的推理速度提升了近 20 倍,首次使自回归模型的生成效率媲美顶尖的闭源扩散模型。
2
实验数据:性能全面领先
在多个权威基准测试中,Emu3.5 的表现超越了众多业界领先的模型。
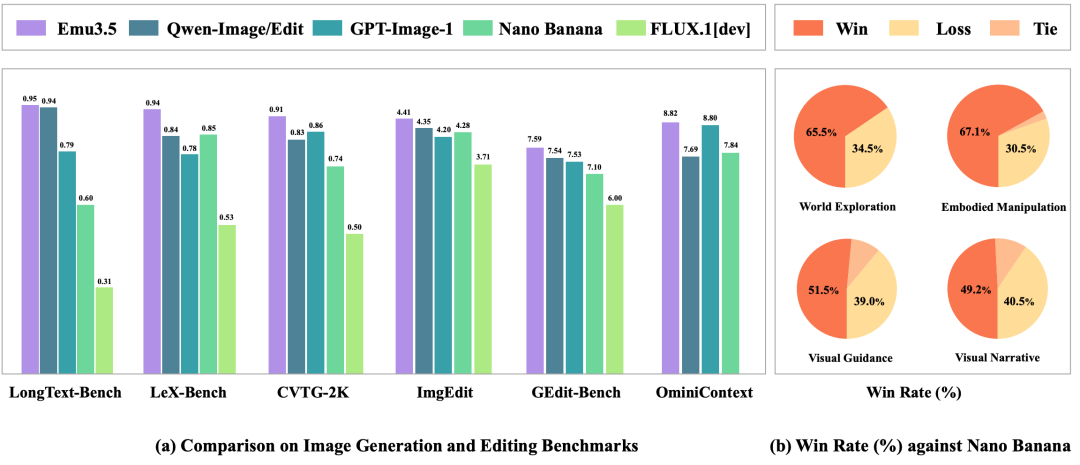
Emu3.5 在图像生成和编辑任务上取得了与Gemini 2.5 Flash Image(Nano Banana)相媲美的性能,并在系列图文交错生成任务中展现出更优异的结果。
下面是 Emu3.5 核心能力的一些展示:
- 文生图 | Text-to-Image

- 图像编辑 | Any-to-Image

- 视觉故事 | Visual Narrative

- 视觉指导 | Visual Guidance

- 世界探索 | World Exploration
- 具身操作 | Embodied Manipulation
3
探索多模态 Scaling 新范式
大语言模型的成功,本质上是 Scaling Law 的胜利。
那么,一个自然的疑问是:对于比语言更复杂、充满因果与物理规律的真实世界,是否也存在同样的定律?
从 Emu3 到 Emu3.5,模型参数从 8B 扩展至 34B,训练视频数据总时长从 15 年扩展至 790 年,我们观察到一系列核心指标,包括时序一致性、跨模态语义推理、具身交互规划等各项能力的显著提升。
通过 Emu3 我们验证了自回归架构实现多模态理解与生成大一统的可行性,Emu3.5 则开启了多模态 Scaling 的新时代。更重要的是,它为通往更通用的、能够理解并与物理世界交互的通用人工智能,提供了一条坚实的、可度量的实践路径。
4
从语言学习迈向
多模态世界学习的新纪元
在 Emu3.5 的训练过程中,我们深刻体会到范式统一的力量、高质量视频数据的不可替代性,以及原生多模态融合带来的巨大潜能。
Emu3.5 也验证了我们的预判:大模型正加速从数字世界加速迈向物理世界。
展望未来,统一自回归架构与多模态 Scaling 范式,将成为驱动 AI 向更通用、更强能力演进的关键引擎。我们相信,沿着这条路径能持续拓展多模态智能的能力边界,开启多模态世界大模型新纪元。
为加速这一进程,我们将开源 Emu3.5。
由衷希望 Emu3.5 能够成为全球研究者与开发者探索下一代多模态世界模型的坚实基座,并期待与更多合作伙伴一起,共同探索多模态智能、世界模型、具身智能与人机交互的新疆域。
欢迎访问悟界·Emu3.5 项目主页,开启多模态宇宙探索之旅
项目主页:https://zh.emu.world/
扫码申请尝试 Emu3.5 科研内测版👇🏻

阅 读 更 多


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢