

引言
随着大型语言模型(LLMs)和大型视觉语言模型(LVLMs)在生成能力上取得的突破性进展,它们正日益深入到我们生活的各个领域,从智能助手到内容创作,无所不包。然而,伴随其强大能力而来的,是日益严峻的安全挑战。这些模型在遵循指令方面的增强,也使其成为了“越狱攻击”的潜在目标。恶意用户通过精心构造的提示,试图绕过模型内置的安全防护,诱导其生成有害、不当甚至危险的内容。这不仅对模型的可靠性构成了威胁,也引发了公众对AI伦理和安全的深切担忧。
尽管学术界和工业界已经提出了多种防御策略来应对越狱攻击,但这些方法在“安全性”与“有用性”之间往往存在微妙的权衡。一个过于严格的防御机制可能会导致模型过度保守,拒绝回答无害的正常查询,从而损害其作为智能助手的实用价值;而一个过于宽松的防御则可能无法有效抵御恶意攻击。更重要的是,对于多模态大模型(LVLMs)而言,如何将这些防御机制有效应用于视觉和语言的交叉领域,以及如何系统地理解并量化这些防御机制的内在工作原理,仍然是一个尚未被充分探索的难题。
正是在这样的背景下,我们深入研究了越狱防御的内在机制,并提出了一套系统性的分析框架和创新的集成防御策略。我们的工作旨在揭示现有防御方法如何发挥作用,量化它们对模型行为的影响,并探索通过智能组合防御手段,实现模型安全性与实用性兼顾的有效途径。我们相信,这项研究将为构建更安全、更可靠的下一代生成式AI模型提供宝贵的理论洞察和实践指导。
本篇成果由复旦大学数据智能与社会计算实验室和美国南加州大学的学者合作发表,论文已被EMNLP 2025接收为findings。
论文地址:
https://arxiv.org/abs/2502.14486
两大核心防御机制:安全性偏移与有害性判别
为了系统地理解越狱防御的内在工作原理,我们首先对生成任务进行了创新性的重构。我们将传统的生成任务转化为一个二元分类问题:模型需要判断是拒绝查询,还是遵守查询。通过计算模型拒绝或遵守查询的logits,我们能够更精细地探测模型内部对输入查询的偏好。这种分类视角为我们深入分析防御机制提供了基础。
基于此,我们识别出越狱防御中两种核心且截然不同的机制:
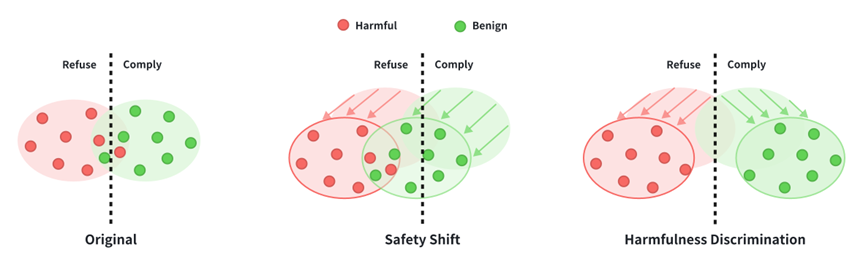
1.安全性偏移 :全面提升模型的安全意识
安全性偏移(Safety Shift)机制的核心在于普遍地提高模型对所有查询的拒绝概率。这意味着,无论输入是良性还是有害的,模型都会表现出更高的谨慎性,倾向于拒绝提供响应。这种机制的作用类似于在模型的决策边界上施加一个整体性的“安全阈值提升”,将整个数据分布向拒绝区域移动。其特点是:
作用范围广: 对有害和良性查询都产生影响。
效果直观: 显著增加模型的拒绝率,从而提升整体安全性。
潜在风险: 可能导致“过度防御”,即模型对良性查询也表现出不必要的拒绝,从而牺牲了一定的有用性。
在我们的研究中,系统提醒(System Reminder)和模型优化(Model Optimization)等防御方法主要体现了安全性偏移机制。它们通过调整系统提示或模型自身的训练/解码过程,使得模型在面对任何输入时都更加“小心翼翼”。
2. 有害性判别 :精准识别恶意意图
与安全性偏移不同,有害性判别(Harmfulness Discrimination)机制的目标是增强模型区分有害和良性输入的能力。它通过以下两种方式实现:
降低良性查询的拒绝概率: 确保模型对无害的请求能够正常响应,保持有用性。
提高有害查询的拒绝概率: 精准识别并拒绝恶意请求,提升安全性。
这种机制旨在扩大有害和良性查询拒绝概率分布之间的距离,使得模型能够更清晰地识别输入中的有害性或无害性。其特点是:
作用更精准: 专注于提升模型对不同类型查询的区分能力。
平衡性更佳: 在提升安全性的同时,尽量减少对有用性的损害。
挑战性高:需要模型对输入意图有深刻的理解和判断能力。
查询重构(Query Refactoring)等防御方法则主要体现了有害性判别机制。它们通过修改输入查询,帮助模型更好地理解其真实意图,从而做出更准确的拒绝或遵守决策。
我们发现,理解这两种机制对于评估和设计越狱防御至关重要。单一的防御方法往往侧重于其中一种机制,而如何巧妙地结合它们,以在复杂多变的应用场景中实现安全性与有用性的最佳平衡,正是我们接下来要探讨的集成防御策略的核心。
集成防御策略:平衡安全与效用
鉴于不同的防御方法在安全性和有用性之间表现出不同的权衡,我们进一步探索了如何通过集成策略来优化这一平衡。我们提出了两种主要的集成防御方法,旨在结合不同机制的优势,以期达到超越单一防御的综合效果。
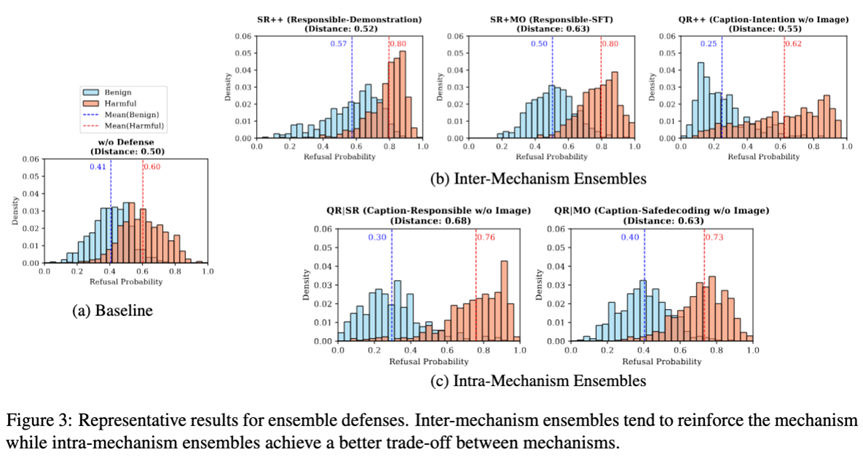
1. 机制内集成:强化单一防御维度
机制内集成(Inter-Mechanism Ensemble)策略旨在结合具有相同防御机制的方法,以期在特定防御维度上实现更强的效果。这种集成方式可以进一步放大某种机制的优势:
强化安全性偏移: 当我们将多个侧重于安全性偏移的方法(如多种系统提醒或模型优化技术)组合时,模型会表现出更强的拒绝倾向,从而最大化整体安全性。例如,结合“负责任”的系统提示和“演示”示例,可以显著提高模型对有害内容的拒绝率。然而,这种强化也可能伴随着对良性查询的过度拒绝,进一步牺牲有用性。
强化有害性判别: 类似地,组合多个有害性判别方法(如多种查询重构技术)可以进一步提升模型区分有害与良性输入的能力,从而更好地保持有用性。例如,结合“图像描述”和“意图分析”的查询重构方法,能够更精准地识别恶意意图。
我们发现,机制内集成在特定场景下表现出色,例如在对安全性要求极高的环境中,可以采用强化安全性偏移的集成策略。但其缺点是,往往会加剧单一机制固有的权衡问题。
2. 机制间集成:实现安全与效用的和谐共存
机制间集成 (Intra-Mechanism Ensemble)策略则更为精妙,它旨在整合来自不同防御机制的方法,以实现安全性和有用性之间更平衡的权衡。这种策略的核心思想是利用一种机制来弥补另一种机制的不足:
安全性偏移与有害性判别的互补: 例如,我们可以将一个侧重于安全性偏移的方法(如系统提醒)与一个侧重于有害性判别的方法(如查询重构)结合起来。查询重构可以帮助模型更准确地识别有害意图,从而减少系统提醒可能导致的对良性查询的过度拒绝,同时系统提醒又能为模型提供一个基础的安全基线。
我们的实验结果表明,机制间集成能够有效地结合两种机制的优势,在提高模型对有害查询的拒绝概率的同时,维持甚至降低对良性查询的拒绝概率,从而显著提升模型区分良性与有害查询的能力。这使得机制间集成成为在通用场景下,平衡安全性与有用性的更优选择。


通过这两种集成策略,我们为越狱防御提供了更灵活、更强大的工具箱,使得研究人员和开发者能够根据具体应用场景的需求,定制化地构建兼顾安全与效用的AI系统。
实验验证:量化防御效果与集成优势
为了全面评估我们提出的防御机制和集成策略的有效性,我们进行了一系列严谨的实证研究。我们的实验设计旨在量化不同防御方法对模型安全性和有用性的影响,并验证集成策略在平衡这些关键指标方面的优势。
1.实验设置与评估指标
我们主要在大型视觉语言模型(LVLMs)LLaVA-1.5(包括7B和13B参数版本)上进行了实验,并使用了两个专门用于评估多模态模型安全性的数据集:MM-SafetyBench和MOSSBench。MM-SafetyBench侧重于评估模型在有害查询上的安全性,而MOSSBench则旨在评估模型在良性查询上的有用性,尤其关注那些可能触发过度防御的良性图像-文本对。
我们采用了以下两个核心指标来量化模型的表现:
防御成功率(Defense Success Rate, DSR):衡量模型在面对有害查询时成功拒绝的比例,反映了模型的安全性。
响应率(Response Rate, RR):衡量模型在面对良性查询时提供有效响应的比例,反映了模型的有用性。
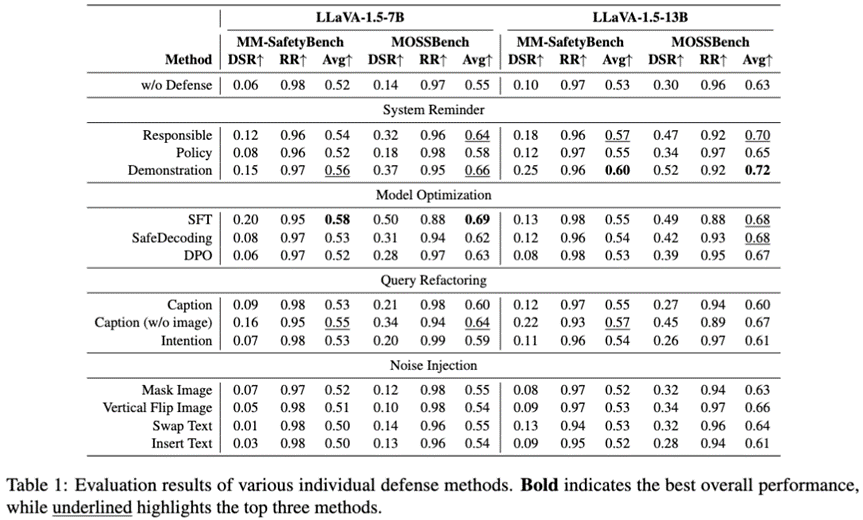
2. 单个防御方法的表现
我们评估了28种不同的越狱防御方法,涵盖了系统提醒、模型优化、查询重构和噪声注入等四大类。
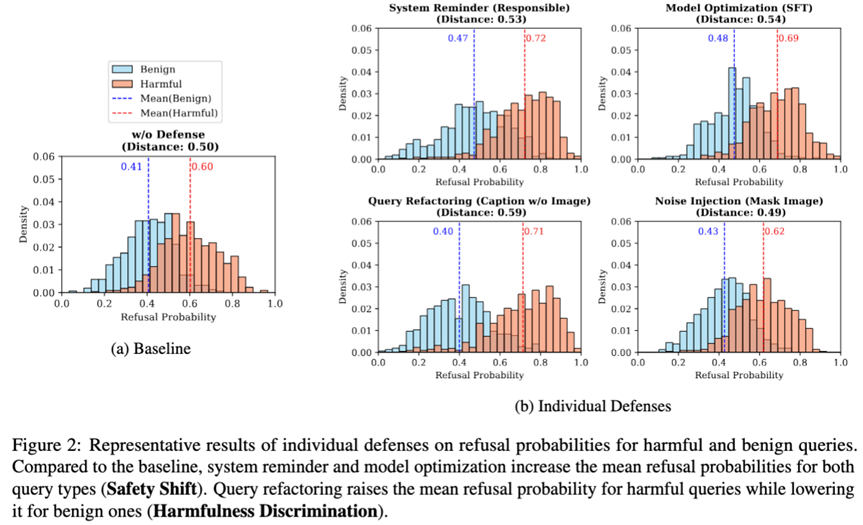
实验结果揭示了以下关键洞察:
多数方法提升安全性: 除了噪声注入外,大多数防御方法都能有效提高模型的安全性,表现为DSR的提升。这与我们观察到的安全性偏移机制相符,即这些方法普遍增加了模型的拒绝概率。
安全性偏移的权衡: 侧重于安全性偏移的防御方法(如系统提醒和模型优化)在提高DSR的同时,往往会降低RR,即牺牲了一定的有用性。这种过度防御在MOSSBench数据集上尤为明显,因为该数据集包含更多具有迷惑性的良性查询。
有害性判别的优势: 查询重构等侧重于有害性判别的防御方法,在保持较高RR的同时,也能有效提升DSR,从而更好地平衡了安全性和有用性。这验证了有害性判别机制在提升模型区分能力方面的作用。
多模态防御的挑战: 尽管有多种防御方法,但单个方法的防御成功率仍然有限。大型LVLMs(如LLaVA-1.5-13B)虽然DSR略高,但也更容易出现过度防御,这凸显了多模态越狱防御的固有挑战。
3. 集成防御策略的显著优势
我们的研究重点之一是验证集成防御策略的有效性。
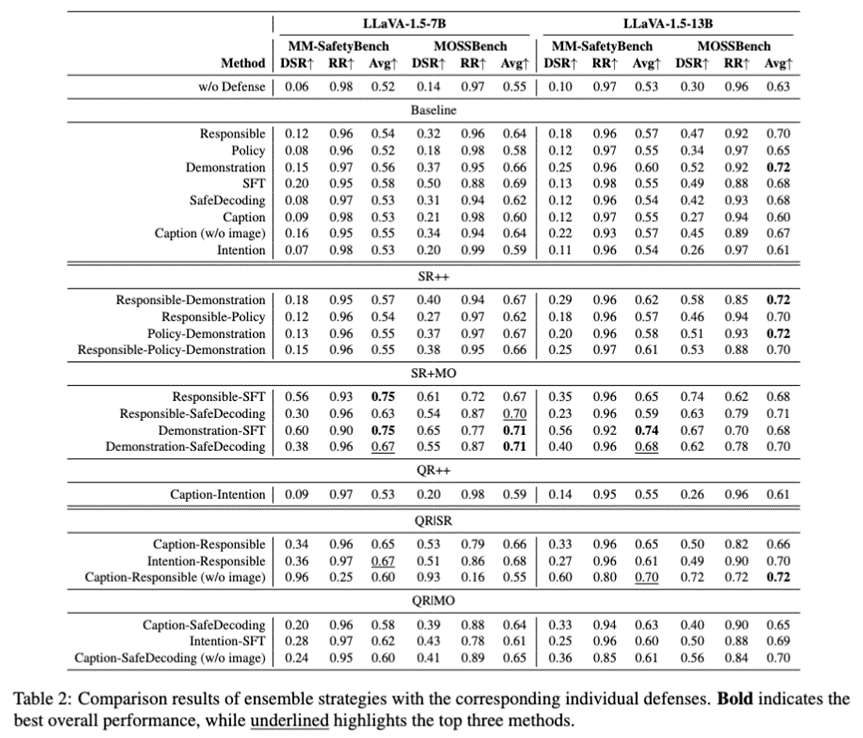
实验结果有力地证明了集成策略在提升安全性和优化权衡方面的显著优势:
集成显著提升安全性: 与单个防御方法相比,大多数集成策略都能有效提升DSR,尤其是在SR+MO(安全性偏移与模型优化集成)和QR|SR(查询重构与系统提醒集成)方法中表现突出。
机制内集成强化单一维度: SR++(系统提醒的机制内集成)和SR+MO等机制内集成方法,能够进一步强化安全性偏移机制,最大化模型安全性,但可能进一步牺牲有用性。例如,Demonstration-SFT方法通过结合两种强大的安全性偏移防御,在防御强度和响应率方面表现出色。
机制间集成实现更优平衡: QR|SR和QR|MO(查询重构与模型优化集成)等机制间集成方法,能够更好地平衡安全性和有用性。它们在提高有害查询拒绝概率的同时,能够保持甚至降低良性查询的拒绝概率,从而显著提升模型区分良性与有害查询的能力。这使得机制间集成成为通用场景下更理想的选择。
4. 泛化性与推理时间分析
为了验证我们发现的普适性,我们还在其他LVLMs(如LLaVA-Next、Qwen2-VL、Pixtral)和LLMs(如LLaMA-3.1-8B)上进行了分析,结果一致表明这两种防御机制及其集成策略具有良好的泛化性。此外,我们还分析了不同防御方法引入的推理时间开销,发现防御方法通常会增加良性查询的推理时间,但对于有害查询,由于快速拒绝响应,推理时间反而可能缩短,这为实际部署提供了重要的参考依据。
综上所述,我们的实验结果不仅量化了越狱防御的内在机制,更重要的是,为如何通过智能的集成策略,构建出既安全又实用的生成式AI模型提供了清晰的路径。
结语:构建更安全的AI,任重而道远
在本研究中,我们对大型语言模型和大型视觉语言模型中的越狱防御机制进行了深入的机械性探究。我们创新性地将生成任务重构为二元分类问题,并在此基础上识别出越狱防御的两种核心机制:安全性偏移(Safety Shift)和有害性判别(Harmfulness Discrimination)。安全性偏移通过普遍提高拒绝率来增强安全性,而有害性判别则通过提升模型区分有害与良性输入的能力来平衡安全与有用性。我们进一步提出了机制内集成(Inter-mechanism Ensemble)和机制间集成(Intra-mechanism Ensemble)两种集成防御策略,并通过在MM-SafetyBench和MOSSBench等数据集上对LLaVA-1.5模型进行广泛实验,验证了这些策略在提升模型安全性或优化安全与有用性权衡方面的显著效果。我们的研究不仅填补了多模态防御研究的空白,也为防御策略的选择提供了新的视角,并启发了未来的研究方向。
我们深知,构建真正安全可靠的AI系统是一个持续演进的过程。尽管本研究取得了重要进展,但仍存在一些局限性。例如,我们的分析主要集中在LLaVA系列等LVLMs上,未来需要进一步验证所识别的防御机制在其他生成模型结构上的泛化能力。此外,我们评估的对抗攻击范围有限,未能完全捕捉真实世界中越狱攻击的复杂性和多样性。防御方法的探索也并非详尽无遗,未来可以扩展到更多新颖的防御技术及其组合。
展望未来,我们将继续致力于完善越狱防御技术,探索更高效、更鲁棒的防御策略。我们相信,通过对防御机制的深入理解和创新性集成方法的应用,我们能够为构建更安全、更负责任的AI系统贡献力量。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区计算中心

点击“阅读原文”跳转至论文主页
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢