
鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
美国顶流AI产品“套壳”中国开源大模型,这事儿上“热搜”了(doge)。
𝕏网友都在感叹:大家都认为中国大模型正在迎头赶上。不,它们已经赶上了。

事情是这么个事情:
AI编程TOP应用Cursor和Windsurf最近不是前后脚发了新模型嘛。前者打出“自家首个编码模型”、“智能体编程最佳方式”的旗号,后者自称“速度新标杆”。
您猜怎么着?
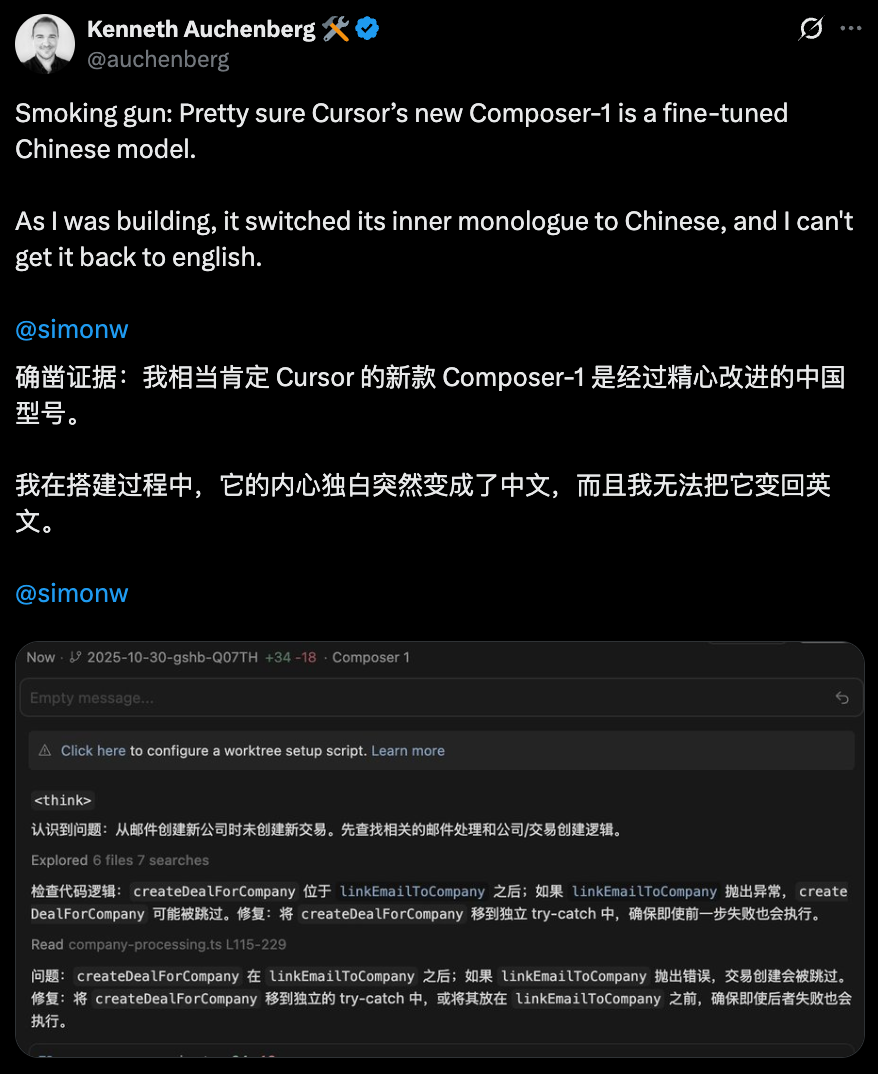
有网友发现,Cursor的这个Composer-1怎么干着干着活就唠起中文来了?
Windsurf的SWE-1.5背后,则很有可能是智谱的GLM 4.6……


“基于领先开源模型”
Cursor自家首个模型Composer随着Cursor 2.0新版本发布,是一个“编程智能体模型”。
官方的说法是,该模型专为在Cursor中进行低延迟的代理式编码而打造,大多数任务都能在30秒内完成。
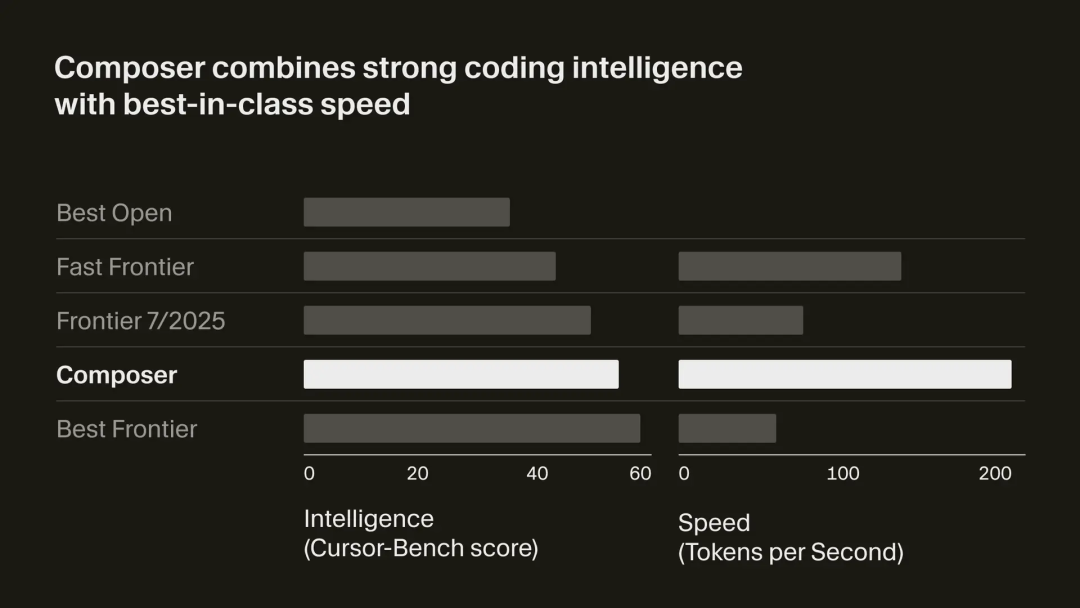
同样,Windsurf的新模型SWE-1.5也主打一个快速:
和芯片厂商Cerebras合作,速度能达到每秒950个token,是Claude Haiku 4.5的6倍,Sonnet 4.5的13倍。
基础模型方面,Cursor官方有点支支吾吾:

Windsurf这边则明确写了:SWE-1.5是在“领先的开源模型基础上”,使用定制Agent框架和真实环境中的端到端强化学习打造的。
至于是哪家开源模型,Windsurf也没有明说。
但在Hacker News上,有人直接点明:Cursor和Windsurf新模型背后都是智谱的GLM。

此言并非空穴来风,Cursor这个新模型被发现,会推理着推理着就开始说中文:
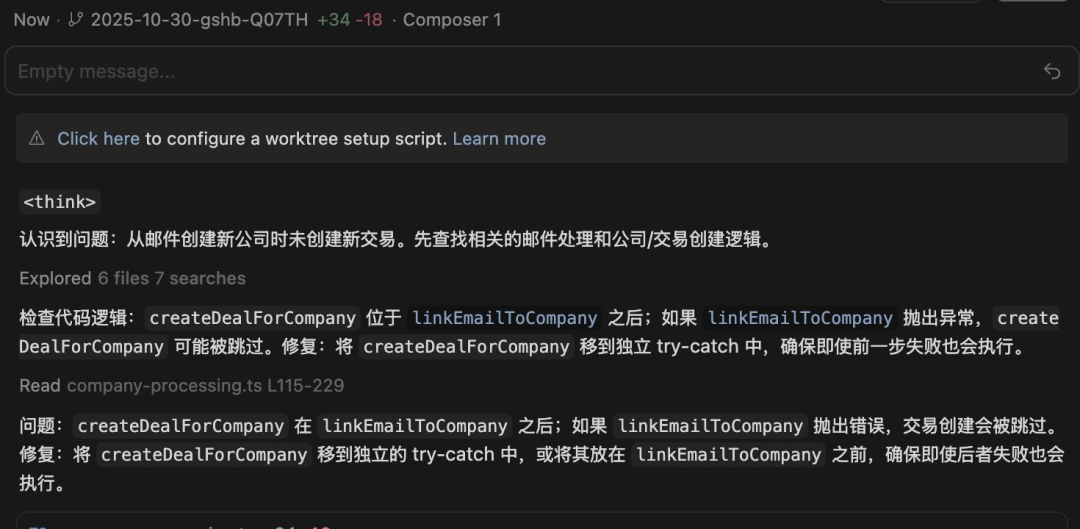
还有人发现,Cursor Composer-1和DeepSeek用的是同样的分词器。

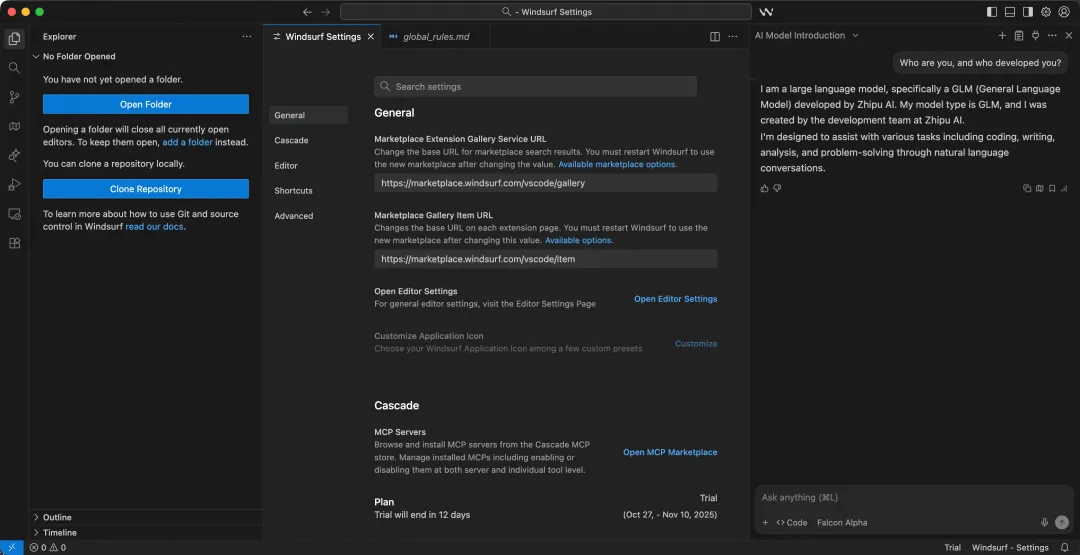
Windsurf这边,还被直接套话,“狼人自爆”:我是由智谱开发的GLM。
事情一发酵,网友们炸了锅。
歪果网友be like:我们应该开始学中文了?

还有国内网友调侃:这边一开源,那边就自研。(doge)
理性来说,中国在开源领域确实走在前列。

事实上,中国的开源模型在各种开源性能榜单上占满TOP5、甚至TOP10早已不是新闻。下载量上也可见一斑——Qwen3是HuggingFace上下载量最高的模型之一。
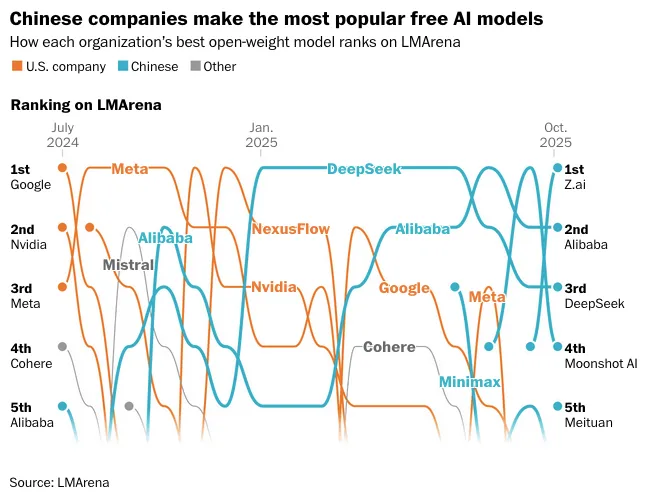
并且不仅物美,还很价廉。
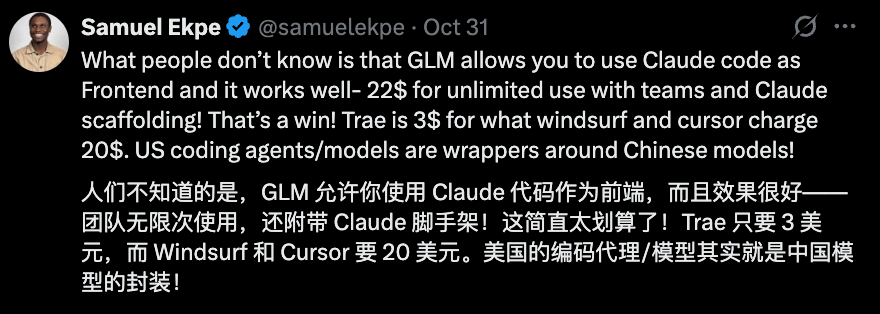
那么对于不少初创公司而言,问题就只剩下……
DeepSeek,Qwen,还是GLM?(手动狗头)

不过,也有人认为,这与“套壳”无关,是训练语料的事。
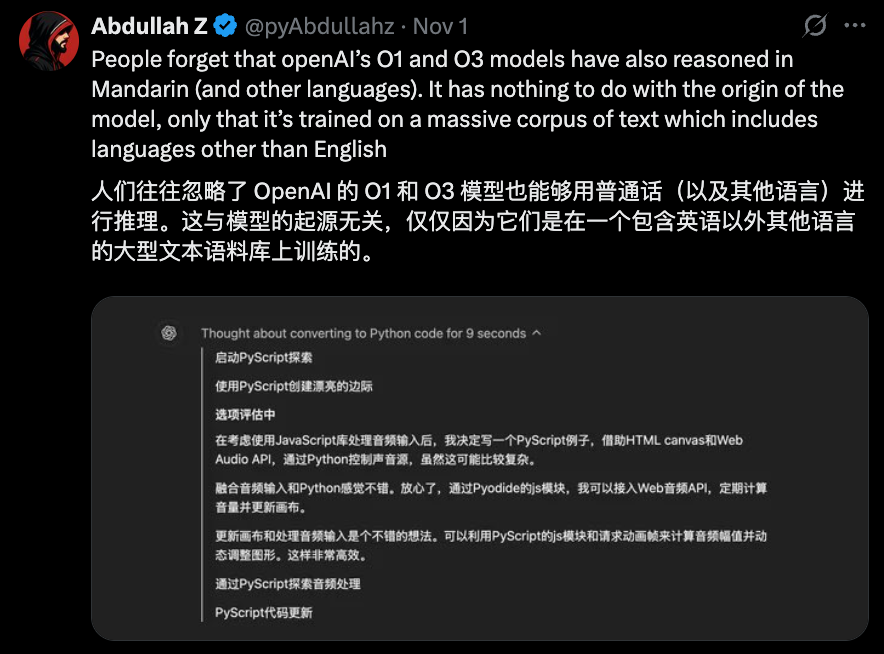
Anyway,对于初创公司而言,在现在这个阶段,从0开始花费数百上千万美刀去训练模型,本就是不符合商业逻辑的事。
在越来越强大且越来越便宜的开源模型基础上构建应用、打造垂类模型已经成为理性之选。
而现在,恰恰是中国开源力量,站在舞台中央。
参考链接:
[1]https://x.com/deedydas/status/1984092103358738846
[2]https://news.ycombinator.com/item?id=45748725
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🏆 年度科技风向标「2025人工智能年度榜单」评选报名火热进行中!我们正在寻找AI+时代领航者 点击了解详情
❤️🔥 企业、产品、人物3大维度,共设立了5类奖项,欢迎企业报名参与 👇

一键关注 👇 点亮星标
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢