

新智元报道
新智元报道
【新智元导读】清华大学李升波教授团队在NeurIPS 2025提出LLM-Filter通用滤波器,创新性地将状态估计融入大语言模型的推理框架,借助其先验知识与泛化能力,解决传统方法在新系统上泛化性差的问题。实验表明,该模型在未见过的系统中能实现零样本状态估计,表现优于现有学习型滤波器,有望成为科学与工程领域的基础模型。
状态估计(State Estimation)是现代科学与工程中的核心问题之一。
其目标是在存在噪声和不确定性的观测数据下,准确推断出动态系统(如机器人、飞行器或气象系统)的真实内部状态(例如位置、速度、温度等)。
长期以来,状态估计方法主要分为两大类:
经典贝叶斯滤波器:状态估计的最全面的框架是贝叶斯滤波,它通过迭代预测步和更新步来在线估计状态。流行的在线贝叶斯滤波器可以分为高斯滤波器和粒子滤波器。在高维非高斯系统中,高斯滤波器往往会产生近似误差,而粒子滤波器受其大量计算需求的限制了应用场景。
传统学习型滤波器:为了克服这些问题,研究者们开发了基于深度学习的学习型滤波器 。这些方法通过在大量数据上进行训练,直接学习从观测到状态的映射关系 。然而,学习型滤波器的效果依赖于特定任务的数据集,导致其泛化能力很差 。
一旦系统发生改变或需要将其应用于一个全新的系统,模型性能就会急剧下降,必须从头开始重新训练。
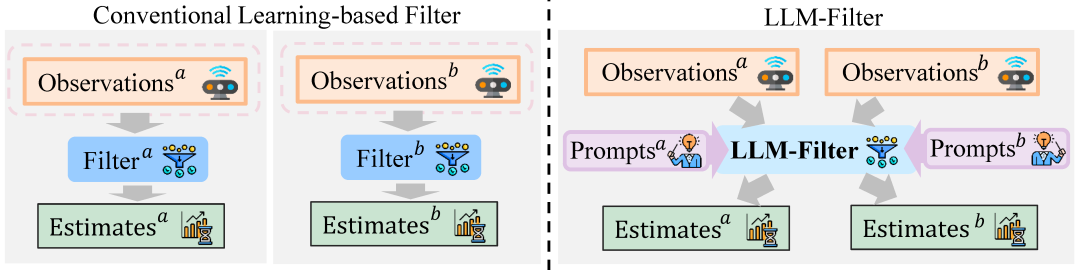
作为滤波问题的对偶问题,控制问题推动了通用控制模型(VLA模型)的开发,这些模型利用大语言模型(LLM)或视觉语言模型(VLM)的训练知识,既能提升特定控制任务的性能,又能具备跨多样化控制任务的泛化能力。
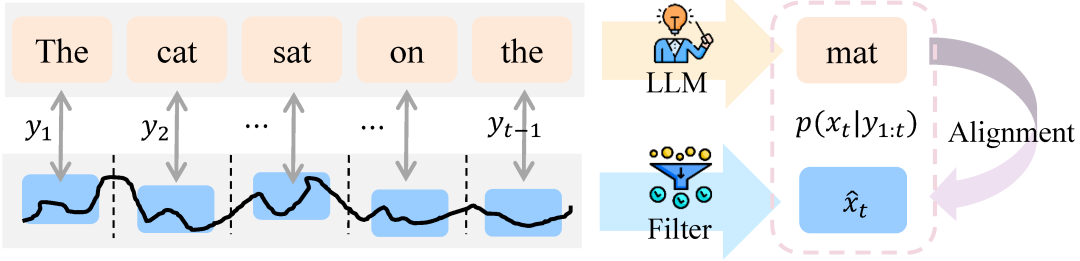
受通用控制模型成功启发,清华大学李升波教授课题组在NeurIPS 2025上提出一种通用滤波器——LLM-Filter,旨在通过与大语言模型实现恰当的模态对齐,利用LLM的先验知识和泛化能力来解决估计的泛化问题。

论文链接:https://arxiv.org/abs/2509.20051
该工作首次提出了通用大模型滤波方法(LLM-Filter),将状态空间对齐到大模型的词表语义空间,使得状态估计能够自然融入大模型的推理过程中。通过精心设计的提示语,LLM-Filter能够在面对未见过的系统上时实现零样本滤波,突破了传统滤波方法在泛化性上的局限。

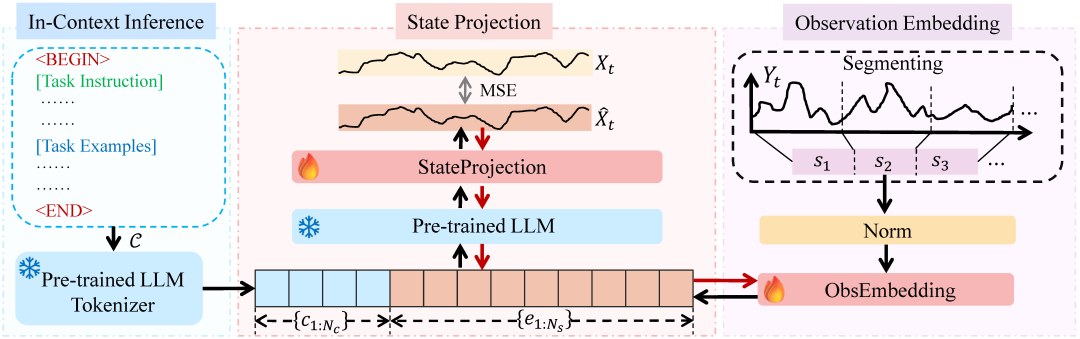
LLM滤波器的框架:
(1)观察嵌入:分段观测并嵌入到词表空间中。
(2)上下文推理:帮助 LLM-Filter 识别应用不同系统。
(3)状态映射:LLM的预测词表投影到状态空间中以获得最终估计。

滑动窗口: 状态估计目标是基于所有可用观测值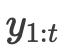 来估计状态
来估计状态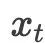 。然而,直接输入不断增长的观测序列在实际中并不可行。受到「滑动估计器」和「大语言模型的上下文窗口」的启发,研究人员设计了一个固定长度为T的滑动窗口用于估计。 输入观测定义为:
。然而,直接输入不断增长的观测序列在实际中并不可行。受到「滑动估计器」和「大语言模型的上下文窗口」的启发,研究人员设计了一个固定长度为T的滑动窗口用于估计。 输入观测定义为:
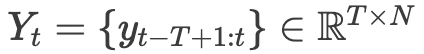
为了将连续观测与离散的LLM token对齐,研究人员对输入观测进行分段并嵌入到LLM中。常见的分段方法是采用单序列展开,即直接将所有维度的数据展平。但这种方式会破坏变量间的固有关系,例如位置与速度之间的重要关联,而这种关系对位置估计至关重要。为保留这些相关性,研究人员采用基于分段长度L的多维分段方式:
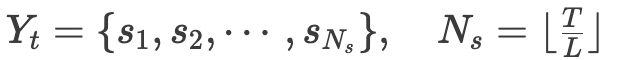
其中每个分段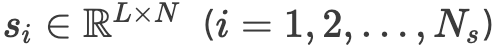 ,
, 表示向下取整。如果T不能被L整除,则在末尾进行padding,以保证分段长度一致。为了充分利用LLM的预训练知识及其token转换特性,冻结其参数,并去掉原本针对语言token的嵌入和投影层。取而代之的是引入观测嵌入层:
表示向下取整。如果T不能被L整除,则在末尾进行padding,以保证分段长度一致。为了充分利用LLM的预训练知识及其token转换特性,冻结其参数,并去掉原本针对语言token的嵌入和投影层。取而代之的是引入观测嵌入层:


传统的学习型滤波器仅依赖观测数据来估计真实状态,因此难以识别潜在系统动力学,泛化能力较差。为解决这一问题,研究人员利用LLM的上下文学习能力,提出一种新的提示策略SaP,帮助LLM-Filter灵活适应不同系统。
SaP由两部分组成:
任务指令(Task Instruction):提供关键的上下文知识,不同领域可有所差异;
任务示例(Task Examples):给出具体案例,帮助模型更好地理解任务。
在推理阶段,SaP文本CC会输入到预训练LLM的分词器中:
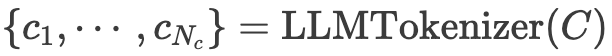
其中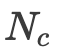 为分词后的上下文token数量。
为分词后的上下文token数量。
输入SaP提示与前一时刻观测的嵌入token,用于生成下一时刻的状态估计特征。为实现模态对齐,研究人员去掉LLM原本的嵌入层和投影层,仅使用核心层。具体来说,将SaP上下文token和观测嵌入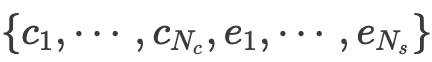 直接输入核心层,得到输出嵌入:
直接输入核心层,得到输出嵌入:
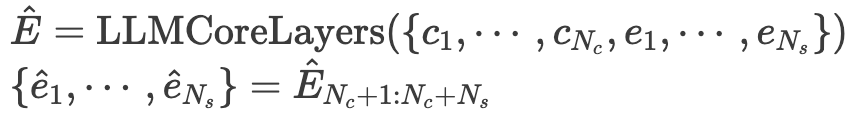
随后,研究人员使用投影层
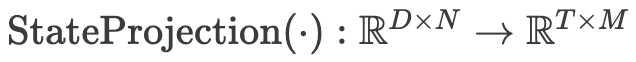
将输出嵌入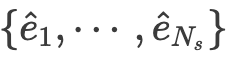 投影到系统状态空间,得到最终估计:
投影到系统状态空间,得到最终估计:

最后,最小化真实状态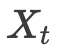 与估计值
与估计值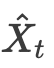 的误差,以优化LLM-Filter的参数θ:
的误差,以优化LLM-Filter的参数θ:
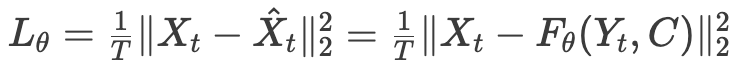
值得注意的是,为保留预训练知识并节省资源,研究人员选择冻结LLM参数,只更新ObsEmbedding(·)和StateProjection的参数。


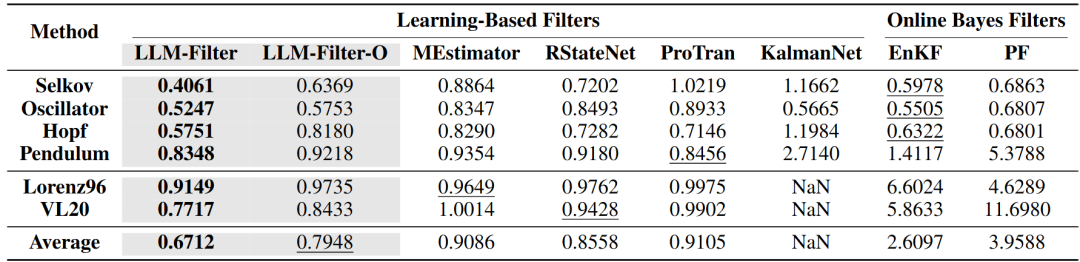
研究人员在五个经典系统上评估LLM-Filter的基本姿态估计能力,包含四个非线性系统(Selkov,Oscillator,Hopf, Pendulum)和两个高维混沌系统(Lorenz96和VL20)。并与现有在线滤波和学习型滤波方法进行对比估计误差(RMSE)。
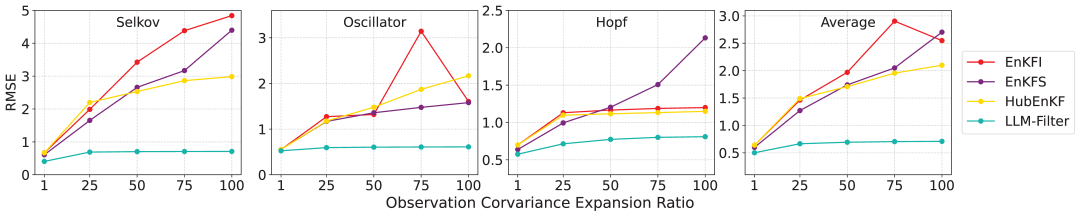
模型失配
研究人员在Selkov、Oscillator和Hopf系统上测试了LLM-Filter的模型失配情景,量化指标为观测协方差扩展比(OCER)。
跨系统泛化
在此实验中,研究人员评估了完全不同系统的泛化性能。 具体而言,对于LLM-Filter以及学习型滤波器KalmanNet、MEstimator、RStateNet和ProTran,研究人员在一个系统上训练,并在另一个系统上测试性能。
空心柱表示「跨系统(cross-system)」 场景,而实心柱表示「训练和测试在同一系统」的情况。
例如,「Tracking → Pendulum」表示模型在Tracking系统上训练,并在Pendulum系统上进行评估

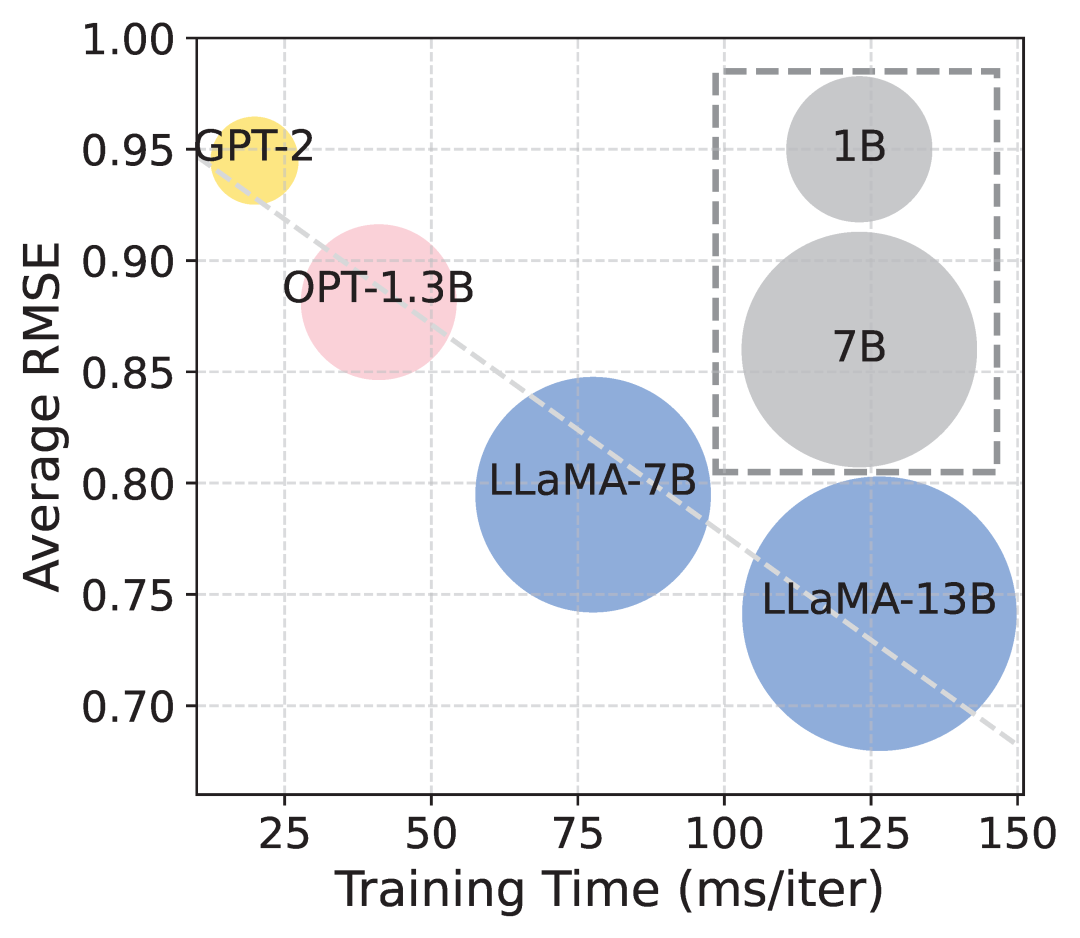
模型性质探索
在研究LLM-Filter在状态估计任务中的scaling行为时,通过使用不同参数规模的LLM作为骨干网络进行评估。
结果表明:随着模型参数增加,RMSE下降,估计精度提高,但训练时间也会增加。
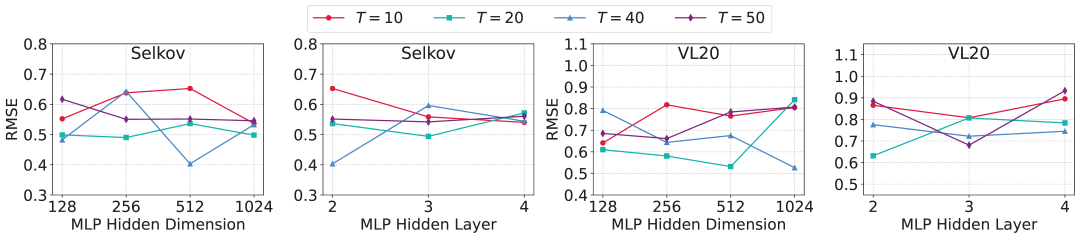
超参数敏感性
研究人员验证了LLM-Filter对超参数的鲁棒性,包括窗口长度T、隐藏层维度,以及ObsEmbedding和StateProjection中MLP层数。

受通用控制模型成功的启发,研究人员提出了一种通用大型滤波模型LLM-Filter,用于解决包括泛化任务在内的状态估计问题。借助提示信息和预训练知识,LLM-Filter在多种系统上表现优于专门训练的学习型滤波方法,并展现出出色的泛化能力。这些结果表明,LLM-Filter有潜力成为状态估计领域的基础模型。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢