


关键词:量子计算

导 读
本文是对发表于人工智能领域顶级会议 NeurIPS 2025 的论文 QCircuitBench: A Large-Scale Dataset for Benchmarking Quantum Algorithm Design 的解读。该工作由北京大学李彤阳课题组与北京大学人工智能研究院梁一韬老师联合完成,论文第一作者为北京大学计算机学院博士生杨睿,课题组王紫若同学亦做出重要贡献。
该研究首次提出了一个专门面向大语言模型(LLM)驱动量子算法设计的系统性基准与大规模数据集——QCircuitBench。该基准从代码生成视角出发,将量子算法表示为“量子电路 + 经典后处理函数”的组合形式,覆盖 3 个任务套件、25 类算法、共计 12 万余条样本。框架统一了量子算法生成、经典后处理函数设计、自动化语法与语义验证的流程,为 LLM 在量子计算领域的能力评估提供了可扩展基础。通过对 GPT-4o、Llama-3-8B、Qwen-2.5-7B 与 DeepSeek-R1 等模型的系统评测,研究发现现有 LLM 在量子算法生成中存在“即兴错误”、“计数错误”与“数据污染”等共性问题。同时,初步的微调实验验证了结构化学习的可行性,体现了 QCircuitBench 作为训练数据集的潜力,为未来实现“AI 辅助量子算法设计”提供了重要基础。

↑扫码跳转论文
论文地址:
https://arxiv.org/abs/2410.07961
github地址:
https://github.com/EstelYang/QCircuitBench
01
问题与背景
近年来,AI 在科学领域的应用逐渐兴起,尤其是大语言模型(LLM)辅助的算法设计成为热门方向。量子计算作为重要新兴科学领域,近年来得到重要关注。量子算法能够在若干计算任务上实现超多项式加速,但其设计过程复杂且不直观,长期依赖专家经验。与此同时,LLM 具备强大的先验知识与自然语言交互能力,却缺乏针对“量子算法设计”任务的标准评测平台。而现有量子计算基准主要针对于 NISQ 系统性能或编译工具[2,6,7],并不适用于模型训练或推理能力评估。
因此,我们提出 QCircuitBench[1],这是首个专为 LLM 驱动的量子算法设计构建的大规模基准测试数据集,填补了该领域的空白。
我们指出,构建 LLM 驱动量子算法设计评测基准需要解决三大核心挑战:
任务表述的模糊性:自然语言描述冗长、含糊;纯数学表达虽然精确,却不利于自动验证。
Oracle 困境:理论上其应被视为黑盒,但实验上必须以显式量子门实现。
经典后处理过程缺失:很多量子算法的输出,需要通过经典函数解释测量结果,否则无法完整验证算法功能。

02
数据集与整体框架
为解决上述问题,QCircuitBench 采用了代码生成视角重新表述量子算法,核心包含 7 大组件:
问题描述(含自然语言与 LaTeX)
生成函数(Qiskit[5]/Cirq[3]生成器)
算法线路(OpenQASM 3.0[4]门级电路/Python 函数模块式门级电路)
后处理函数(经典后处理与仿真)
Oracle/特殊 Gate 定义(黑盒 oracle 与复合门定义)
评测函数(语法+语义验证)
数据集构建函数(一键构建与清洗)
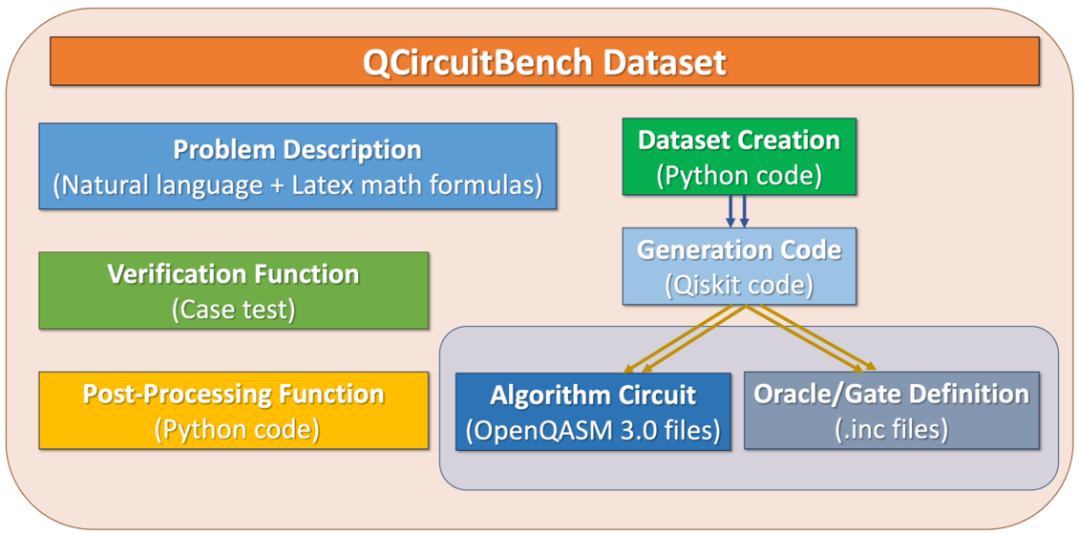

其中核心设计包括:
独立的 oracle.inc 库:在不破坏黑盒假设的前提下,提供可编译的门级定义;
必备经典后处理函数:统一输出测量结果解析流程;
显式 shot 数声明:用于衡量查询复杂度;
三层自动验证体系:涵盖 OpenQASM 语法、Python 语法与任务语义级校验,并实现全流程自动化评测。
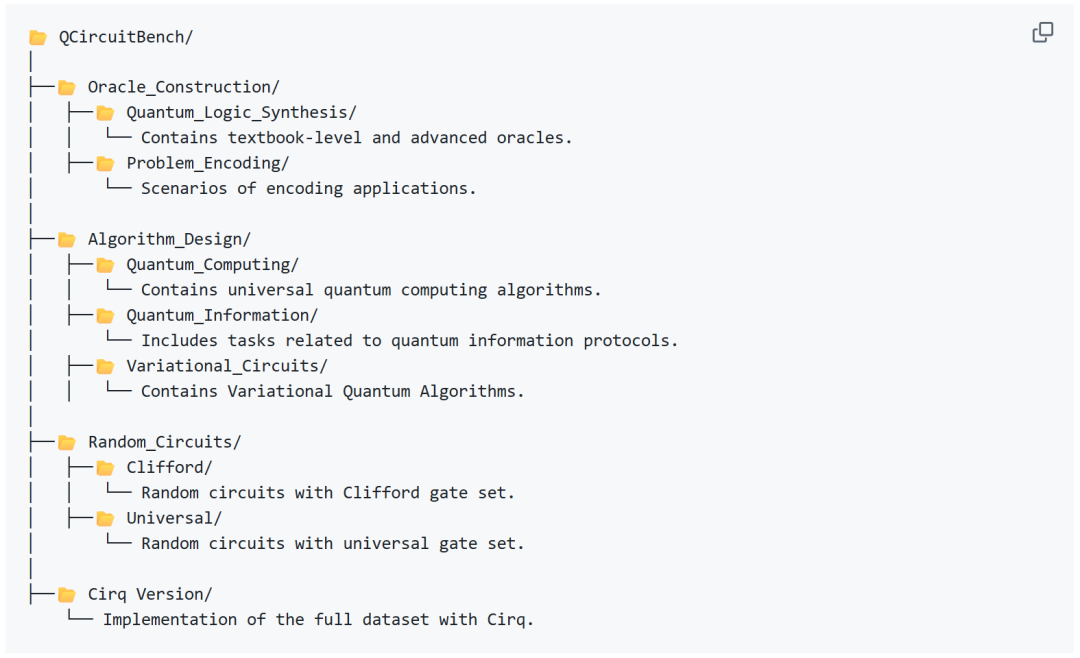
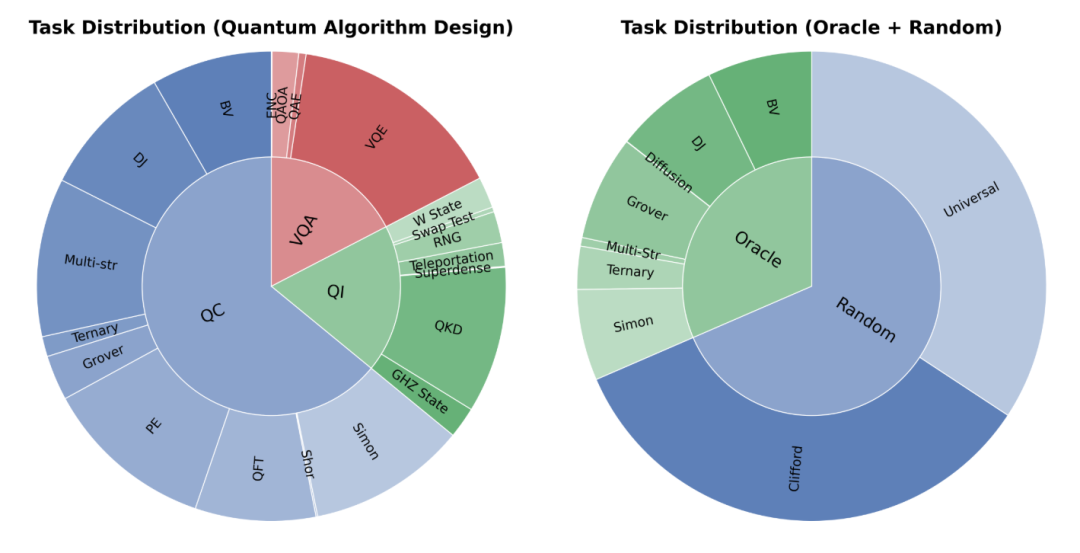
同时,QCircuitBench 囊括三大量子计算核心任务套件,分别包括:
Task I:Oracle 构建
该任务覆盖了 Bernstein-Vazirani、Deutsch-Jozsa、Simon、Grover(含扩散算子)等经典 Oracle 构造,并延展到实际问题中的 Oracle 构建上(如数独、三角形查找)。
Task II:量子算法设计
该任务包含了量子计算、量子信息与变分线路中的经典算法,如 Simon、Quantum Fourier Transformation、Quantum Teleportation、QAOA 等,也囊括了前沿算法,如 Multi-String Simon、Ternary Simon 等。
Task III:随机线路生成
该任务包含了带有目标态的,基于 Clifford 与 {H,S,T,CNOT} 通用门集的随机电路。
03
基准评测设置
我们在统一评测框架下比较了 GPT-4o、Llama-3-8B、Qwen-2.5-7B、DeepSeek-R1 等闭源与开源的主流模型。
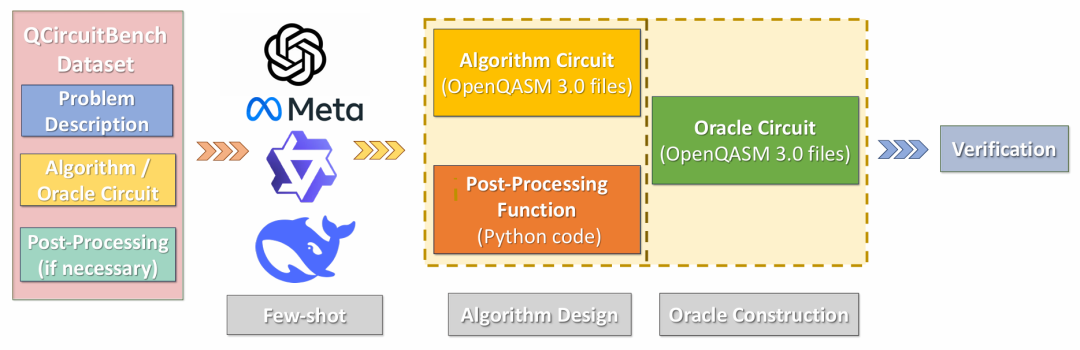
评测指标包括:
BLEU 与 Perplexity(语言层面);
语法验证(QASM 与 Python);
语义验证(任务级功能正确性);
效率指标(门数、shot 数、运行开销)。
04
实验结果分析
BLEU ≠ 正确性:
在某些任务上,模型虽能生成表面相似的电路代码,但语义验证失败率仍高。
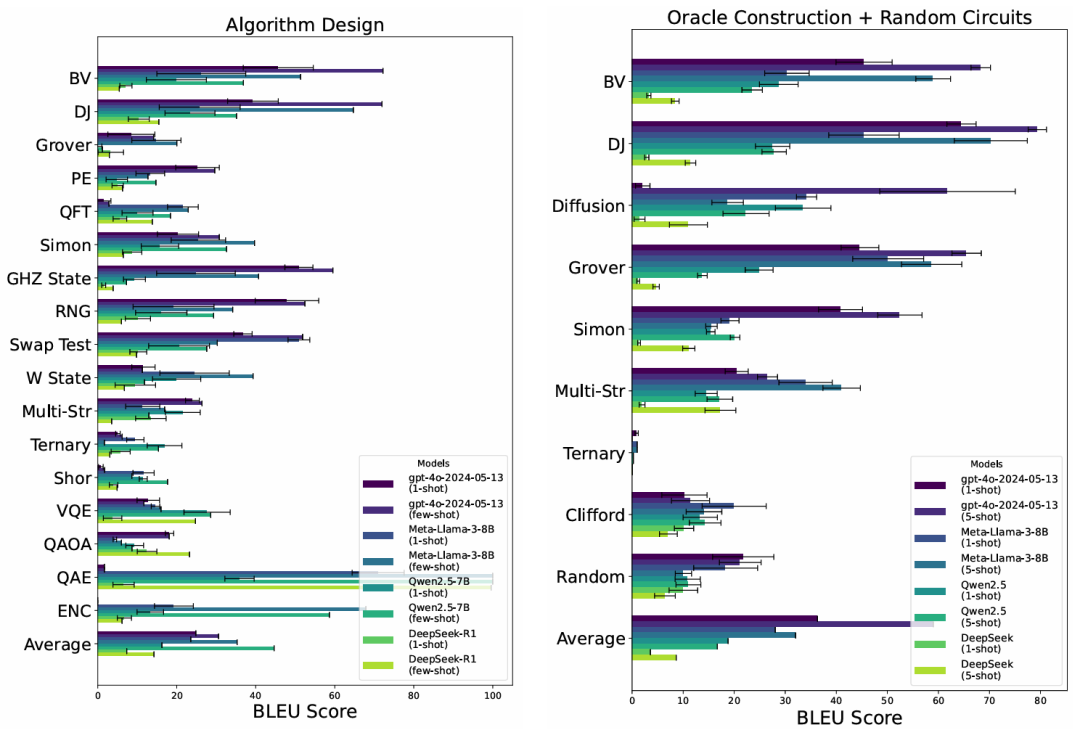
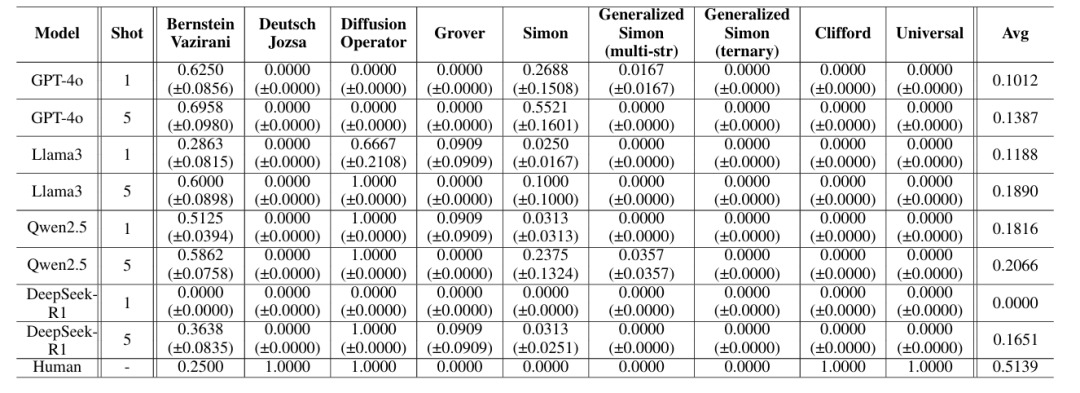
Few-shot > One-shot:
在模板化任务中 few-shot 明显优于 one-shot,但在复杂算法(如 QFT、Shor)上仍难以泛化。
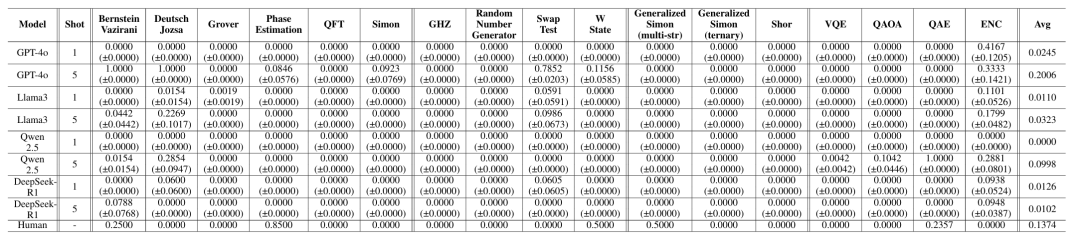
变分量子算法最具挑战:
VQE、QAOA 涉及量子-经典混合流程,对模型结构理解提出更高要求。
同时,在评测过程中,我们发现了 LLM 存在三种典型错误:
1)即兴错误
LLM 会使用非常规的命名空间(如 s,x,y 变量名)或未受支持的 OpenQASM 3.0 语法(如循环语句)等,导致无法通过语法测试。

此处,GPT-4o 使用了暂未受 qiskit.qasm3 支持的 OpenQASM 3.0 的循环语句语法,导致编译错误。
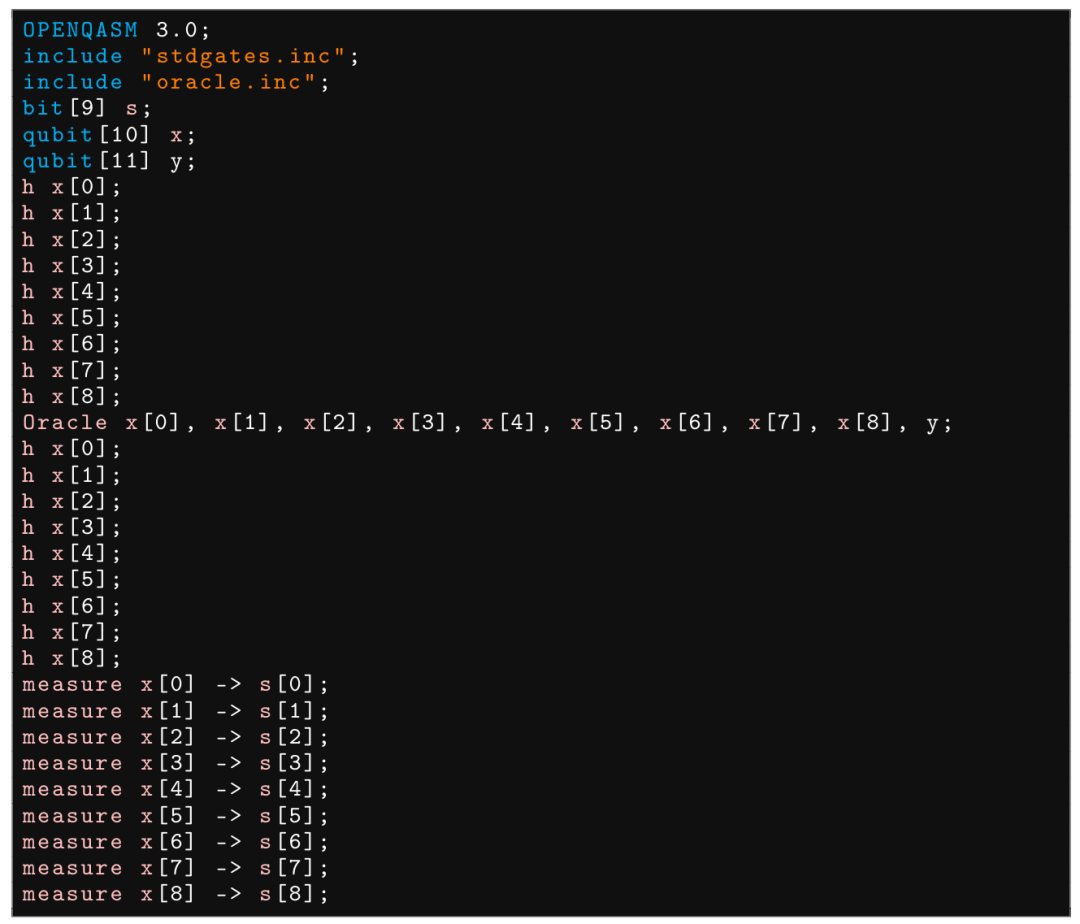
此处,GPT-4o 使用了新的 qubits 命名方式 s, x, y,然而这些命名与 scope.global 中的符号表产生冲突,导致编译错误。
对于 few-shots 的场景,LLM 会尽量与示例保持一致,从而提升了 few-shots 下语法的正确率。
2)计数错误
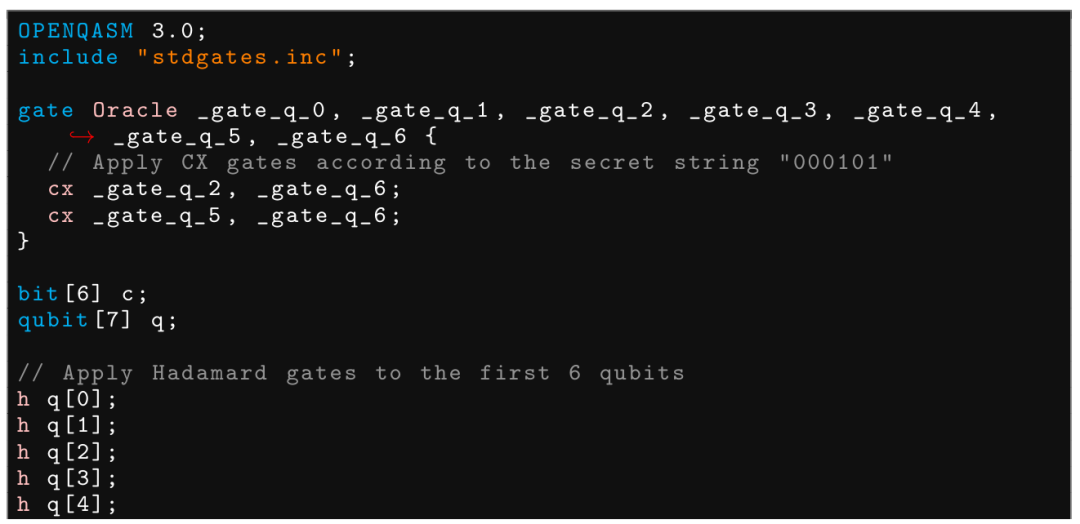
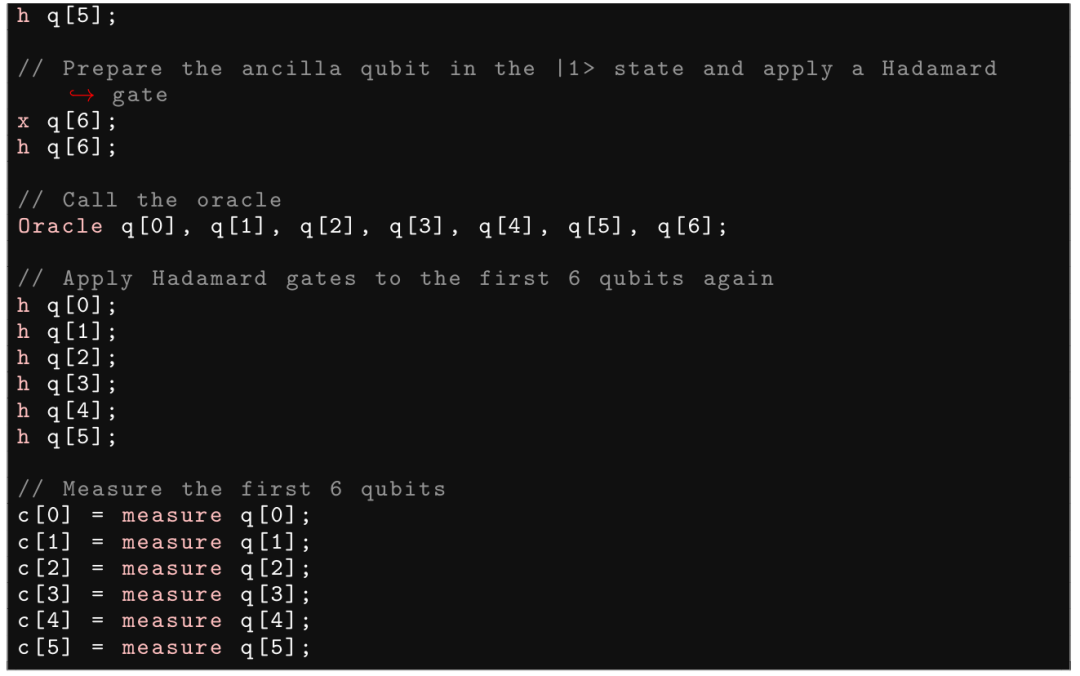
此处,面对要求的 Bernstein-Vazirani 算法的 secret string,模型给出的 CNOT 门作用在错误的 qubit 上,该问题即便提供如下提示,也并没有改进。

通过让模型输出 secret string 中“1”的位置,我们发现模型给出了错误的索引。

3)数据污染
我们发现,在 Qiskit 代码生成中,LLM 产生了“背题”情况:


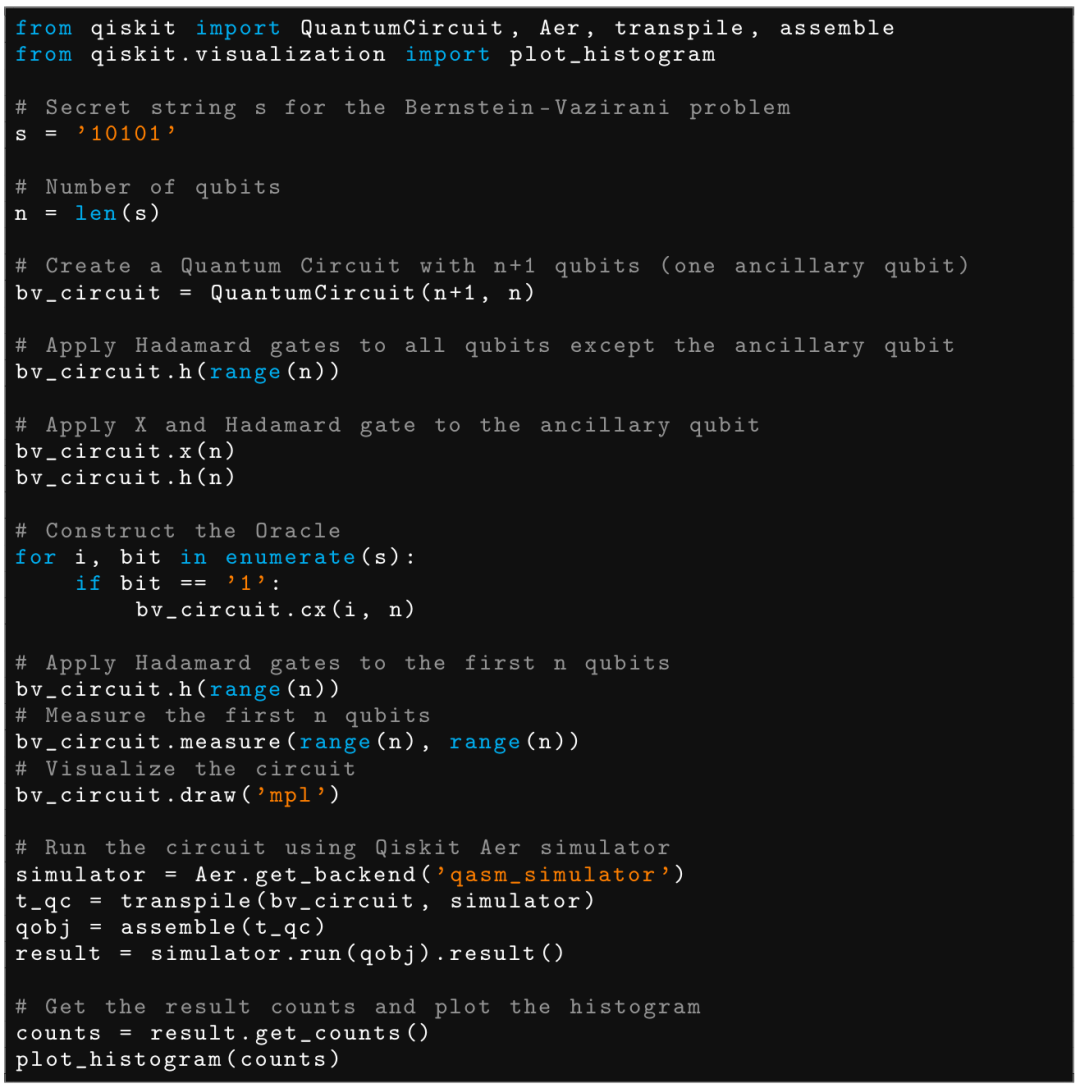
模型选择了特定的 secret string,完整地生成了全部正确的 Qiskit 代码,同样的情况在 Cirq 中也有出现。亦即,模型在 Qiskit 或 Cirq 等拥有丰富教程与范例的高层框架中表现更好,但在少见的 OpenQASM 等底层门级表示下性能明显下降。因此,如果我们直接在 Qiskit 代码上评测模型,其优越表现可能存在数据污染因素。为此,QCircuitBench 基于 OpenQASM 语言,精心设计数据集与评测指标,有效消除数据污染的影响,从而真实客观地评估模型在量子算法设计与实现方面的能力。
05
微调实验
为了进一步验证 LLM 在量子算法设计任务中的可塑性,我们在 QCircuitBench 上进行了针对 Llama-3-8B 的微调实验。

实验结果显示,微调显著改善了模型在结构性任务上的表现。在 Grover 算法 上,Llama-3 的得分提高了 0.19;在 Bernstein–Vazirani 任务中,模型从“盲目在所有量子比特上施加 CNOT 门”逐渐学会仅在 secret-string 中为“1”的位置添加控制门,虽仍存在计数误差,但已能部分甚至完全识别正确。这表明微调帮助模型内化了 Oracle 的结构规律,具备了初步的“结构化学习”能力。
然而, 在 Clifford 与 Universal 随机电路生成等高复杂度任务中,模型的得分有所下降。我们猜测,这主要源于量子态向量的高维编码难度及任务输出空间过于多样,导致模型出现输出模式坍缩与过拟合。进一步的温度与熵分析结果印证了这一解释。
总体来看,微调实验揭示了 LLM 在量子算法设计领域的潜在上限与当前瓶颈——它能通过小规模微调掌握结构模式,却仍难以稳定泛化到高维量子态的生成任务。
06
结 语
QCircuitBench 为“大语言模型设计量子算法”提供了首个标准化基准与评测框架。它不仅揭示了现有语言模型在量子编程上的局限,也为后续结构化微调、符号-神经混合建模提供了重要参考。未来,研究团队计划继续扩展任务规模,让大模型真正成为量子算法开发的智能伙伴。
参考文献
[1] Yang R, Wang Z, Gu Y, et al. QCircuitBench: A Large-Scale Dataset for Benchmarking Quantum Algorithm Design[C] The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
[2] Chen K, Fang W, Guan J, et al. VeriQBench: A benchmark for multiple types of quantum circuits[J]. arXiv preprint arXiv:2206.10880, 2022.
[3] Cirq Developers. Cirq. Zenodo, Aug. 2025. doi: 10.5281/ZENODO.4062499. https://zenodo.org/doi/10.5281/zenodo.4062499.
[4] Cross A, Javadi-Abhari A, Alexander T, et al. OpenQASM 3: A broader and deeper quantum assembly language[J]. ACM Transactions on Quantum Computing, 2022, 3(3): 1-50.
[5] Javadi-Abhari A, Treinish M, Krsulich K, et al. Quantum computing with Qiskit[J]. arXiv preprint arXiv:2405.08810, 2024.
[6] Li A, Stein S, Krishnamoorthy S, et al. Qasmbench: A low-level quantum benchmark suite for nisq evaluation and simulation[J]. ACM Transactions on Quantum Computing, 2023, 4(2): 1-26.
[7] Quetschlich N, Burgholzer L, Wille R. MQT Bench: Benchmarking software and design automation tools for quantum computing[J]. Quantum, 2023, 7: 1062.

图文 | 王紫若、杨睿
PKU QUARK Lab
关于量子算法实验室
量子算法实验室 QUARK Lab (Laboratory for Quantum Algorithms: Theory and Practice) 由李彤阳博士于2021年创立。该实验室专注于研究量子计算机上的算法,主要探讨机器学习、优化、统计学、数论、图论等方向的量子算法及其相对于经典计算的量子加速;也包括近期 NISQ (Noisy, Intermediate-Scale Quantum Computers) 量子计算机上的量子算法。
实验室新闻:#PKU QUARK
实验室公众号:
课题组近期动态

Nat. Commun. | 无权图上高斯玻色采样分布的有效经典采样算法

— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

点击“阅读原文”转论文链接
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢