
UniME-V2团队 投稿
量子位 | 公众号 QbitAI
统一多模态嵌入模型是众多任务的技术基石。
当前主流方法通常采用批内负例挖掘策略,通过计算查询-候选对的相似度进行训练。
但这类方法存在明显局限:难以捕捉候选样本间细微的语义差异,负例样本多样性不足,且模型在区分错误负例与困难负例时的判别能力有限。
针对这些问题,团队提出全新解决方案——基于多模态大模型语义理解能力的统一多模态嵌入模型UniME-V2。
该方法首先通过全局检索构建潜在困难负例集,随后创新性地引入“MLLM-as-a-Judge”机制:利用MLLM对查询-候选对进行语义对齐评估,生成软语义匹配分数。
这一设计带来三重突破:
- 以匹配分数为依据实现精准困难负例挖掘,有效规避错误负例干扰
- 确保筛选出的困难负例兼具多样性与高质量特性
- 通过软标签机制打破传统一对一的刚性映射约束

通过将模型相似度矩阵与软语义匹配分数矩阵对齐,使模型真正学会辨析候选样本间的语义差异,显著提升判别能力。
为进一步提升性能,团队基于挖掘的困难负例训练出重排序模型UniME-V2-Reranker,采用配对与列表联合优化策略。
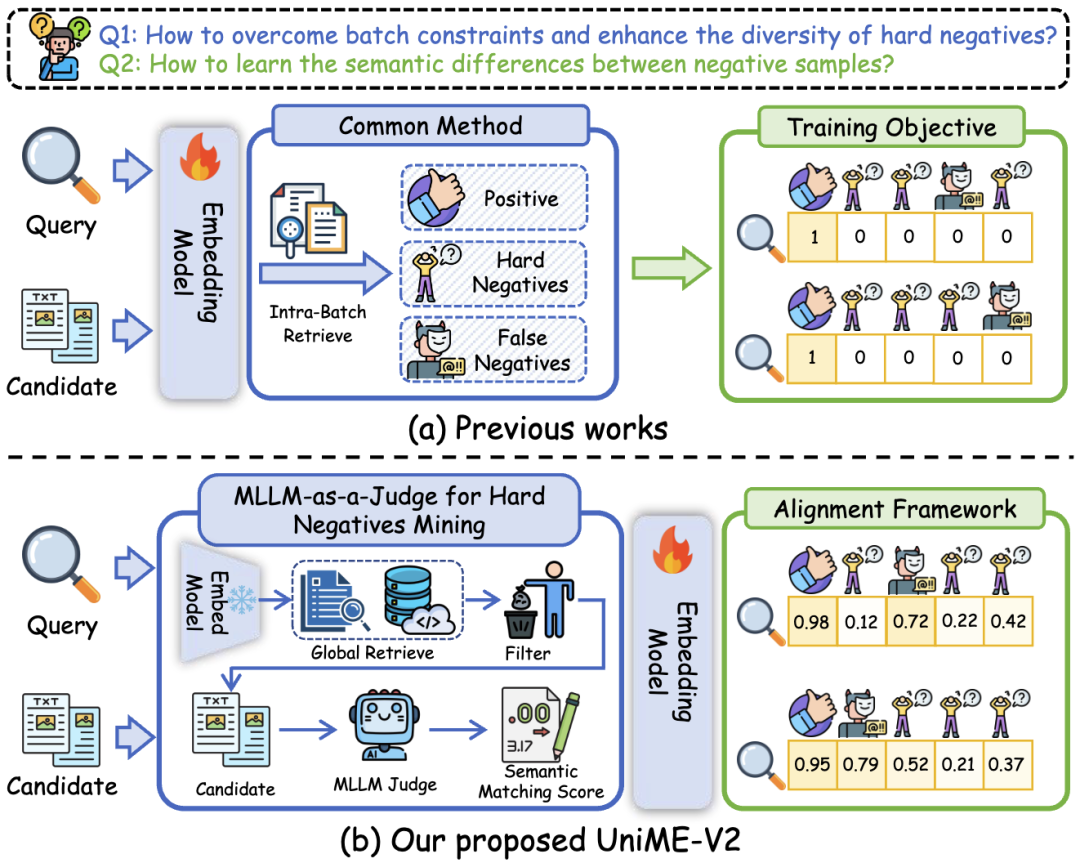
图1 UniME-V2与以往方法的本质不同,在于巧妙利用了多模态大模型(MLLM)的深层语义理解能力。它不仅能用此能力精准挖掘“困难负例”,更能生成一个软语义匹配分数,如同一位资深导师,指导模型学会辨别候选样本间微妙的语义差异。
方法
MLLM-as-a-Judge 困难负样本挖掘
过去的研究主要依赖于批内硬负样本挖掘,其中计算查询-候选嵌入相似性以采样负样本。
然而,这种方法通常受到负样本多样性有限和嵌入判别能力不足的困扰,难以有效区分错误和困难的负样本。
为了克服这些挑战,如图2所示,首先利用全局检索构建一个潜在的困难负样本集。
之后,利用MLLM的强大理解能力来评估每个查询-候选对的语义对齐性,并生成软语义匹配分数。
这个分数指导了硬负样本挖掘,使得能够识别出多样化和高质量的困难负样本,同时减少错误负样本的影响。
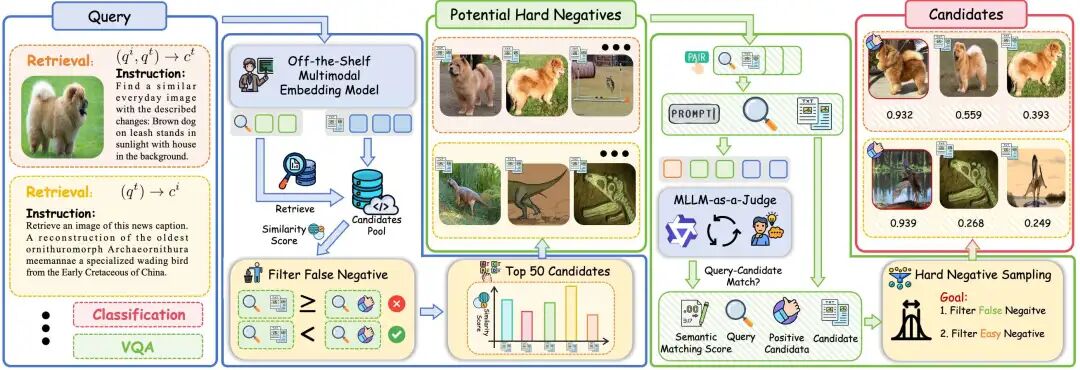
图2:基于MLLM-as-a-Judge的困难负样本挖掘流程。我们首先利用现有的多模态嵌入模型进行全局检索,构建一个潜在的困难负样本集。然后,利用MLLM强大的理解能力根据语义对齐性对查询-候选对进行评分,从而精确识别困难负样本。
潜在困难负样本集合为了从全局样本中提取更高质量的困难负样本,首先使用VLM2Vec为查询和候选生成嵌入。
接着,为每个查询检索出50个最相关的候选。
为了应对错误负样本并增加多样性,我们基于查询-候选相似度分数设定一个相似度阈值
其中
语义匹配分数在构建潜在的困难负样本集

基于MLLM判断的训练框架
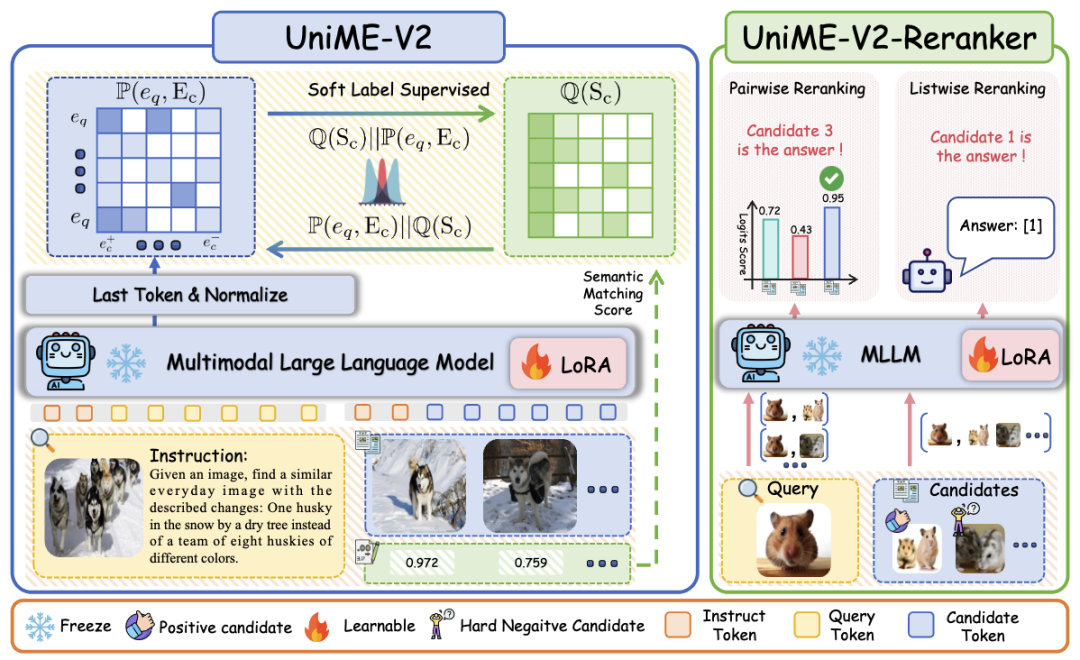
UniME-V2为此提出了一个基于MLLM判断的分布对齐框架,如图3所示,利用软语义匹配分数作为监督信号来提高表征性能。
具体来说,给定一个查询
基于语义匹配分数
为了增强学习的稳健性并确保矩阵对称性,采用了JS-Divergence,这是KL-Divergence的一种对称替代。最终的损失函数
除此之外,受前人工作启发,UniME-V2联合pairwise和listwise训练了一个重排序模型UniME-V2-Reranker(如图3所示)来提高基于初始嵌入的检索精度。
在成对训练中,为每个查询
其中
然后提示UniME-V2-Reranker输出真实位置,公式为:
最终的损失函数定义为
实验
多模态检索
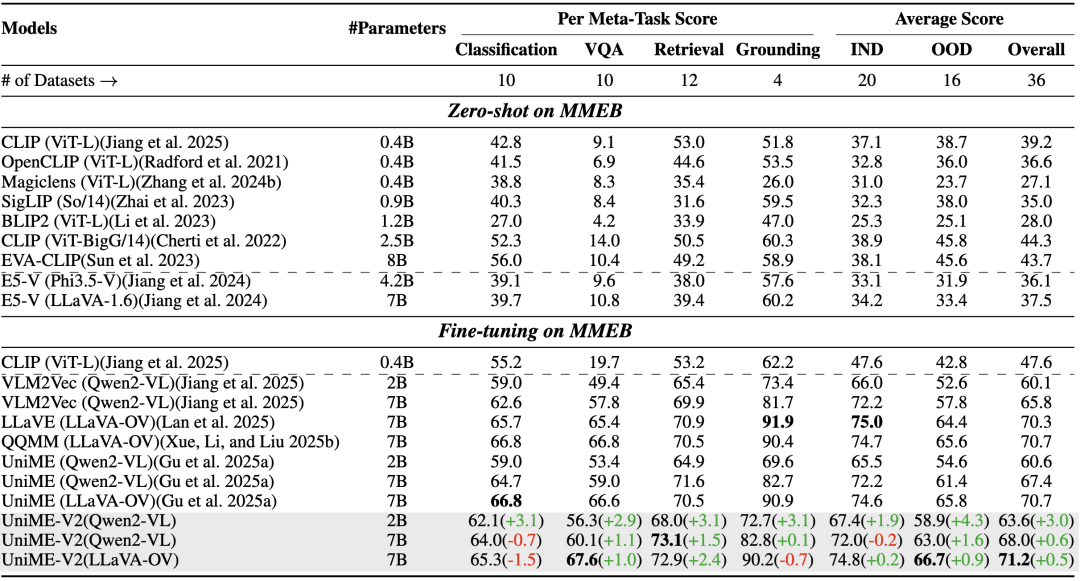
表1展示了在相同训练数据和配置下UniME-V2与现有基线模型在MMEB基准上的性能对比。
UniME-V2在各种基础模型上均有显著的性能提升。
具体来说,UniME-V2在Qwen2-VL-2B和7B模型上分别比VLM2Vec高出3.5%和2.2%。
当基于LLaVA-OneVision作为基础时,UniME-V2比包括QQMM、LLaVE和UniME在内的之前的最先进模型提高了0.5%-0.9%。此外,UniME-V2在分布外数据集上的得分为66.7,凸显其鲁棒性和卓越的迁移能力。
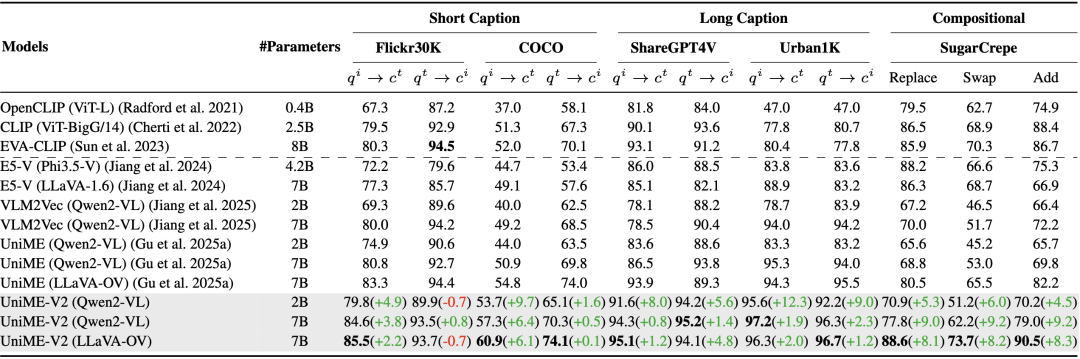
表2:在短描述(Flickr30K, MS-COCO)、长描述(ShareGPT4V, Urban1K)和组合(SugarCrepe)数据集上的零样本文本-图像检索结果。
跨模态检索
如表2所示,在零样本跨模态检索任务上评估UniME-V2。对于短描述数据集,包括Flickr30K和MS-COCO,UniME-V2在图像到文本检索中比UniME表现出了2.2%-9.7%的性能提升。
在文本到图像检索中,其性能与UniME相当,这主要归因于两个因素:
(1)MMEB训练集中文本到图像数据的比例有限;
(2)短描述中的语义信息不足。
对于长描述跨模态检索任务,UniME-V2在ShareGPT4V和Urban1K上取得了显著改进,这得益于其增强的区分能力和详细描述提供的丰富语义内容。
值得注意的是,与EVA-CLIP-8B相比,UniME-V2展示了更为稳健的检索性能,这主要因为其通用多模态嵌入能显著减少模态间的差距(如图4所示)。

图4:EVA-CLIP-8B与UniME-V2(LLaVA-OneVision-7B)之间的表示分布对比。
组合跨模态检索
基于SugarCrepe评估UniME-V2模型区分困难负样本的能力。
如表2所示,UniME-V2在所有评估指标上均表现出卓越性能。
与UniME相比在使用Qwen2-VL-2B时性能提升了5.3%,6.0%,4.5%。当模型从2B扩展到7B后也实现了9.0%,9.2%,9.2%的性能提升。
此外,与EVA-CLIP-8B相比,UniME-V2还显示出2.7%,3.4%,和3.8%的改进,凸显其在区分困难负样本上的强大能力。
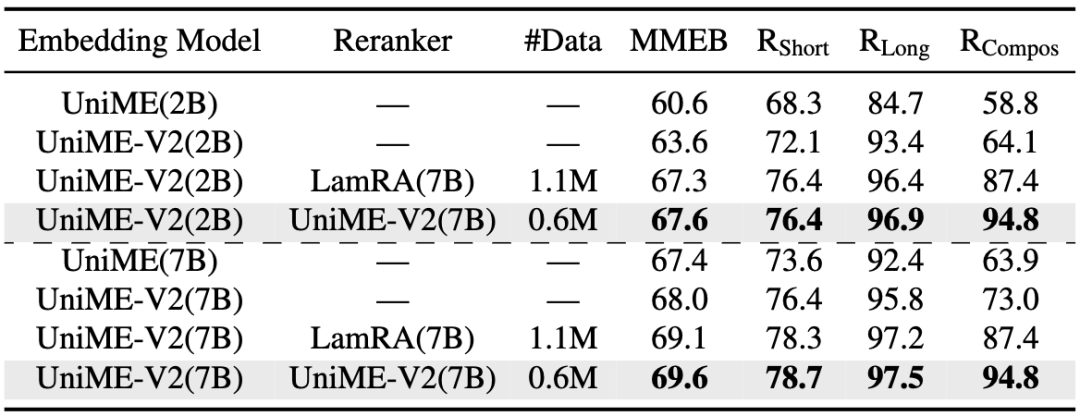
表3:使用UniME-V2 (Qwen2-VL-7B) 和 UniME-V2 (Qwen2-VL-2B) 比较LamRA与UniME-V2-Reranker的重排序性能。
重排序对比
在表3中基于top5检索结果对比了LamRA与UniME-V2-Reranker的性能。为确保公平,使用与LamRA相同的训练参数和基础模型(Qwen2.5-VL-7B)。
当使用LamRA和UniME-V2-Reranker对UniME-V2 (Qwen2-VL-2B) 检索结果进行重排后在四个下游任务上均提升了性能。
UniME-V2-Reranker在只使用一半数据的情况下始终获得更优结果。类似地,使用UniME-V2 (Qwen2-VL-7B) 进行检索时,UniME-V2-Reranker的表现也超过了LamRA,在四个任务中分别获得了0.5%,0.4%,0.3%,和7.4%的性能提升。
值得注意的是,UniME-V2-Reranker在组合理解检索任务中展示了对LamRA的显著优势,这归功于其利用MLLM的理解能力提取多样化和高质量的困难样本,有效增强了模型的区分能力。
论文:
https://arxiv.org/abs/2510.13515
GitHub:
https://github.com/GaryGuTC/UniME-v2
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢