

作者:田小幺
编辑:椰椰
转载请联系本公众号获得授权,并标明来源
加州大学伯克利分校、剑桥大学、牛津大学等全球十余所科研机构的团队联合攻关,推出了首个面向天文学的大规模多模态基础模型家族——AION-1,通过统一的早期融合 backbone 网络,将图像、光谱和星表数据等异质观测信息进行集成建模,不仅在零样本场景下表现优异,其线性探测准确率也可媲美甚至超越针对特定任务专门训练的模型。
基于 Transformer 架构的基础模型,已在自然语言处理与计算机视觉等领域引发深刻变革,推动技术从「一事一模型」的定制范式,迈向通用化的新阶段。然而,当这类模型进入科学研究领域时,却遭遇了明显的水土不服。科学观测数据来源多样、格式不一,且常包含各类观测噪声,使得数据呈现出显著的「复杂异质性」。这一现实使得科学数据分析陷入两难:若仅处理单一类型数据,则难以充分挖掘其潜在价值;若依赖人工设计的跨模态融合方案,又难以灵活适配多样的观测场景。
在众多科学领域中,天文学恰为这类模型提供了一个理想的试验场。其海量公开观测数据为模型训练提供了充足「养料」;同时,观测手段极为丰富,涵盖星系成像、恒星光谱、天体测光等多种方式,这种多维度的数据形态天然契合多模态技术研发的需求。
事实上,已有研究尝试构建天文学多模态模型,但这些尝试仍存在明显局限:大多聚焦于超新星爆发等单一现象,依赖「对比目标(contrastive objectives)」作为核心技术,导致模型既难以灵活应对任意模态组合,也难以捕捉模态之间除浅层关联之外的关键科学信息。
为突破这一瓶颈,来自加州大学伯克利分校、剑桥大学、牛津大学等全球十余所科研机构的团队联合攻关,推出了首个面向天文学的大规模多模态基础模型家族 AION-1(天文全模态网络,AstronomIcal Omni-modal Network),通过统一的早期融合骨干网络,将图像、光谱和星表数据等异质观测信息进行集成建模,不仅在零样本场景下表现优异,其线性探测准确率也可媲美针对特定任务专门训练的模型。
相关研究成果以「AION-1: Omnimodal Foundation Model for Astronomical Sciences」为题,已收录于 NeurIPS 2025。
研究亮点:
* 提出 AION-1 模型家族,这是一系列基于 token 的多模态科学基础模型,参数规模覆盖 3 亿至 31 亿,专门设计用于处理高度异质的天文观测数据,支持任意模态组合。
* 开发了定制化的 Tokenization 方法,能够将来源多样、格式不一的天文数据转化为统一表征,构建出单一连贯的数据语料库,有效克服了科学数据中常见的异质性、仪器噪声和来源差异等问题。
* AION-1 在广泛的科学任务中表现优异。即便仅通过简单的前向探测,其性能即可达到 SOTA 水平,在低数据量场景下更是显著优于有监督基线。这一特性使下游研究人员无需进行复杂微调即可直接高效使用。
* AION-1 通过系统解决数据异质性、噪声和仪器多样性等核心挑战,为天文学乃至其他科学领域提供了可行的多模态建模范式。
论文地址:
https://openreview.net/forum?id=6gJ2ZykQ5W
关注公众号,后台回复「AION-1」获取完整 PDF
更多 AI 前沿论文:
https://hyper.ai/papers
AION-1 预训练基石:MMU 数据集与多类型天文数据 Tokenization 方案
AION-1 的预训练基于多模态宇宙(Multimodal Universe, MMU)数据集。如下图所示,这是一个专为机器学习任务构建的公开天文数据集合,整合了来自 5 大巡天项目的多样化观测信息。
具体包括:由超新星相机(HSC)和遗产成像巡天提供的星系图像;来自暗能量光谱仪(DESI)和斯隆数字巡天(SDSS)的高分辨率光谱及对应天体的距离信息;以及盖亚卫星(Gaia)记录的低分辨率光谱,同时包含银河系恒星的高精度测光与位置数据。
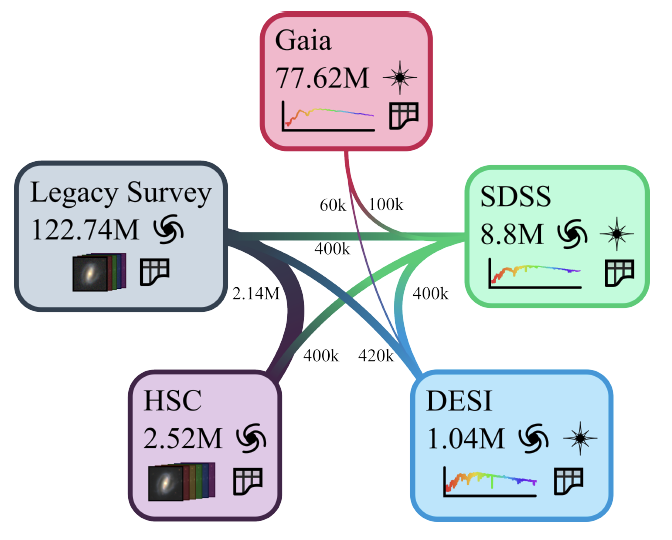
训练数据混合体
为实现对这些多来源、多格式数据的统一处理,AION-1 提出了一种通用的 Tokenization 方案(Universal Tokenization)。该方案能够将图像、光谱、数值等不同形式的天文数据,转换为模型可识别和处理的统一表示形式,从而有效应对天文数据来源多样、格式不一的核心挑战。Tokenization 过程为每种数据类型设计了专用的转换器,使其能够适配不同仪器的数据输出,确保同类数据在语义上对齐,同时避免针对同一类型的不同来源数据重复训练模型。
对于多波段成像数据(Multiband imaging data),针对星系图像在分辨率、通道数量、波长覆盖和噪声表现等方面的差异,图像 tokenizer 采用了灵活的通道嵌入设计,既能适应不同通道数的输入,也能在表示中融入望远镜来源等信息。其核心网络基于改进的 ResNet 结构,配合一种有限取值的量化技术,使得单一模型能够统一处理来自多个观测流程的图像数据。训练过程中,模型采用了一种考虑噪声权重的损失评价方法,充分利用成像过程中已知的噪声信息以提高重建质量。
对于光谱数据(Spectroscopic Data),不同仪器在信号强度、波长范围和分辨能力上的差异,通过将其统一标准化并映射到共享的波长网格上来解决,从而实现对多仪器、多目标光谱的联合处理。该 tokenizer 基于 ConvNeXt V2 网络结构,采用一种无需预设编码的量化技术,并同样使用加权噪声损失函数来融合不同巡天的噪声特性。
在表格/标量数据(Tabular/Scalar Data)的处理上,AION-1 放弃了传统难以适应大数值范围的连续表示方法,转而采用基于数据分布统计的分段离散化策略。这种方法使得数值分布更为均匀,并在信息集中的区域最大限度地减少了转换误差。
除了常规的测光图像,模型还为分割图(Segmentation Maps)、物理属性图(Property Maps)等空间分布的数值场数据设计了专用 tokenizer。它适用于取值范围在 0 到 1 之间的标准化图像,基于卷积网络构建,采用与图像tokenizer 相似的量化技术,并使用灰度星系图像及对应的分割图进行训练。
对于用于天体定位的椭圆边界框数据(Bounding Ellipses,每个目标由位置坐标、椭圆形状和大小共 5 个参数描述),Tokenization 过程通过将坐标映射到最近像素点并对椭圆属性进行量化来实现。为处理图像中目标数量不定的情况,所有检测目标被转化为一个序列,并按照距离图像中心的远近进行排序,从而形成一个统一且规范的表示结构。
AION-1:面向天文科学的多模态基础模型
AION-1 的架构借鉴了当前主流的早期融合多模态模型思路,并特别采用了 4M 模型(苹果与 EPFL 合作开发的多模态 AI 训练框架)提出的可扩展掩码建模方法(scalable multimodal masked modeling scheme)。其核心思路是:将所有类型的数据转换为统一的 token 表示后,随机遮盖其中一部分内容,再由模型学习恢复被遮盖的部分。通过这种方式,模型能够从图像、光谱、数值等不同形式的数据中自动发现它们之间的内在关联。
具体来说,每个训练样本包含 M 种不同类型的数据序列。模型在训练过程中会从中随机选择 2 部分:一部分作为输入信息,另一部分作为需要重建的目标。由于这两部分都是从全部数据中随机选取的,使得模型既能掌握每种数据自身的特征,又能理解不同数据类型之间的对应关系。
在技术实现上,如下图所示,AION-1 采用了专为多任务设计的 Transformer 编码器-解码器结构。除了标准的编码器和解码器外,其创新之处在于为每种数据类型设计了独特的嵌入机制。对于每一种数据类型,模型都会配备专门的转换函数、可学习的类型标识参数和位置参数。
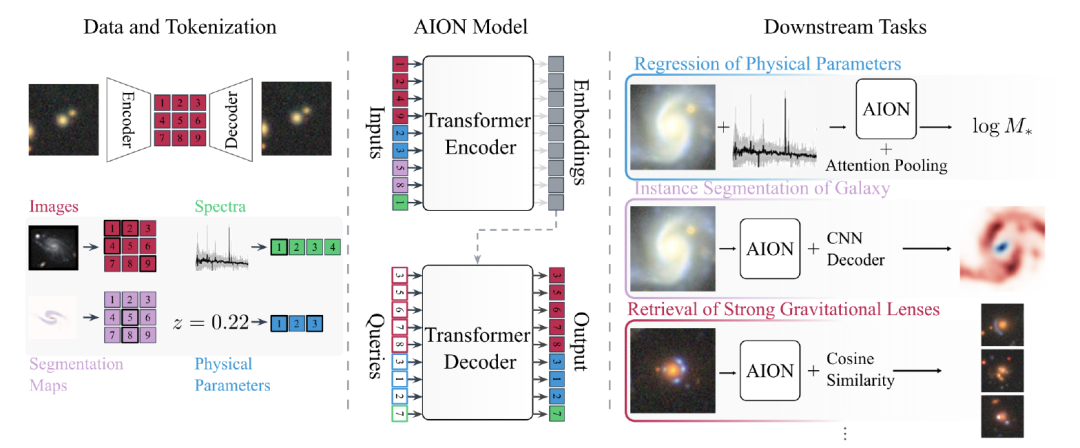
AION-1 的 Transformer 框架
特别值得一提的是,模型为每种数据类型与每个数据来源的组合都分配了独立的类型标识。即使是同为图像数据,只要来自不同的观测设备,就会被赋予不同的标识。这样的设计让模型能够识别数据的来源特征,而这些来源信息往往隐含着数据质量、分辨率等重要属性。
模型的训练效率在很大程度上取决于如何合理选择需要遮盖的数据内容。研究发现,原先 4M 模型采用的采样方法在处理长度差异大的数据时效果不佳,容易产生大量无效训练样本。为此,AION-1 提出了一种更高效的简化策略:在确定输入内容时,先设定一个总数上限,然后随机选择一种数据类型并从中选取部分内容,不足的部分再从其他数据类型中补充。在确定需要重建的目标内容时,则采用偏向小规模的采样方式来确定每种数据类型需要重建的数量。这种方法既减少了每个训练样本的计算量,又确保了训练过程与实际使用场景的一致性。
为了全面评估模型性能,研究团队训练了 3 个不同规模的 AION-1 版本:基础版(3 亿参数)、大型版(8 亿参数)和超大型版(30 亿参数)。训练过程采用 AdamW 优化器,设置了相应的学习参数,总共训练 20.5 万步。学习率的调整采用先升温后衰减的策略。如下图所示,该研究展示了不同模型规模以及是否包含 Gaia 卫星数据对效果的影响,为后续模型选择提供了参考。
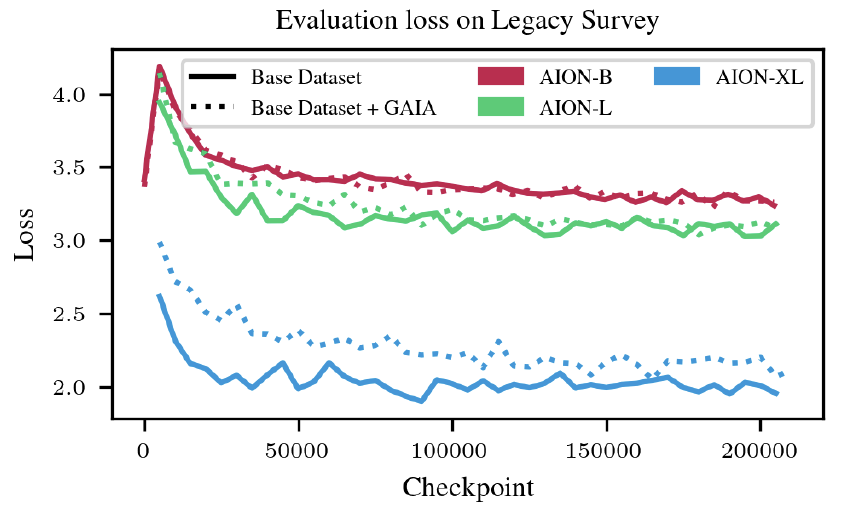
不同模型规模基于 Legacy 巡天的 AION-1 测试损失
经过完整训练后,AION-1 具备了多种实用的生成功能,支持从数据补全到跨设备数据转换等任务。其核心优势在于能够理解所有数据类型之间的整体关联,因此即使在只有部分观测数据的情况下,也能生成物理属性一致的其他类型数据样本。
实验结果:红移精度提升 16 倍,多模态天文 AI 性能大幅突破
AION-1 的突破性在于能够直接生成具备明确物理意义且不受数据类型限制的通用表征,无需依赖针对特定任务设计的复杂监督流程。基于这一机制,模型在跨模态生成(Cross-Modal Generation)与标量参数估计(Scalar Posterior Estimation)两大关键场景中表现优异。
在跨模态生成方面,AION-1 实现了高维数据的条件生成,有效支持跨设备数据转换与观测质量提升。最具代表性的应用是利用 Gaia 卫星的低分辨率数据生成高分辨率 DESI 光谱:如下图所示,尽管前者数据稀疏度高出 50-100 倍,但模型仍能精准还原光谱的谱线中心、宽度和振幅等特征。这一进展使得基于广泛可得的低分辨率数据开展精细天体分析成为可能,对降低研究成本、提升数据利用率具有重要意义。

AION-1 生成高分辨率光谱
在参数估计方面,AION-1 能够直接推断量化标量的取值分布。以红移估计(Redshift Posterior Estimation)为例,如下图所示,典型星系在三种信息量递增条件下的结果:仅使用基础测光数据时分布较分散;加入多波段成像后明显收敛;进一步引入高分辨率光谱后,估计精度显著提升,表明模型能有效融合多源信息优化估计结果。
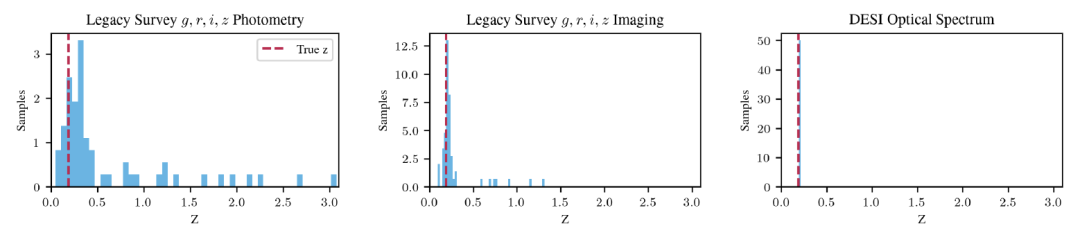
AION-1 的红移估计
为系统验证模型能力,研究团队还从 4 个方向展开实验:
* 物理属性估计(Physical Property Estimation)
针对星系恒星质量、恒星表面温度等通常需要高分辨率观测才能推导的参数,研究探索使用 AION-1 从低分辨率数据中直接估计。在 12 万个星系样本上的测试表明,其表现优于或匹配专用监督模型;在 24 万颗恒星样本的测试中,甚至在「基于 Gaia 低分辨率数据预测高分辨率参数」任务上超越了专门优化的基线模型。
* 基于专家标注的语义学习(Learning from Semantic Human Labels)
在星系形态分类任务中(8,000 个标注样本),AION-1 的准确率不仅高于从零训练的专用模型,还可与使用数十倍标注数据训练的先进模型媲美。在星系结构语义分割任务中(2,800 个样本),其生成结果与人工标注重合度高,性能超过简单全卷积基线。
* 低数据量场景性能(Performance in Low-Data Regime)
针对天文研究中常见标注稀缺的问题,实验表明 AION-1 在数据有限时的优势更加明显,其表现可匹配甚至超越需要多一个数量级训练数据的监督模型。
* 稀有目标检索(Similarity-Based Retrieval)
面对强引力透镜等稀有天体(占比约 0.1%)、缺乏足够标注的挑战,AION-1 通过表征空间相似度检索,在旋涡星系、合并星系和强透镜候选体三类目标上均表现优异,检索效果超越其他先进自监督模型。
这些实验结果共同表明,AION-1 为多模态天文数据分析提供了统一而高效的解决方案,特别是在数据稀缺和跨模态推理场景中展现出显著优势。
多模态 AI 赋能天文研究,学界与产业界的协同突破
近年来,「多模态 AI 驱动天文研究」已成为全球学术界与工业界共同关注的焦点,一系列突破性成果正在重塑天文数据的处理与应用模式。
在学术界,研究者致力于将多模态融合能力与具体天文问题紧密结合。例如,麻省理工学院媒体实验室在 2025 年公布的空间探索计划中,将多模态 AI 与扩展现实技术相结合,开发出面向月球驻留任务的智能分析系统。该系统能够融合卫星遥感图像、环境传感器读数与设备运行状态等多源信息,为模拟月球基地的资源管理与风险预警提供实时决策支持。
与此同时,牛津大学等机构的研究团队构建了一款基于深度学习的筛选工具,可从数千个数据警报中精准识别出源自超新星爆发的有效信号,将天文学家所需处理的数据量降低约 85%。该虚拟研究助理仅需 1.5 万个训练样本和普通笔记本电脑的算力,即可完成训练,并将日常人工筛查工作转为自动化流程。最终模型在保持高识别准确率的同时,将误报率控制在 1% 左右,显著提升了科研效率。
论文标题:The ATLAS Virtual Research Assistant
论文链接:
https://iopscience.iop.org/article/10.3847/1538-4357/adf2a1
产业界则通过产品化路径推动多模态 AI 在天文领域的实际部署。英伟达于 2024 年与欧洲南方天文台(ESO)合作,将其 AI 推理优化技术集成至甚大望远镜的光谱数据处理流程中。借助 TensorRT 对多模态融合模型的加速,遥远星系的光谱分类效率提升达三倍。
IBM 在 2025 年进一步与 ESO 合作,利用多模态 AI 优化 VLT 的观测调度系统。通过综合气象预测、天体亮度变化与设备负载等多元信息,实现观测计划的动态调整,使对变星等时域目标的捕获成功率提高 30%。
此外,Google DeepMind 与 LIGO 及 GSSI 合作,提出名为「深度环路整形」的控制方法,以提升引力波探测器的控制精度。该控制器在真实 LIGO 系统中进行了验证,其实际性能与仿真结果高度一致。相比原有系统,新技术将噪声控制能力提高了 30 至 100 倍,并首次彻底消除了系统中最不稳定、最难抑制的反馈回路噪声源。
论文标题:Improving cosmological reach of a gravitational wave observatory using Deep Loop Shaping
论文地址:https://www.science.org/doi/10.1126/science.adw1291
可以看出,构建多模态通用表征已成为天文与人工智能交叉领域的明确趋势。学术界通过深入科学问题持续打磨技术内核,工业界则凭借工程化能力推动技术落地与规模化应用。两者的协同推进,正逐步打破高成本观测与复杂数据处理对天文研究的传统制约,使更多研究者能够借助人工智能探索宇宙更深处的奥秘。
参考链接:
1.https://www.media.mit.edu/groups/space-exploration/updates/
2.https://www.eso.org/public/news/eso2408/
3.https://www.eso.org/public/news/eso2502/






戳“阅读原文”,免费获取海量数据集资源!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢