
药物发现是一个跨越生物学、化学、药理学和计算科学的复杂、迭代过程。人工智能(AI)可以加速这一过程,但往往与生物学现实不完全契合。针对这一问题,南洋理工大学研究团队于2025年10月24日在《Drug Discovery Today》上发表文章,题为“Gaps between medical biology and AI drug discovery”。文章重点指出了AI驱动的药物发现中存在的三个关键鸿沟,并提出了一个生物学情境化的AI框架,为医学生物学与AI药物发现领域的研究者提供了相应的指导原则。

背景
药物发现是一个复杂的、多阶段的过程,涉及靶点识别、苗头化合物筛选、先导化合物优化、临床前测试以及临床试验等环节。每一阶段都面临独特的挑战,需要兼具实验精确性与科学解释能力,以识别并开发出安全且有效的治疗性化合物。尽管医学生物学领域已取得显著进展,药物发现依然是一项耗时、昂贵且高失败率的工作,尤其在临床前与临床阶段。这种持续存在的低效率凸显了开发创新方法的迫切需求,以加速并优化药物发现流程。
人工智能(AI)在药物发现中展现出变革性潜力,可利用其强大能力进行数据分析、分子相互作用建模以及候选分子优化。AI在虚拟筛选、生物活性预测以及多目标分子设计等任务中表现尤为突出。然而,当前的AI方法往往难以充分应对医学生物学的复杂性,存在若干关键缺口。这些缺口阻碍了AI在药物发现中实现其作为系统性解决方案的全部潜力。
本文系统审视了医学生物学与AI药物发现之间的三大鸿沟,并探讨了这些问题如何限制当前AI方法的有效性。通过应对这些挑战,旨在描绘出一条通向更具整合性、兼具生物学内涵的AI药物发现路径,以覆盖整个研发流程。
鸿沟1: AI模型中对结合亲和力与生物活性的误解
结合亲和力与生物活性本质上是两个截然不同的概念,然而许多AI驱动的药物发现方法却使用同一种模型来同时预测二者。从定义上看,生物活性指的是某种物质在生物体系中诱导生理或生化效应的能力,通常用于描述分子、药物或化学物质对生物体的影响;而结合亲和力则是指生物分子与其结合配体之间相互作用的强度。两者之间并不存在单调对应关系。如图1别构调节剂例子所示,较低的结合亲和力可通过减小分子量与增强脂溶性得到补偿,从而实现相似的结合效率或生物活性。
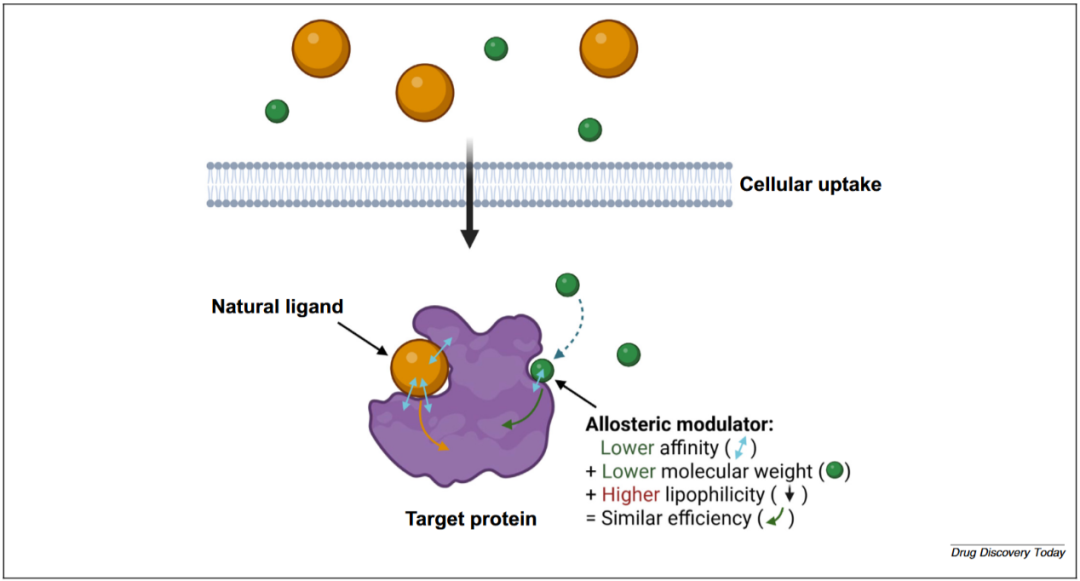
图1 结合亲和力与生物活性
尽管结合亲和力与生物活性密切相关,但它们是通过不同的实验技术进行评估的,会在AI预测所用的数据中引入显著差异。生物活性通常通过功能性实验测定,这些实验评估化合物引起的生理或生化效应,如细胞活力变化或受体激活等。常用的指标包括使反应增强或抑制50%的化合物浓度(EC₅₀/IC₅₀)。结合亲和力则通常以平衡解离常数(KD)来表征,通过生物物理方法获得,例如表面等离子体共振(SPR)与荧光各向异性,它们能够直接测量分子相互作用的强度与稳定性。
由于检测方法的多样性,即便是在测量相同的生物活性指标时,也可能产生不一致的结果。这些差异对AI模型提出了重大挑战。当前的AI模型往往依赖于标准化的生物活性数据,而忽视了实验条件与分子相互作用复杂性等细微差异。因此,模型在不同实验情境下往往难以实现良好的泛化能力,尤其当训练数据混合来自不同测量背景的实验结果时,这种问题更加突出。
忽略这些实验方法上的差异,AI模型容易过度简化复杂的生物活性关系,从而导致预测不准确,或在不同数据集之间模型可迁移性较差。要改进对生物活性的预测,可以扩展AI模型,使其能够评估配体结合构象对活性位点阻塞程度的影响。可利用分子对接生成参考数据,以模拟实验条件下的分子群体行为,从而为AI模型提供更具代表性的输入。还可通过引入机制性方程,如Cheng–Prusoff方程与Hill方程,将实验条件(例如蛋白质或底物浓度)与观测到的生物活性结果相联系。通过对这些测量差异进行建模与校正,AI模型能够区分实验依赖性误差与真实的分子相互作用,从而在真实药物发现应用中具备更高的稳健性与可靠性。
鸿沟2:AI中过度依赖简化生物活性指标的问题
图2展示了传统生物活性测量方式、AI应用中常用的简化指标以及药物发现中更深层次的生物机制之间的脱节。标准化的生物活性数值(如IC₅₀或EC₅₀)在数据集中占据主导地位,如ChEMBL与PubChem数据库。这些指标虽然在基准评估与对比分析中极具价值,但它们往往无法反映实验条件的复杂性,或药物效应背后错综复杂的分子相互作用。诸如实验类型、实验操作流程、细胞背景以及分子环境等因素,都可能显著影响生物活性测量结果,但在这些标准化数值中很少被考虑或保留。
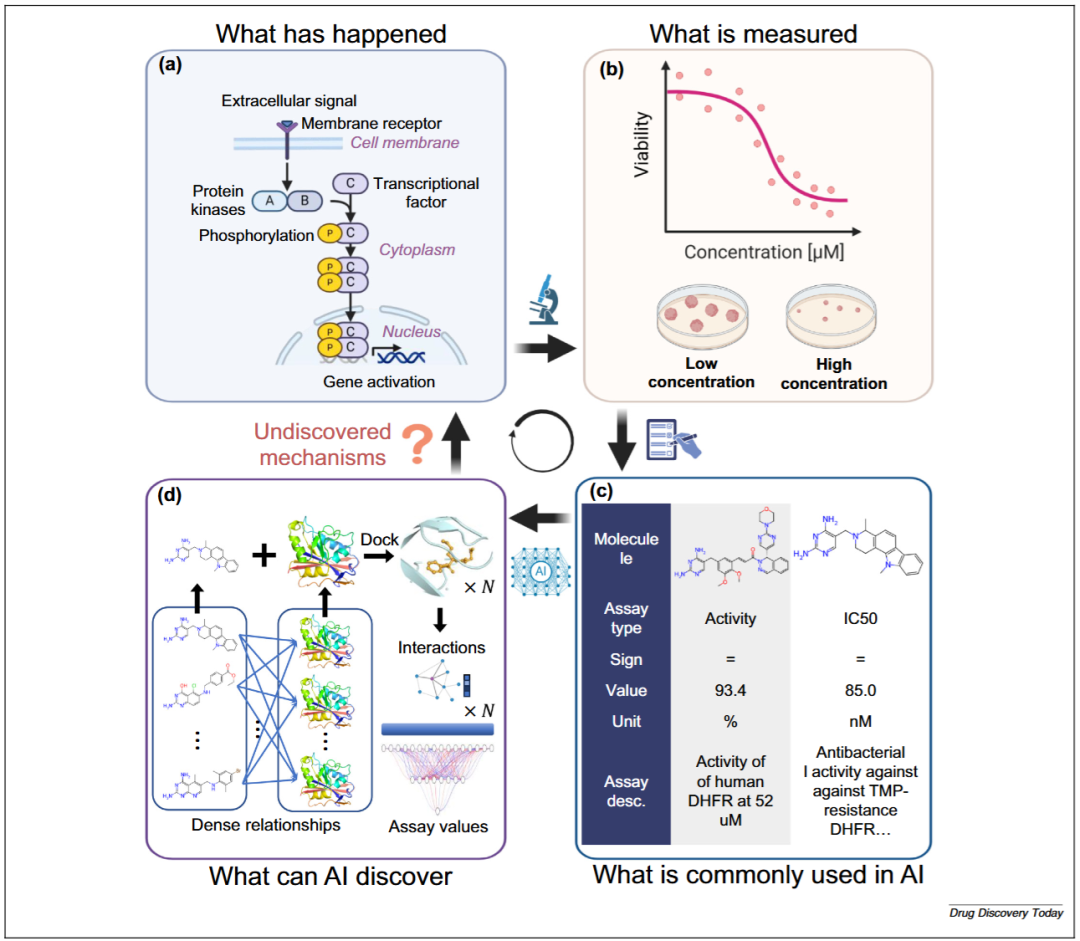
图2 AI在药物发现中的局限性与潜力
要解决这些问题,需要在AI驱动的药物发现流程中,整合详细实验数据、分子相互作用网络与情境化的生物学信息。条件-数值曲线能够捕捉超越单一指标的动态生物活性响应,使AI模型能够学习更细致的分子行为特征。概率预测方法可以量化预测不确定性,更好地应对实验结果的变异性,从而支持更稳健的决策。综合来看,这些方法有助于提高药物发现中AI预测的准确性与可解释性,推动更科学、可信的药物研发流程。
鸿沟3:AI在药物发现中的碎片化应用
研究团队对药物发现流程各阶段的AI应用进行了系统性梳理,涵盖了从靶点发现到临床前研究的最新、综合性与开创性研究(图3),凸显出当前AI方法的碎片化特征。多数模型被设计用于解决单一、独立的任务,而非为整个药物发现流程提供系统化、集成化的解决方案。这种碎片化的问题尤其突出,因为药物发现是一个高度迭代且相互关联的过程,而下游阶段的失败往往未在早期建模阶段得到充分考虑。
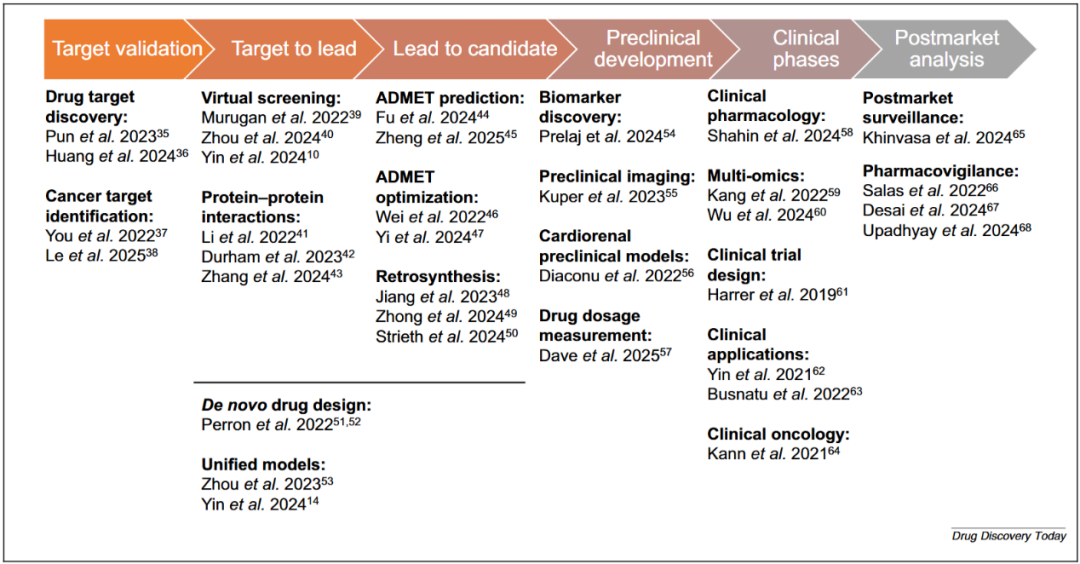
图3 近期AI药物发现研究的关键进展与开创性工作
尽管扩展预测模型有望产生经过实验验证的候选药物,但其成功最终取决于生物学转化。许多候选物在临床前或临床阶段仍以失败告终,原因往往是体内障碍或不可成药靶点被忽视。通过引入生理约束条件,并模拟复杂的生物系统(例如基于生理的药代动力学模型或疾病微环境),有助于提升模型预测结果向真实药效的转化能力。
药物重定位、基础模型以及智能体工作流为克服药物发现中AI应用的碎片化问题提供了潜在途径。其中,药物重定位评估现有药物化合物在新适应症中的潜在用途,AI可以利用既有分子与临床数据,减少对全新分子设计的依赖,同时连接早期与后期预测阶段。不同于任务特定型模型,基础模型在大规模、异质性的生物医学与化学数据集上训练,能够作为多阶段可适配的核心框架,服务于药物发现管线中的多个环节。与此同时,智能体工作流标志着从静态预测向动态决策系统的转变。这类系统能够自主设计、测试并迭代优化分子结构,并通过与预测模型及实验反馈的持续交互,实现分子性能的自适应改进。从理论上讲,这种闭环式工作流程可在靶点发现、化合物生成与实验验证之间建立无缝连接,从而弥合早期设计与后期结果之间的脱节。然而,这些前沿方向的实际效果仍受到多重因素限制,如高质量、多模态训练数据的可获得性不足,可解释性、可重复性以及安全部署仍面临挑战。
迈向整体化的AI药物发现框架
人工智能正在重塑药物发现领域,但其应用仍受限于过度简化的假设与研发流程中的碎片化实施。一个根本性的限制在于当前的简化生物数据处理方法,例如将结合亲和力简单地等同于生物活性,忽视了后者受到复杂生理相互作用的影响。同样地,对单一数值生物活性指标(如EC₅₀)的依赖,也掩盖了那些更丰富、条件依赖的动态信息,这些信息本可显著提升预测精度。
为弥合这些鸿沟,作者提出了一个生物学情境化的AI框架(图4)。框架中的每个组成部分都与具体行动相对应,如整合更丰富、更全面的数据集,设计AI-实验迭代反馈循环,将计算预测结果与生理学背景相对齐。
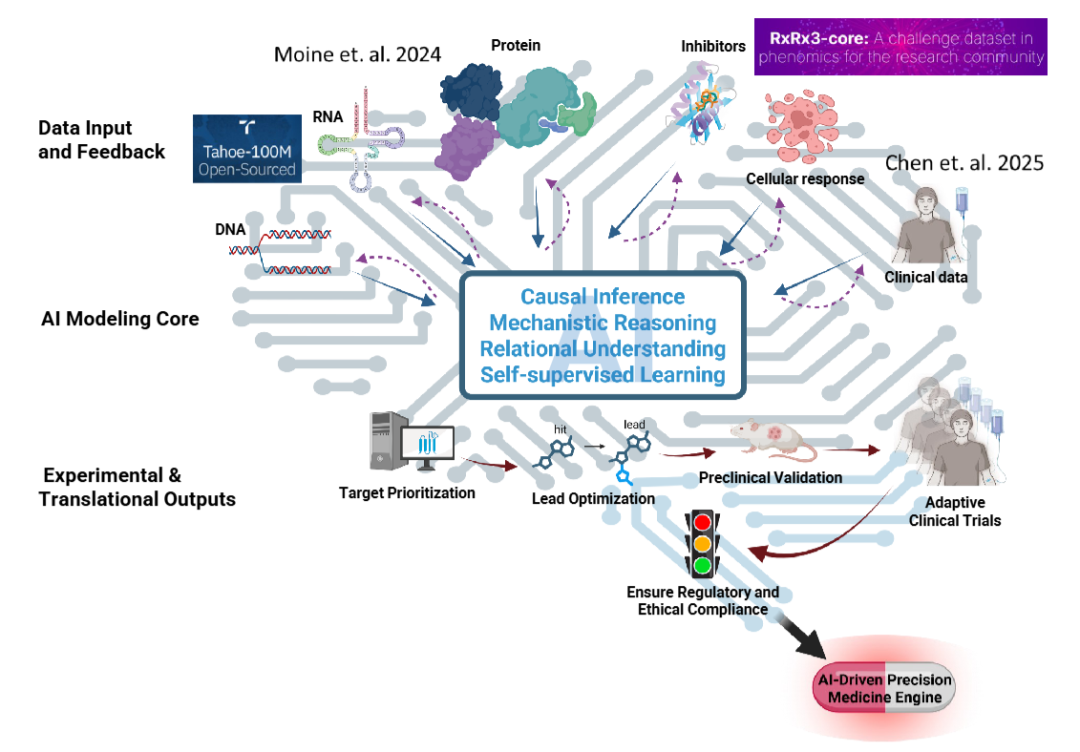
图4 生物学情境化的AI药物发现框架
此外,该框架也揭示了若干技术与政策层面的障碍。尽管预测性结构模型(如AlphaFold)在加速基础与转化研究方面具有巨大潜力,但由于缺乏实验验证,其结果不能被视为真实结构。当前仍存在诸多挑战,例如捕捉蛋白质动态、预测多链复合结构、解释蛋白功能以及评估模型质量。实际的医学数据集通常规模较小、领域特定且数据分布不平衡,这限制了自监督学习方法的有效性。黄金标准基因组数据集往往低估了非欧洲人群的代表性,这不仅导致研究公平性不足,也限制了对人类疾病的全面理解。对于非典型靶点,数据记录普遍稀缺,在时间与资源有限的条件下,研究难以开展。此外,AI的潜在滥用也引发了关于医疗数据共享的担忧。在研究机构与临床单位共享数据用于AI研究之前,必须确保数据安全与患者知情同意得到充分保障。为进一步落实这一整体化愿景,作者为医学生物学与AI药物发现领域的研究者提供了实践指南(表1)。
表1 医学生物学与AI药物发现研究者指南

结语
要弥合医学生物学与AI驱动药物发现之间的鸿沟,需要从假设简化、任务特定算法转向整体化、以生物学为基础的框架。如本文所述,结合亲和力与生物活性的误解、丰富实验数据的未充分利用以及药物发现流程中AI应用的碎片化,共同限制了当前方法的转化潜力。通过整合多尺度生物学知识、实验元数据以及迭代反馈循环,生物学情境化的AI框架能够更好地捕捉生物系统的复杂性,并将预测结果与实际治疗情况对齐。
然而,实现这一愿景仍面临多重障碍,如结构生物学限制(如预测模型验证不足),生物学复杂性(如蛋白质动力学和非经典靶点),数据限制(如小规模、偏倚及不平衡的数据集),伦理问题(如隐私保护与公平获取)。要充分发挥人工智能在药物发现中的潜力,关键在于弥合现有鸿沟与克服多层障碍,并将计算研究与实验验证融合为一个连贯、可适应且具生物学指导性的发现流程。
参考链接:
https://doi.org/10.1016/j.drudis.2025.104512
--------- End ---------
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢