

医学
Medicine

2025年11月26日,中山大学中山眼科中心林浩添教授团队在Cell Press细胞出版社期刊Cell Reports Medicine发表了一篇论文,题为“The effectiveness of large language models in medical AI research for physicians: A randomized controlled trial”。该研究通过严谨的随机对照试验证实,大语言模型可以有效帮助医生完成医学人工智能研究项目,克服知识与技术障碍,同时也可能带来依赖风险等问题。


▲长按图片识别二维码阅读原文
一直以来,多学科的融合与应用在推动学科发展和创新中发挥着关键作用,是推动科学前沿突破的重要驱动力。医学人工智能(AI)作为多学科融合的典范,在提升诊疗水平与医疗效率方面展现出巨大潜力。临床医生宝贵的一线临床经验和深厚的专业洞察力对于医学人工智能的发展不可或缺,然而,技术门槛却构成了他们深入参与的重大障碍。这一矛盾在资源有限的年轻医生或基层医疗机构中尤为突出。尽管此前已有一些旨在降低编程门槛的工具,但要独立完成一个完整的、从设计到执行的医学AI研究项目,对非工程背景的临床医生而言依然充满挑战。目前,尚缺乏一种能够灵活应用于整个医学AI研究流程、有效降低综合技术难度的策略与方法。
近年来,大语言模型的出现,为破解这一困境带来了新的希望。其强大的通用知识问答与代码生成能力,是否真能成为临床医生开展AI研究的“助手”?其效果究竟如何?又会带来哪些潜在风险?这些问题亟需严谨的科学证据予以回答。
近日,中山大学中山眼科中心林浩添教授团队开展了一项优效性、开放标签的随机对照试验,评估LLMs能否作为一种有效工具协助医生开展医学AI研究。研究入组了64例无AI研究和编程经验的参与者,随机分为使用LLMs的干预组(n=32)与使用传统搜索工具的对照组(n=32),参与者被要求在两周内完成一项医学AI研究项目。结果显示,干预组的项目总完成率高达87.5%,远超对照组的25.0%(差值62.5%,p=9.42e-7)。更值得注意的是,干预组在无需专家小组任何协助的情况下独立完成项目的比例达到68.7%,而对照组仅为3.1%(差值65.6%,p=5.70e-8)。此外,干预组在项目方案质量与项目完成速度方面均表现更优(p<0.01)。
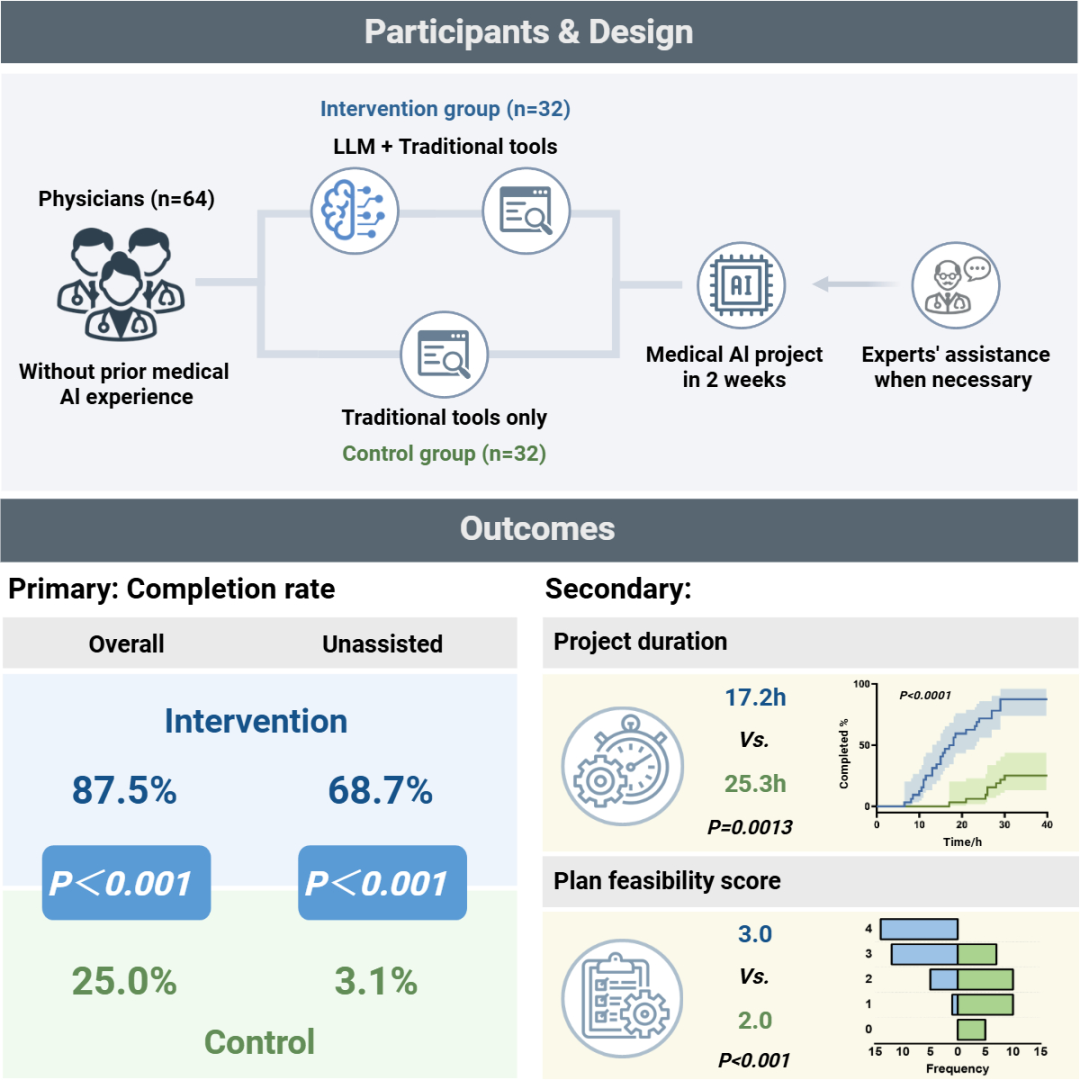
更重要的是,在为期两周的“洗脱期”后停止使用大语言模型,仍有41.2%原干预组的成功参与者能够独立完成一个新的研究项目,这表明他们不仅仅是机械复制LLMs的答案,而是在LLMs帮助下掌握了医学AI研究的基本原理和开展流程,并能够将习得的知识和技能应用于新的AI研究项目。然而,仍有超40%的成功参与者在撤除LLMs后未能完成新项目,表明参与者对LLMs可能有依赖倾向。进一步问卷调查显示,42.6% 的参与者担心使用LLMs可能导致“只是机械复制而缺乏理解”,40.4%的参与者忧虑其可能“助长惰性思维”,提示对LLMs依赖的潜在风险。该研究证实了大语言模型在赋能临床医生进行医学AI研究方面的巨大潜力,同时也提示其长期风险需进一步评估。
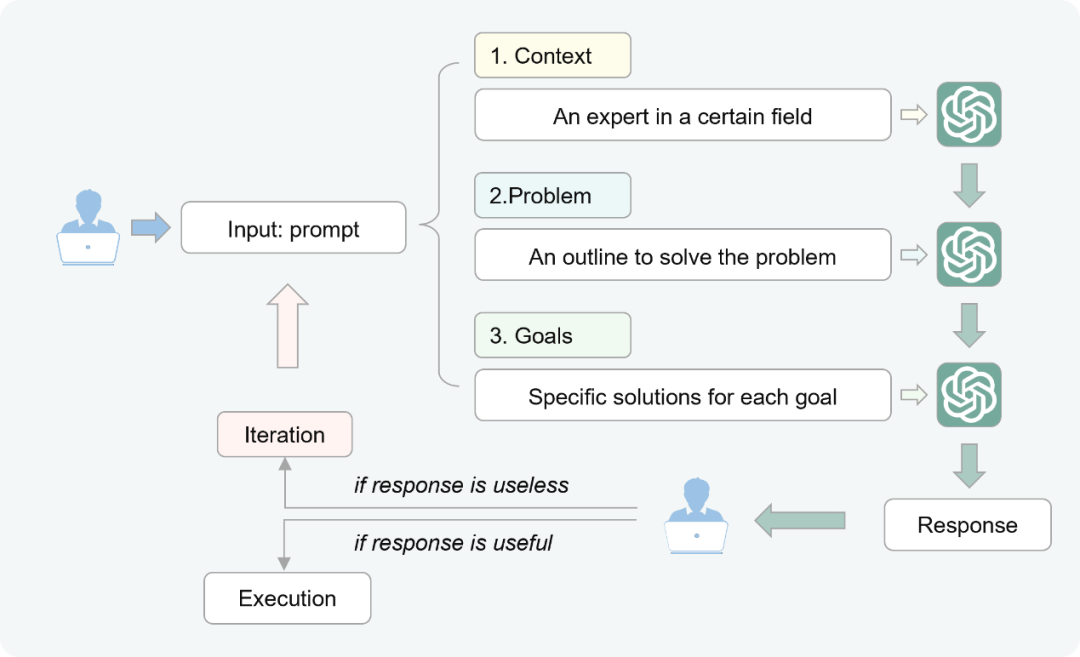
此外,研究人员进一步分析指出,未能完成项目的参与者与LLMs的对话记录中出现了“AI幻觉”及使用“无效提示词”的问题,因此研究人员采用类德尔菲法总结出一套“CPGI”提示词指南帮助医生使用LLMs开展医学AI研究时能够制定有效的提示词。

作者专访
Cell Press细胞出版社特别邀请论文作者团队进行了专访,为大家进一步详细解读。






相关论文信息
相关论文刊载于Cell Press细胞出版社旗下期刊Cell Reports Medicine上,点击“阅读原文”或扫描下方二维码查看论文

▌论文标题:
The effectiveness of large language models in medical AI research for physicians: A randomized controlled trial
▌论文网址:
https://www.sciencedirect.com/science/article/pii/S2666379125005427
▌DOI:
https://doi.org/10.1016/j.xcrm.2025.102469

▲长按图片识别二维码阅读原文
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢