报告主题:DARLING|强化学习如何打破同质化
报告日期:12月04日(周四)10:30-11:30
本期报告将由约翰霍普金斯大学李天健进行分享。
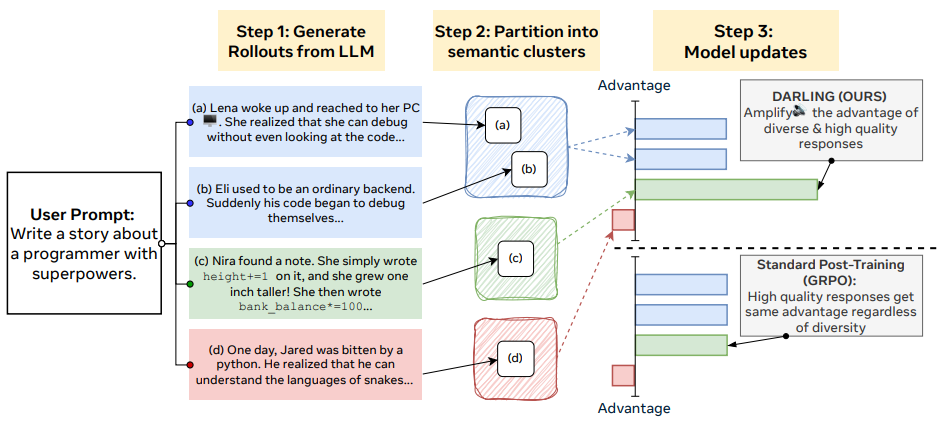
随着大语言模型能力不断提升,一个日益突出的现象是:模型的回答往往高度一致、内容相似、缺乏多样性。尤其在后训练阶段,由于强化模型的“正确性”与“有用性”,模型的输出分布会进一步被压缩,使得生成内容更趋同质化。这种模式在创意写作、头脑风暴、开放式推理等任务中尤其明显,限制了模型的创造力与探索能力。为缓解这一问题,我们提出 DARLING(Diversity-Aware Reinforcement Learning)框架,旨在解决“高质量”与“高多样性”之间的长期矛盾。DARLING 的核心思想是:强化学习需要显式、稳定地优化语义层面的多样性信号。因此,我们设计了一个可学习的语义分区函数,能够在深层语义空间中对生成内容进行划分,从而捕捉真正意义上的多样化表达。该信号与质量奖励在在线强化学习过程中联合优化,使模型生成的回答 既高质量又彼此不同。实验结果表明,DARLING 在两类任务上均展现出显著优势:非可验证任务(如创意写作、指令执行):在五项基准任务中同时提升输出的质量与新颖性。可验证任务(如竞赛数学):提高 pass@1(答案质量)与 pass@k(方法多样性),展现出更强的探索能力。显式优化语义多样性会激发强化学习的探索行为,最终反而带来更高的质量。本报告将从动机、方法、实验与启示四个方面系统介绍 DARLING,并探讨其对未来大模型训练范式的影响。论文截图
李天健,美国约翰霍普金斯大学博士生,导师为 Daniel Khashabi。目前在 Meta FAIR 实习。他的研究方向主要包括大模型后训练与强化学习,特别关注评估与提升数据多样性。扫码报名
更多热门报告


内容中包含的图片若涉及版权问题,请及时与我们联系删除




评论
沙发等你来抢