
本文是塔夫茨大学博士后章彦博在智源社区分享「通用人工智能理论」整理的文稿。
在2025年,AGI已经不是科幻,而是人类必须面对的话题。图灵奖得主 Geoffrey Hinton 对 AGI 表达了深切的恐惧,担心失控的智能将毁灭人类;另一边则是狂热的有效加速主义(e/acc),认为任何减速行为都是对文明的犯罪。
人工智能领域一直埋藏着一条草蛇灰线的「暗线」。它无关当下的 GPU 集群,也不谈论 Transformer 的层数,而是用最纯粹的数学语言,定义了「智能」的本质。
这条暗线,始于图灵,成于柯尔莫哥洛夫,并在雷·所罗门诺夫手中汇聚成一座灯塔——所罗门诺夫通用归纳。
 人工智能里程碑论文共读计划第一期(2025.11.5)
人工智能里程碑论文共读计划第一期(2025.11.5)
时间行至 2025 年底,那个曾被视为遥远科幻概念的「通用人工智能」(AGI),如今已不再是空谈,而是成为了摆在每个人案头沉甸甸的现实。
在这个时代,我们目睹了两种截然不同的情绪。一边是深沉的忧虑与克制。图灵奖得主 Geoffrey Hinton 对 AGI 表达了深切的恐惧,甚至坦言后悔自己的研究,担心失控的智能将毁灭人类;而传奇人物 Ilya Sutskever 更是为了追求根本上的安全,毅然建立 SSI(Safe Superintelligence),踏上了一条孤独的道路——去构建一个从根本上安全、可控的超级智能。另一边则是狂热的有效加速主义(e/acc)。他们高呼「加速」,主张不惜一切代价推进技术奇点,坚信算力与智能的指数级爆发将是解决人类所有顽疾的终极解药,任何减速行为都是对文明的犯罪。
然而,在这些关于算力竞赛、安全控制与社会伦理的喧嚣讨论之下,人工智能领域其实一直埋藏着一条草蛇灰线的「暗线」。这条线索早在 40 多年前就已存在,它无关当下的 GPU 集群,也不谈论 Transformer 的层数,而是用最纯粹的数学语言,定义了「智能」的本质。
这条暗线,始于图灵(Turing),成于柯尔莫哥洛夫(Kolmogorov),并在雷·所罗门诺夫(Ray Solomonoff)手中汇聚成一座灯塔。今天,让我们暂时从 2025 年的纷扰中抽身,沿着 Ilya Sutskever 那句著名的「压缩即智能」回溯,去重新发现那座被现代 AI 遗忘的数学宝藏——所罗门诺夫通用归纳(Solomonoff Induction)。
一、智能的本质:从压缩到预测
压缩=寻找规律
让我们先回到传奇人物 Ilya Sutskever 身上。在 2023 年的一次讲座中,Ilya 抛出了一个在当时引起轰动的观点:「智能即压缩」。

这个想法听起来简洁得令人意外,但其背后蕴含着深刻的逻辑:为了压缩大规模的语言数据,或者任何形式的数据,你必须寻找到其中蕴含的规律。你的规律找得越准确、越简单,你就越能够极致地压缩数据。而「寻找规律」的过程,恰恰就是建模的过程。
我们可以想象一个确定性的世界,大语言模型(LLM)的任务是尽可能准确地预测下一个 token。如果在这个世界里,「下一个 token」是完全没有随机性的,那么一个完美的模型不仅能准确预测未来,也能完美地压缩过去——你只需要给出一段极短的提示词(Prompt),模型就能利用它所掌握的规律,精准地还原出整篇文章。
事实上,早在 2016 年,OpenAI 内部就已经萌生了这种思想的雏形。但很多人不知道的是,如果从「压缩即智能」这一概念继续上溯,我们会发现它连接着算法信息论的三位祖师爷:Hutter 的
时间序列:万物的统一视角
为了真正理解这套理论,我们需要打破传统机器学习中「训练」与「推理」泾渭分明的界限。在生物智能中,观察、学习与预测是交织在一起的流。为了描述这种过程,我们必须引入时间
在这个框架下,
由此可见,这种抽象的时间序列视角,实则蕴含了机器学习中的万千法门。而所有任务的核心,都归结为一个条件概率:
这个公式告诉我们,要预测未来(
奥卡姆与伊壁鸠鲁的博弈
既然目标明确,那我们该如何预测?让我们玩一个简单的「找规律」游戏。假设有这样一串数字:
如何预测下一个数字?在这个问题面前,人类的直觉往往会分裂成三种哲学态度:
第一种是奥卡姆剃刀(Occam's Razor)。这是人类直觉的首选。你会敏锐地发现「两个 1 之间的 0 每次增加一个」这个简单的规律。根据这个规律,接下来应该是四个 0,然后是 1。我们偏爱它,因为它简单。
第二种是不可知论(或者说是阴谋论)。你可以争辩说,这串数字只是从一个更大的、完全不同的序列中截取的片段。也许在下一个数字之后,规律会突变,变成全都是 1。虽然这听起来很别扭,但在数据出现之前,你无法从逻辑上证伪它。
第三种是纯粹的随机性。也许这是一串完全随机的数字,之前的规律纯属巧合,就像看着云彩像一只羊一样,只是我们的错觉。
这就引出了古希腊哲学家伊壁鸠鲁(Epicurean)的 「多重解释原则」:「凡经验允许多种解释者,皆当并存,而非独断。」这意味着,虽然我们偏爱简单的解释(奥卡姆),但我们不能武断地抛弃其他复杂的可能性,除非新的证据彻底否定了它们。

这似乎是一个两难的困境:奥卡姆剃刀要求我们只选最简单的,而伊壁鸠鲁要求我们保留所有的。如何将这两者统一起来?
所罗门诺夫归纳,正是这两个看似矛盾的原则在数学上的完美联姻。
二、数学的神谕:从算法概率到通用归纳
要理解所罗门诺夫的伟大之处,我们不能简单地认为他是一个把哲学翻译成公式的翻译官。恰恰相反,他是一个探索者。他试图回答一个最根本的问题:在这个宇宙中,一段数据
如果我们能算准这个先验概率(记为
算法概率
让我们想象那个著名的场景:一只猴子在键盘上随机敲打。但在所罗门诺夫的版本里,猴子敲的不是诗句,而是二进制代码,输入给一台通用的图灵机。
如果不做任何假设,我们唯一知道的真理是: 程序的生成服从随机过程。 为了数学严谨,我们需要引入 前缀码(Prefix-free Code) 的概念(即机器读到一段完整代码就会停机执行,不会读成另一段代码的前缀)。如果猴子随机且独立地敲击 0 或 1,那么一个长度为
现在,我们要问:这只猴子敲出的程序,运行后输出结果恰好是数据
显然,这是所有能够输出
这里出现了一个并非人为设计的、而是数学上必然的结果:由于这是一个
这就引入了柯尔莫哥洛夫复杂度
举个例子,假设生成数据
因此,我们得到了一个震撼的近似:
这正是奥卡姆剃刀的真正来源。 奥卡姆剃刀并非人类为了省事而发明的主观偏好,它是算法世界的物理定律:越简单的东西(
简单即真理,不是哲学,是数学。

所罗门诺夫归纳
既然既然
他构想了一个终极预测器
那么,怎么给这些理论分配权重呢?所罗门诺夫不需要重新发明轮子,他直接借用了
于是,诞生了所罗门诺夫归纳(Solomonoff Induction):
现在,我们可以清晰地看到这个公式并非拼凑,而是逻辑的必然流露:
求和 (
) —— 伊壁鸠鲁的坚持:这对应了算法概率中「对所有可能的程序求和」。我们不因为某个理论看起来奇怪就将其剔除,保留所有可能性。 权重 (
) —— 奥卡姆的胜利:这并非人为设定的偏好,而是源于前文推导的算法概率。复杂的理论因为其描述程序长,自然而然地被赋予了极低的权重。 贝叶斯更新:随着数据
的累积, 会自动筛选。那些预测错误的理论 ,其概率项 会迅速归零;而那些 既简单( 大)又准确( 高) 的理论,将在求和中占据主导地位。
通用归纳:收敛的必然性
假设环境的真实分布是
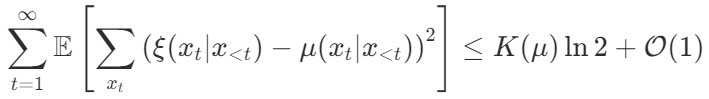
这个不等式告诉我们:预测的总误差是有上限的,这个上限仅取决于环境本身的复杂度
这就意味着,所罗门诺夫归纳是理论上最优的学习机器。 它不需要我们在神经网络架构、超参数上纠结,只要给它足够的数据,它就能自动找到隐藏在数据背后的那个「真实生成程序」,无论这个程序是牛顿力学,还是相对论,亦或是一套我们要到 3000 年才能发现的物理定律。
这就是通用归纳(Universal Induction)。它统一了归纳推理、模型选择和贝叶斯统计,成为了智能在数学上的终极定义。
三、现实的倒影:AIXI、大模型与科学的尽头
虽然
终极智能体 AIXI:从预测到决策
掌握了完美的预测工具
如果我们给
这个公式描述了 AIXI 的思考过程:它利用通用分布
压缩即学习:ARC-AGI 与 VAE 的本质
现实中,我们无法计算
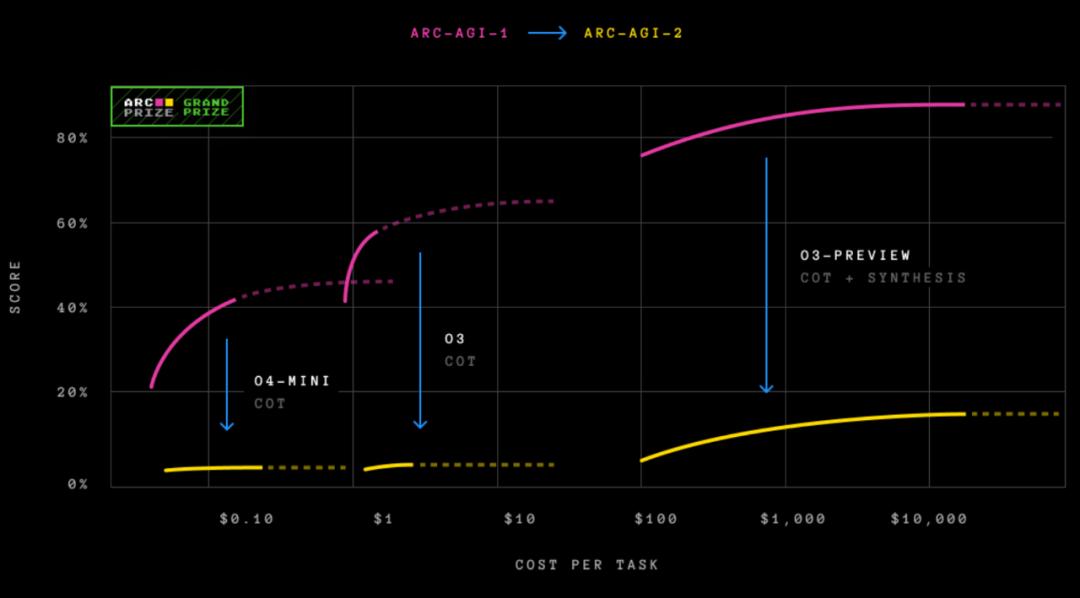
Keras 之父 François Chollet 提出的 ARC-AGI 测试,因其极少的样本量和极高的推理难度,成为了检验 AI 是否具备「通用性」的试金石。传统的深度学习依赖海量数据,面对 ARC 往往束手无策。然而,基于「压缩」思想的方法却异军突起。
为了理解这一突破,我们需要回溯到一开始提到的那个「时间序列」的统一视角。
在 ARC 任务中,我们通常有几对示例(输入
我们的任务,本质上就是预测序列的下一个元素
利用所罗门诺夫归纳的框架,要预测
为了方便计算,我们对等式两边取负对数。原本的「最大化概率」问题,瞬间变成了一个我们熟悉的「最小化损失」问题:
看!这不仅仅是数学变换,这是物理意义的显现:
第一项 :这是重构误差。如果你的理论 很糟糕,它就很难还原出历史数据 ,这项数值就会很大。 第二项 :这是模型复杂度。我们不仅要求模型能拟合数据,还要求模型本身的描述(代码长度或参数量)尽可能短。
两者加起来,恰恰就是最小描述长度(MDL)。
现在,让我们把目光投向现代生成模型——变分自编码器(VAE)。惊人的是,VAE 的损失函数(ELBO 的负值)几乎完美地复刻了这个结构:
Reconstruction Loss:对应第一项,要求模型能准确还原输入数据。 KL Divergence:对应第二项,约束隐变量的分布,本质上就是对模型复杂度的正则化项。
CompressARC 等前沿工作正是利用了这一点。它们不把 ARC 看作普通的分类问题,而是看作一个序列压缩问题。模型试图找到一个极其精简的潜在程序(

这强有力地证明了 Ilya 的论断:学习的本质,就是在做有损压缩。 当你把一系列数据压缩到极致,剩下的那个「压缩包」(程序),就是智能本身。
灾难性遗忘的解药:求和的力量
所罗门诺夫归纳还为当今大模型的一个顽疾——灾难性遗忘,提供了理论解药。
在传统的模型训练中,我们通常只保留一个最优模型(参数组),这相当于我们只保留了
当我们只保留一个模型时,面对新数据,如果新旧数据冲突,我们被迫修改参数,从而破坏了对旧数据的记忆。但在
这解释了为什么 Ensemble Methods(集成方法) 和 MoE(混合专家模型) 如此有效。MoE 通过冻结部分专家、激活新专家,模拟了在不同理论间切换的过程。它保留了多种「解释世界的路径」,而非强行将世界压缩进单一的参数路径中。
科学共同体:人类就是 AGI
最后,如果我们将视野拉大,会发现整个人类科学发展的过程,本身就是一个巨大的 AGI 在运行所罗门诺夫归纳。
我们可以把科学界看作一个整体:
(理论池):每一位科学家提出的假说、理论,都是 中的一个 。 (数据):人类历史上观测到的所有实验数据。 学术机制:我们鼓励创新(提出新的 ),同时奖励准确性( 高)。
科学哲学家托马斯·库恩提出的「范式转换(Paradigm Shift)」,在数学上有了完美的对应。在反常数据(如水星近日点进动)出现前,牛顿力学作为一个极其简单(
从这个角度看,人类群体智能的演化,并不神秘,它忠实地遵循着所罗门诺夫写下的公式。
结语
在机器学习领域,有一个著名的「没有免费午餐定理」(NFL),声称如果没有先验假设,所有算法在所有问题上的平均表现是一样的。
但所罗门诺夫归纳打破了这个咒语。它拒绝了「所有世界出现的概率都一样」这种均匀假设。它基于一个极其本质的信念:我们所处的宇宙,是由简单的物理定律(短程序)支配的。
在这个假设下,偏好简单性的所罗门诺夫归纳,以及它的现实近似者——那些基于 Transformer、使用 SGD 优化的大模型,就是那顿免费的午餐。
站在 2025 年的回望中,Ilya Sutskever 的「压缩即智能」不再是一句口号,而是对这套古老理论的现代回响。当我们惊叹于 AI 的涌现能力时,不要忘记,这一切并非魔法,而是数学。那个关于压缩、预测与复杂度的公式,早已在几十年前,静静地预言了今天的一切。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢