

DeepSeek 又更新了,依旧是迭代了一年的 V3 系列,但这次给出的是 V3.2 正式版。
9 月底,DeepSeek 推出了实验性模型 DeepSeek-V3.2-Exp,在 V3.1-Terminus 的基础上,引入了 DeepSeek Sparse Attention(DSA) 技术,大幅提升了长文本处理的效率。
今天,发布的两个正式版模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale,重点在推理、以及 Agent 能力的提升。
DeepSeek-V3.2-Speciale 作为开源模型,在 IMO 2025、CMO 2025 等主流推理基准测试上的性能表现媲美 Gemini-3.0-Pro。
有意思的是,Deepseek 在前几天刚刚发布了一个数学模型 DeepSeek-Math-V2,正是基于 DeepSeek-V3.2-Exp-Base 开发。这个数学模型实现了 IMO 金牌级的水平。
同时,这次 V3.2 正式版发布最值得一提的是,把思考过程融入到了工具调用中,模型能够同时支持思考模式和非思考模式的工具调用。在各类智能体工具调用评测集上,DeepSeek-V3.2 达到了目前开源模型的最高水平。DeepSeek 官方称,模型未针对测试集进行特殊训练,在真实场景中显示出了较强的泛化能力。
目前,正式版 DeepSeek-V3.2 已在网页端、App 和 API 上线。Speciale 版本以临时 API 形式开放。API 支持 DeepSeek-V3.2 思考模式下的工具调用能力。
技术报告:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2/resolve/master/assets/paper.pdf
⬆️关注 Founder Park,最及时最干货的创业分享
超 17000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。

最新、最值得关注的 AI 新品资讯;
不定期赠送热门新品的邀请码、会员码;
最精准的AI产品曝光渠道
01
V3 版本迭代了一年,
V4 还是没来去年 12 月 25 日发布的 DeepSeek V3,今年 1 月 20 日发布的 DeepSeek R1,R1 也正式引爆了这一年的 DeepSeek 和国内开源模型的热潮,Kimi、MiniMax 等也相继开源,并且取得了不错的成绩。
不过梳理了 DeepSeek2025 年的发布可以发现,今年一直在走小版本迭代和功能累加的路线。核心增强的点是:
MoE 本身架构的一些改进,包括强化、DSA 等。
Agent 工具使用能力的强化,从 V3.1 开始对工具使用能力的强化,到 3.2 增加思考模式下的工具使用能力,而且有了更泛化的工具使用能力。
思考/非思考模型的统一,V3.1 就统一了 R1 和 V3,成为了一个混合推理模型,这也是当下闭源模型的大势所趋,Gemini、Claude 和 GPT-5 都是这样。
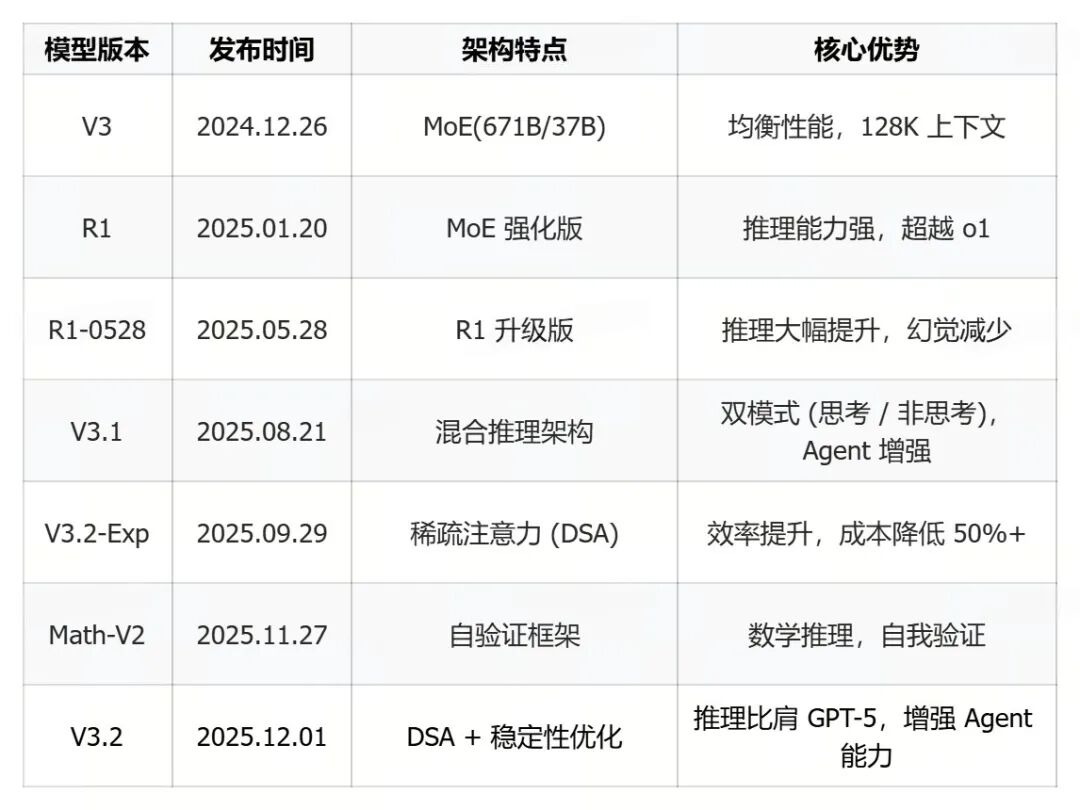
DeepSeek 2025 年的发布梳理
和 V3.1-Exp 版本类似,这次也发布了一个测试版本:DeepSeek-V3.2-Speciale,DeepSeek-V3.2 的长思考增强版,同时结合了 DeepSeek-Math-V2 的定理证明能力,试图将开源模型的能力推到极致的版本,也许在这个测试之后,可能 V3.3(如果有的话)也会持续在这个版本上迭代。
从年终就开始谣传的 DeepSeek V4 或者 R2 即将发布,到现在,我们也没看到 DeepSeek 基模的大版本发布。如果 Agent 的工具能力继续在 V3 版本进行增强,对于明年要发布的大版本(应该会在明年吧),感觉可以期待的东西似乎更多了,比如多模态?更长的上下文?更厉害的 Agent 能力?
很期待 DeepSeek 下一个版本,我们能见到 V4。
02
正式版 DeepSeek-V3.2:
推理能力达到 GPT-5 水平
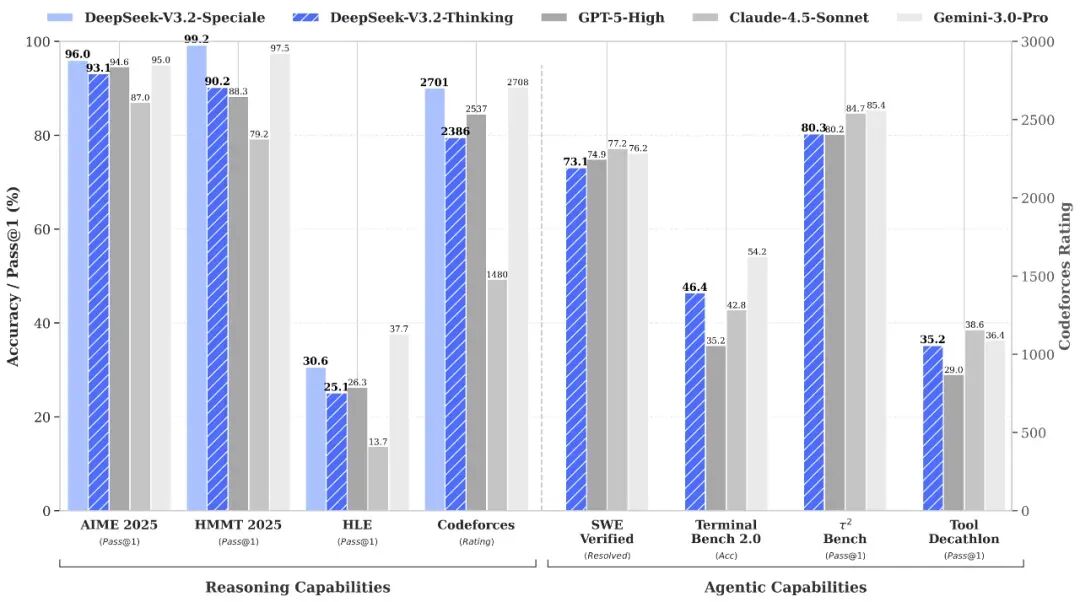
DeepSeek-V3.2 的目标是平衡推理能力与输出长度,适合日常使用,例如问答场景和通用 Agent 任务场景。
在公开的推理类 Benchmark 测试中,DeepSeek-V3.2 达到了 GPT-5 的水平,仅略低于 Gemini-3.0-Pro;相比 Kimi-K2-Thinking,V3.2 的输出长度大幅降低,显著减少了计算开销与用户等待时间。
DeepSeek-V3.2-Speciale 的目标则是将开源模型的推理能力推向极致。它是 V3.2 的长思考增强版,并结合了 DeepSeek-Math-V2 的定理证明能力。
Speciale 版本模型在主流推理基准上的表现与 Gemini-3.0-Pro 不相上下。同时,在多项顶级学术竞赛中达到金牌水平,包括 IMO 2025(国际数学奥林匹克)、ICPC 2025(国际大学生程序设计竞赛)等,其中 ICPC 和 IOI 的成绩分别达到了人类选手第二名和第十名的水平。
但 Speciale 版本 是针对高度复杂任务优化,消耗的 Token 更多、且成本更高,目前仅供研究使用,不支持工具调用,未针对日常对话优化。
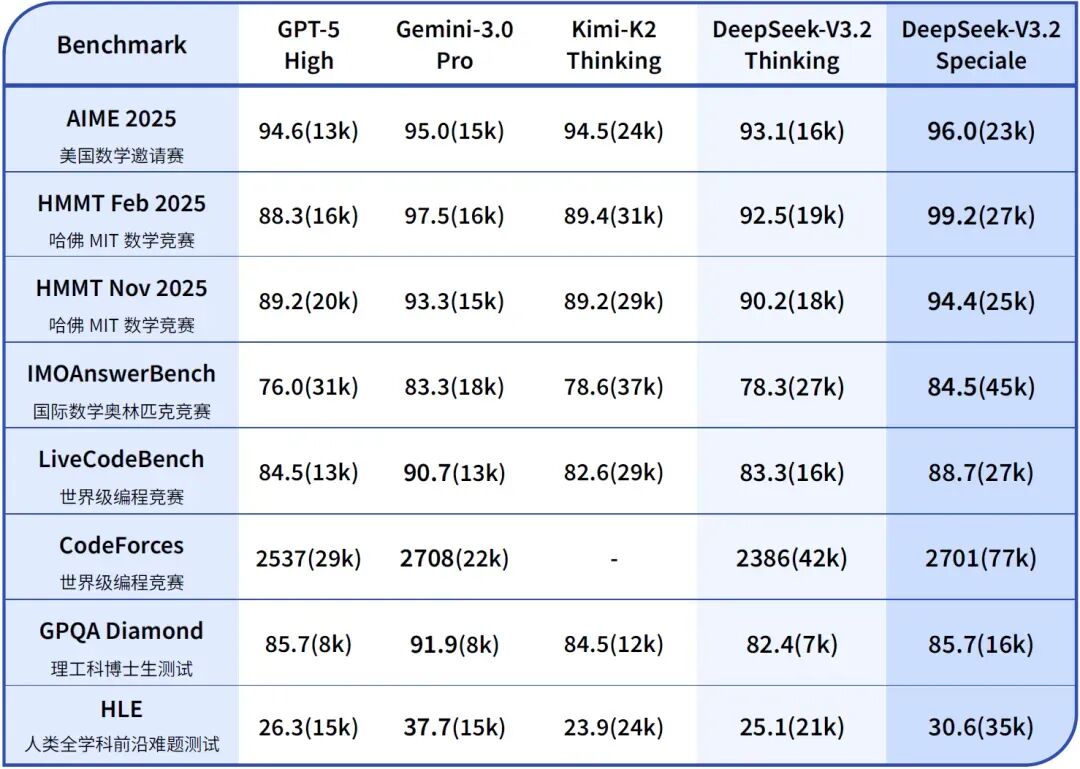
DeepSeek-V3.2 与其他模型在各类数学、代码与通用领域评测集上的得分(括号内为消耗 Tokens 总量约数)
03
工具调用也能 thinking 了
本次更新的一个核心突破是将思考过程融入工具调用。DeepSeek-V3.2 同时支持思考模式与非思考模式的工具调用。
DeepSeek 提出了一种大规模 Agent 训练数据合成方法,构建了大量「难解答,易验证」的任务,显著提升了模型的泛化能力。
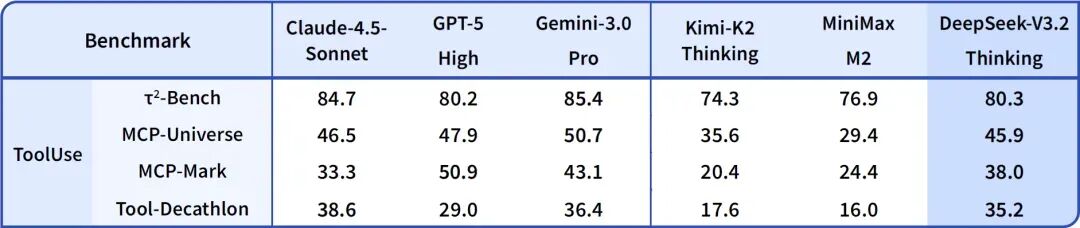
DeepSeek-V3.2 与其他模型在各类智能体工具调用评测集上的得分
在各类智能体工具调用评测集上,DeepSeek-V3.2 达到了当前开源模型的最高水平,大幅缩小了与闭源模型之间的差距。但模型并未针对测试集进行特殊训练,在真实场景中具有较强的泛化性。
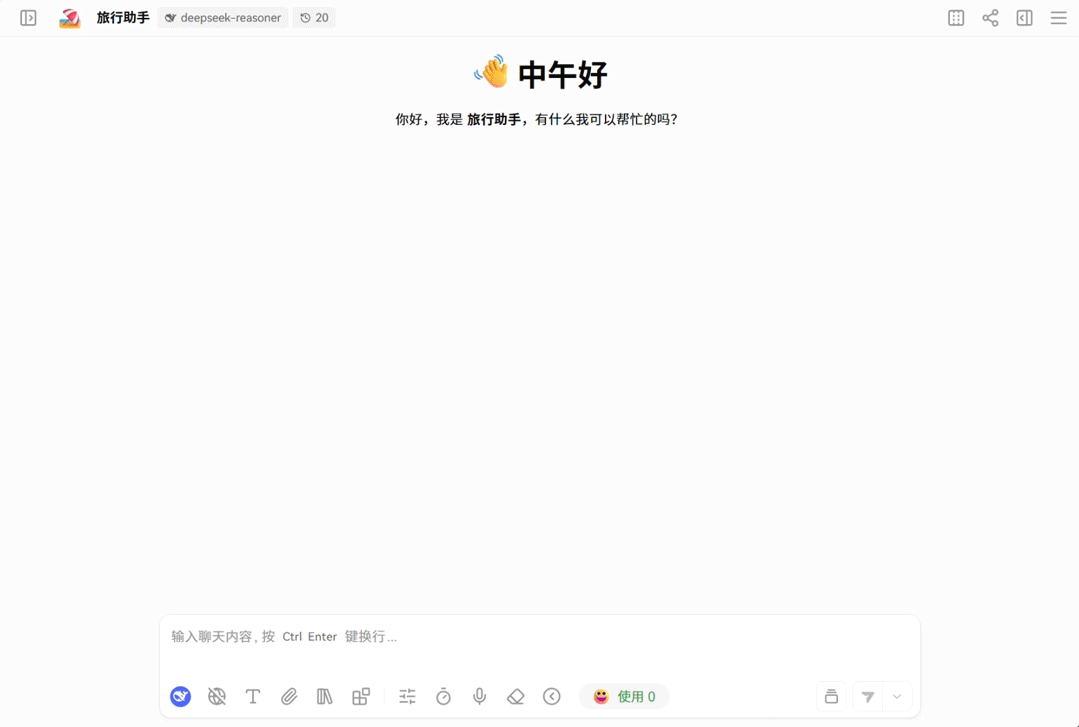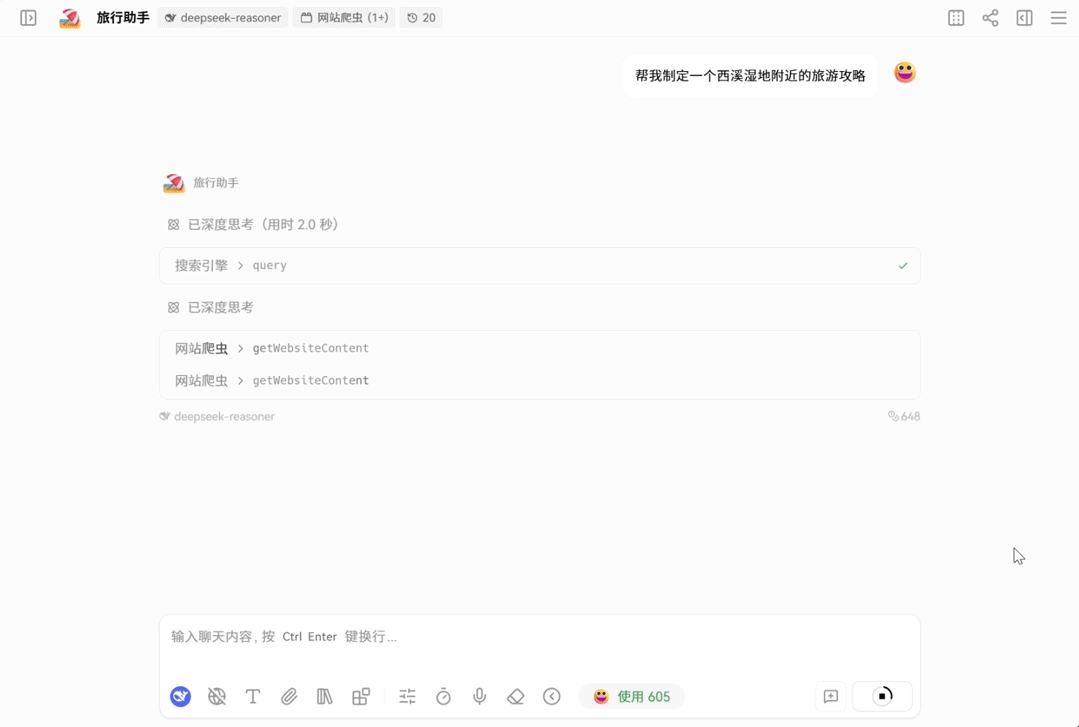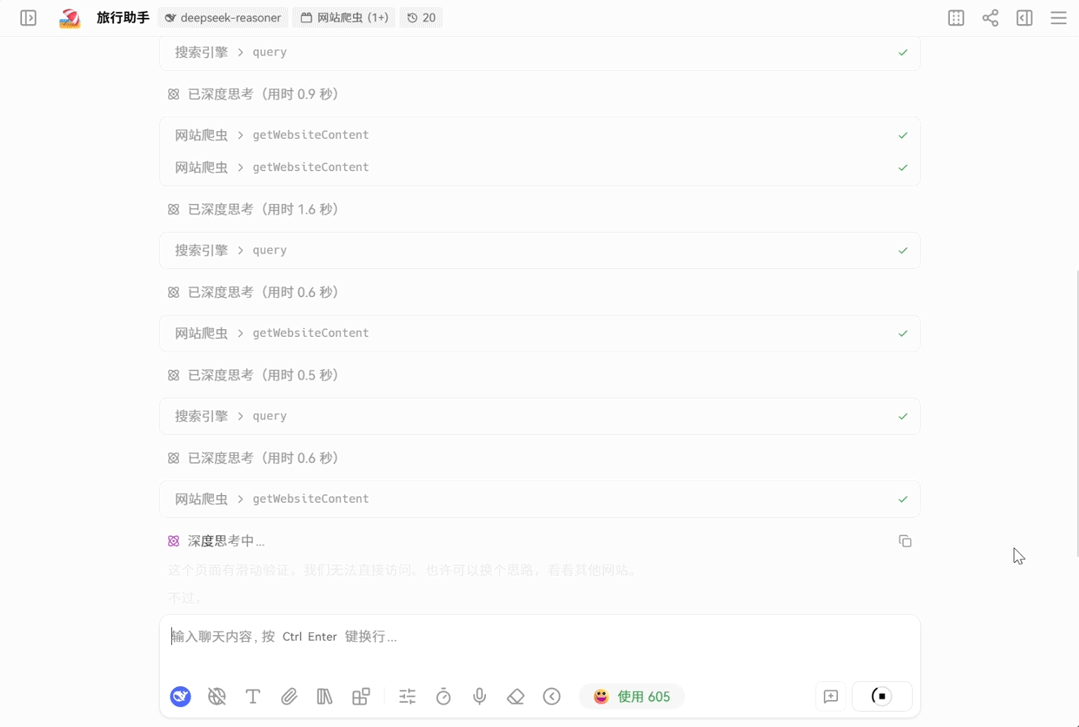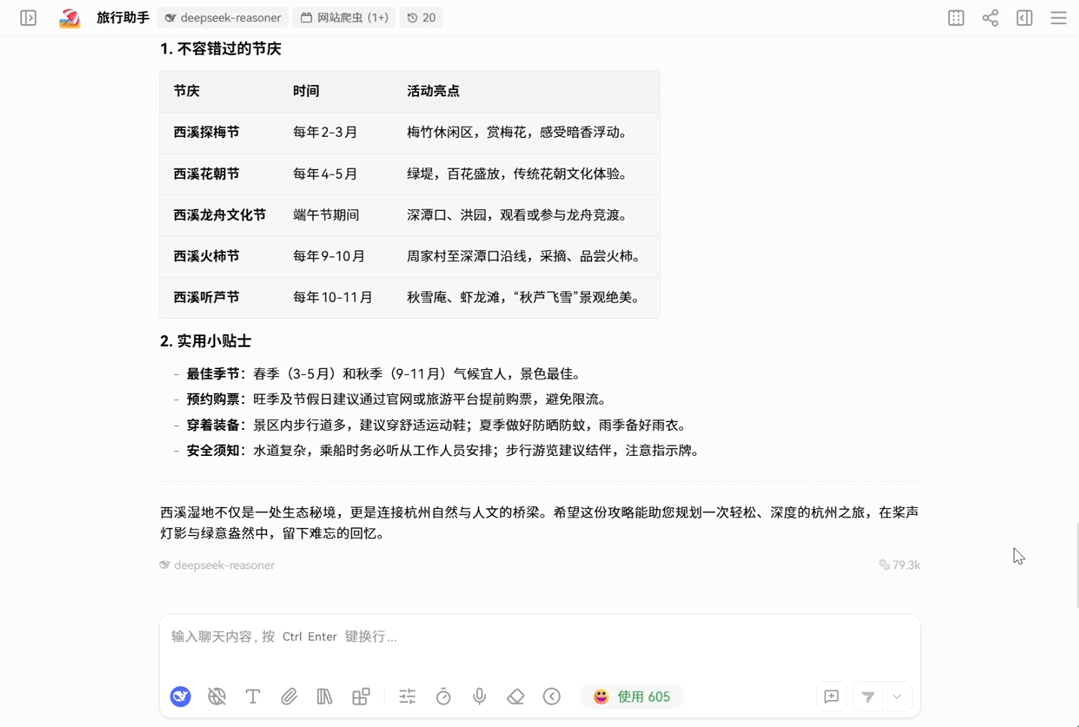
示例:通过 LobeChat 使用 DeepSeek-V3.2 的深度思考+工具调用能力得到更加详细准确的回复


更多阅读 AI 顶尖科学家、前 OpenAI 联创 Ilya Sutskever 的 18 个最新思考
Vibe Coding 产品最大的错觉,是以为自己真的有护城河
去年 12 月 25 日发布的 DeepSeek V3,今年 1 月 20 日发布的 DeepSeek R1,R1 也正式引爆了这一年的 DeepSeek 和国内开源模型的热潮,Kimi、MiniMax 等也相继开源,并且取得了不错的成绩。
不过梳理了 DeepSeek2025 年的发布可以发现,今年一直在走小版本迭代和功能累加的路线。核心增强的点是:
MoE 本身架构的一些改进,包括强化、DSA 等。
Agent 工具使用能力的强化,从 V3.1 开始对工具使用能力的强化,到 3.2 增加思考模式下的工具使用能力,而且有了更泛化的工具使用能力。
思考/非思考模型的统一,V3.1 就统一了 R1 和 V3,成为了一个混合推理模型,这也是当下闭源模型的大势所趋,Gemini、Claude 和 GPT-5 都是这样。
DeepSeek 2025 年的发布梳理
和 V3.1-Exp 版本类似,这次也发布了一个测试版本:DeepSeek-V3.2-Speciale,DeepSeek-V3.2 的长思考增强版,同时结合了 DeepSeek-Math-V2 的定理证明能力,试图将开源模型的能力推到极致的版本,也许在这个测试之后,可能 V3.3(如果有的话)也会持续在这个版本上迭代。
从年终就开始谣传的 DeepSeek V4 或者 R2 即将发布,到现在,我们也没看到 DeepSeek 基模的大版本发布。如果 Agent 的工具能力继续在 V3 版本进行增强,对于明年要发布的大版本(应该会在明年吧),感觉可以期待的东西似乎更多了,比如多模态?更长的上下文?更厉害的 Agent 能力?
很期待 DeepSeek 下一个版本,我们能见到 V4。
02
正式版 DeepSeek-V3.2:
推理能力达到 GPT-5 水平
DeepSeek-V3.2 的目标是平衡推理能力与输出长度,适合日常使用,例如问答场景和通用 Agent 任务场景。
在公开的推理类 Benchmark 测试中,DeepSeek-V3.2 达到了 GPT-5 的水平,仅略低于 Gemini-3.0-Pro;相比 Kimi-K2-Thinking,V3.2 的输出长度大幅降低,显著减少了计算开销与用户等待时间。
DeepSeek-V3.2-Speciale 的目标则是将开源模型的推理能力推向极致。它是 V3.2 的长思考增强版,并结合了 DeepSeek-Math-V2 的定理证明能力。
Speciale 版本模型在主流推理基准上的表现与 Gemini-3.0-Pro 不相上下。同时,在多项顶级学术竞赛中达到金牌水平,包括 IMO 2025(国际数学奥林匹克)、ICPC 2025(国际大学生程序设计竞赛)等,其中 ICPC 和 IOI 的成绩分别达到了人类选手第二名和第十名的水平。
但 Speciale 版本 是针对高度复杂任务优化,消耗的 Token 更多、且成本更高,目前仅供研究使用,不支持工具调用,未针对日常对话优化。
DeepSeek-V3.2 与其他模型在各类数学、代码与通用领域评测集上的得分(括号内为消耗 Tokens 总量约数)
03
工具调用也能 thinking 了
03
工具调用也能 thinking 了
本次更新的一个核心突破是将思考过程融入工具调用。DeepSeek-V3.2 同时支持思考模式与非思考模式的工具调用。
DeepSeek 提出了一种大规模 Agent 训练数据合成方法,构建了大量「难解答,易验证」的任务,显著提升了模型的泛化能力。
DeepSeek-V3.2 与其他模型在各类智能体工具调用评测集上的得分
在各类智能体工具调用评测集上,DeepSeek-V3.2 达到了当前开源模型的最高水平,大幅缩小了与闭源模型之间的差距。但模型并未针对测试集进行特殊训练,在真实场景中具有较强的泛化性。
示例:通过 LobeChat 使用 DeepSeek-V3.2 的深度思考+工具调用能力得到更加详细准确的回复
AI 顶尖科学家、前 OpenAI 联创 Ilya Sutskever 的 18 个最新思考
Vibe Coding 产品最大的错觉,是以为自己真的有护城河
转载原创文章请添加微信:founderparker
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢