
——背景——
随着生成式人工智能技术的快速发展,蛋白质设计领域也经历着计算方法的快速迭代。在以RFdiffusion为代表的扩散模型展现出从结合蛋白设计,离子通道蛋白设计到抗体设计的能力后,酶的设计也被提上日程。金属水解酶(metallohydrolases) 是通过所结合的金属离子来活化水分子,使其位于待断裂底物键的附近,从而催化水解反应进行的酶。之前从头设计方法也被用于金属水解酶设计,但是得到的酶活性通常较低,需要经过大量定向进化才能达到天然酶的水平。
昨日,华盛顿大学David Baker课题组在nature发表了题为“Computational design of metallohydrolases”的文章[1]。文章报道了他们使用最新训练的基于流匹配(flowing match)的新一代生成模型RFdiffusion2对锌离子配位的金属水解酶进行的设计。仅通过对96个设计蛋白的实验,未通过高通量筛选和定向进化,他们就得到了催化效率接近天然金属水解酶的全新金属水解酶。值得一提的是,本文所用到的RFdiffusion2模型也同日见刊于nature methods[2]。
——主要结果——
1.RFdiffusion2设计方法
尽管前一代的RFdiffusion在多种设计场景中都取得了很好的效果,但它只支持主链级别的motif 嵌入(scaffolding),而新款的RFdiffusion2支持任意原子级的motif嵌入。作者认为RFdiffusion2(下称RFD2)相比前代有两方面的改进。第一就是原子级的motif嵌入。作者认为这对于酶设计非常关键,因为原子级的motif固定使得用户精确地指定与反应过渡态相互作用的关键功能基团的位置成为可能。第二是RFD2不需要指定motif所属残基在一级序列中的位置,这使得模型能够对序列位置未知的motif进行嵌入。凭借这些改进,RFdiffusion2能够直接从输入的功能基团及底物的坐标生成多样化的蛋白结构。
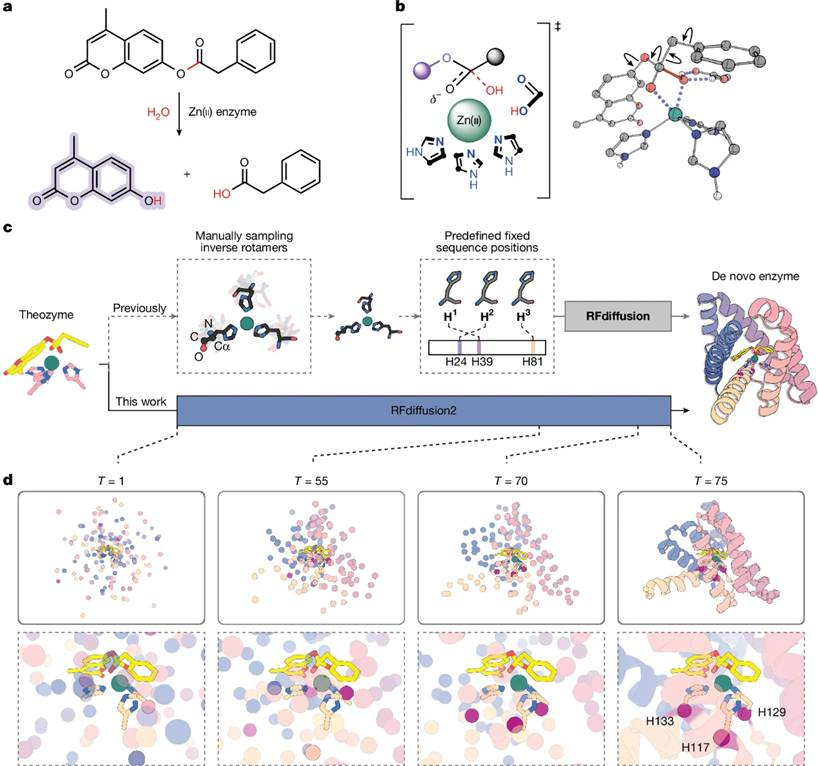
图1、RFdiffusion2设计方法
2. RFdiffusion2的首次测试——锌离子金属水解酶的设计
作为RFD2的首次测试,作者选择设计一种能催化荧光底物4-MU-PA(4-甲基伞形酮基苯乙酸酯,图1a)酯键水解的锌金属水解酶。
作者首先使用密度泛函理论(DFT)确定了本水解反应决速步中Zn(II)-OH 对底物酯键亲核攻击的过渡态构型。基于四面体中间体的立体化学及氧阴离子空穴的类型,作者考虑了四种不同的催化排列方式(图1b)。这些计算提供了三个结合Zn(II)的咪唑环、锌离子及过渡态的坐标。
以此为例,作者对两代RFdiffusion进行了对比:如果使用以前的RFdiffusion,需要将主链残基与残基位置作为输入,这就需要实现对每个组氨酸的侧链扭转角和主链二面角进行采样。这对算力有很高的要求。而新的基于流匹配的RFD2则可以在每条生成轨迹中自行搜索整个构象空间。图1d就是一条生成轨迹的示例。
作者从不同的随机种子出发,总共运行了 5120条RFdiffusion2 推理轨迹,并对每一个生成的蛋白骨架使用 ProteinMPNN进行序列设计。对于那些 AlphaFold2 预测结构与设计模型高度一致的设计,作者通过LigandMPNN和带约束的 Rosetta进行进一步的序列优化。之后,作者在设计结果中筛选出与Zn(II)-结合水分子处于氢键距离内具有可作为一般碱活化水分子的残基(Glu、Asp 或 His)且具有稳定过渡态氧阴离子的侧链氢键,并且AlphaFold2预测能够折成目标结构的设计。这些设计随后使用PLACER评估活性位点的预组织化程度。基于预测的活性位点几何构型与预组织化程度,作者最终选择了96个设计进行实验验证。
作者将这96个设计蛋白的序列合成并通过大肠杆菌表达纯化后,对纯化的蛋白中加入硫酸锌,利用荧光检测了其对4MU-PA的水解能力。结果显示,共有 5 个设计(A1、A8、B9、C4、F7) 的活性显著高于背景(图2b)。作者随后对这五个蛋白进行了酶促反应动力学参数的测定,发现:A1(最高活性) 的 kcat/KM 为 16,000 ± 2,000 M⁻¹·s⁻¹,其余四个设计的 kcat/KM 为 35–140 M⁻¹·s⁻¹。作为对比,之前设计的金属水解酶的 kcat/KM 范围仅为 3–60 M⁻¹·s⁻¹。
作者通过与PDB和AFDB中的结构进行比对,发现A1与已知最相似的结构的TM-score分别仅为 0.41 与 0.49,且这些结构不具有类似的催化残基排列,所以认为A1与已知蛋白差异很大。在后文中,作者将A1称为 zinc metalloesterase 1(ZETA_1)。通过将ZETA_1与其他无活性的蛋白的PLACER预测结果比对,作者发现ZETA_1 在两个方面尤为突出:一是催化位点预组织化程度高。二是底物–过渡态在活性位点的定位稳定(图2e-h)。同时作者还发现PLACER 结构集合分析在识别活性设计中有很好的实用性。
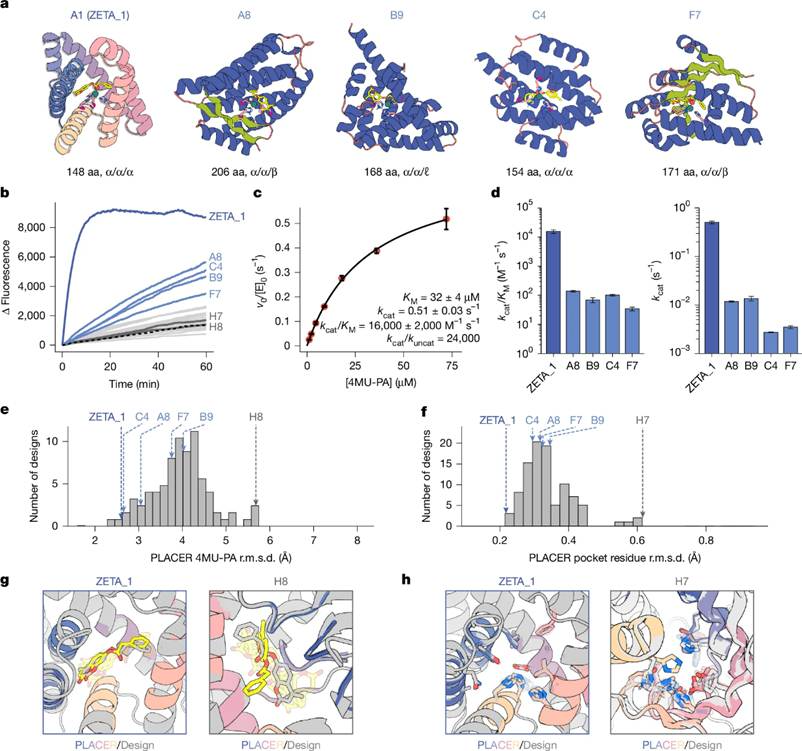
图2、锌离子水解酶的活性表征
3.第二轮设计——更强的催化效率
基于上述发现,作者从新计算的过渡态出发,明确包含一般碱残基,并使用新版本RFdiffusion2(从随机权重开始训练、数据集扩大三倍,而非从预测权重微调)生成蛋白骨架(图3a)。
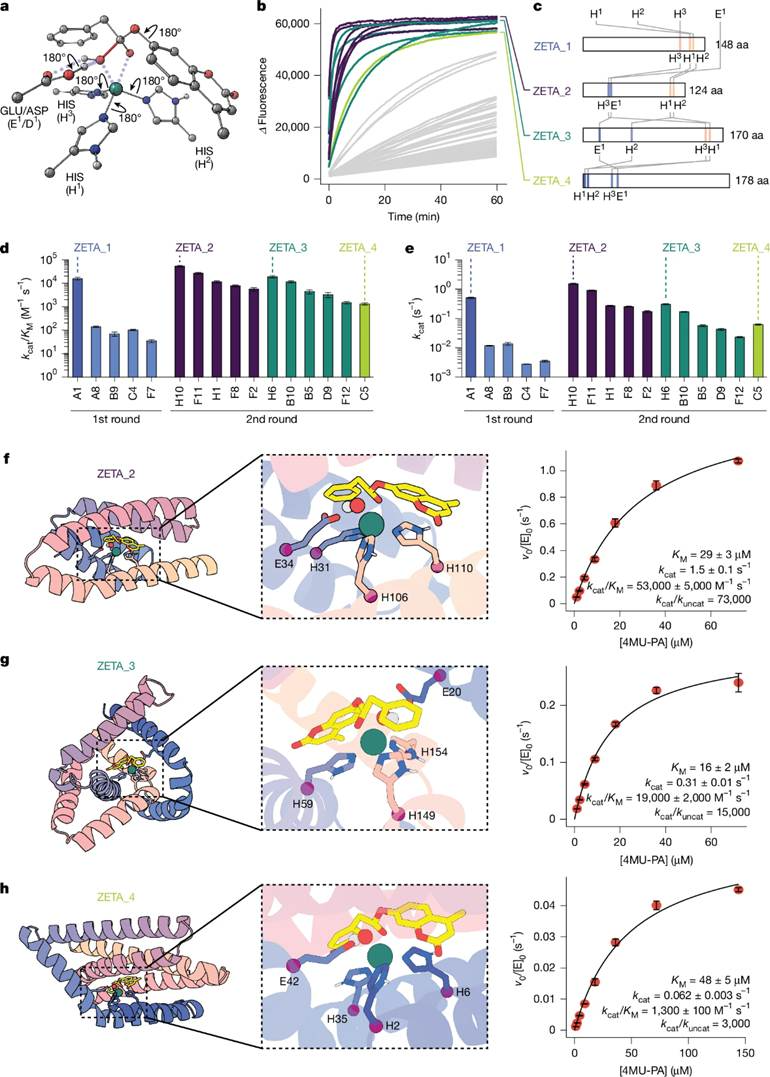
图3、第二轮水解酶设计结果的表征
然后作者使用 Chai-1 预测其蛋白–Zn(II)–底物膦酸酯复合物(模拟反应过渡态),并由 PLACER 识别活性位点高度预组织化的设计。最终,在37个 RFdiffusion2 生成的骨架上筛选了 96个设计进行实验验证。结果显示:
96 个设计中有 85 个成功表达且可溶。
11 个设计具有显著的锌依赖的4MU-PA 水解活性。
酶促反应动力学分析显示(图3d):
5 个设计的 kcat/KM > 10⁴ M⁻¹·s⁻¹
6 个设计的 kcat/KM > 10³ M⁻¹·s⁻¹
每个骨架最高的活性分别为:ZETA_2:kcat/KM = 53,000 ± 5,000 M⁻¹·s⁻¹,ZETA_3:kcat/KM = 19,000 ± 2,000 M⁻¹·s⁻¹,ZETA_4:kcat/KM = 1,100 ± 200 M⁻¹·s⁻¹。其中,ZETA_2 的 kcat = 1.5 ± 0.1 s⁻¹,是 ZETA_1 的三倍,接近经过十轮定向进化得到的金属水解酶 MID1sc的 kcat 值。
RFdiffusion2 允许指定底物相对于蛋白质质心的位置,从设计结果可以看出,在 ZETA_2 中,蛋白质围绕底物的苯乙酸部分设计;在 ZETA_3 中,蛋白质围绕 4-甲基香豆素部分设计,从而导致两者底物结合模式相反。
从结果可以看出,第二轮设计的成功率显著高于第一轮(96 个设计中有 11 个达到 kcat/KM > 10³ M⁻¹·s⁻¹,而第一轮仅有 1 个),这支持了第一轮分析所得的结论。ZETA_1–4 的结构彼此差异很大,也与已知的金属水解酶明显不同。这些酶中催化残基的序列位置也非常不同,体现了 RFdiffusion2 生成设计方案的高度多样性。作者还解析了活性最高的ZETA_2的无配体状态结构(3.5 Å)和经过 Zn(II) 浸泡后有配体的结构(2.1 Å),结果显示实际结构与设计模型高度一致。
——结论——
在本研究中,作者证明了RFdiffusion2能够直接从量子化学计算获得的活性位点构型生成具有高度活性的金属水解酶。无需任何实验优化、零样本(zero-shot) 即可设计出活性超过 10⁴ M⁻¹·s⁻¹ 的酶(ZETA_1)。这相较于过去需要大量设计筛选和定向进化才能达到类似活性的从头设计方法而言,是一次显著的进步。同时,利用PLACER和 Chai-1对活性位点预组织化及底物–过渡态定位进行评估,也被证明在识别高度活性的设计中相当有效。
参考文献:
[1] Kim, D., Woodbury, S.M., Ahern, W. et al. Computational design of metallohydrolases. Nature (2025). https://doi.org/10.1038/s41586-025-09746-w
[2] Ahern, W., Yim, J., Tischer, D. et al. Atom-level enzyme active site scaffolding using RFdiffusion2. Nat Methods (2025). https://doi.org/10.1038/s41592-025-02975-x

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢