

新智元报道
新智元报道
【新智元导读】Anthropic发布了Programmatic Tool Calling(PTC)特性,让Claude通过代码编排工具执行,降低token消耗、减少延迟并提升准确性。不过,国产minion框架从一开始就采用类似架构,其LLM规划决策,代码环境执行,仅返回最终结果。相比PTC需显式启用,minion将此作为基础架构,还支持Python生态、状态管理、错误处理等功能,在实际应用中展现出更高的效率和灵活性。
2025年11月24日,Anthropic正式发布了Programmatic Tool Calling (PTC)特性,允许Claude通过代码而非单次API调用来编排工具执行。
这一创新被认为是Agent开发的重要突破,能够显著降低token消耗、减少延迟并提升准确性。
然而,Minion框架的创建者最近分享了一个有趣的事实:Minion从一开始就采用了这种架构理念。
代码链接:https://github.com/femto/minion
在PTC概念被正式提出之前,minion已经在生产环境中证明了这种方法的价值。

Anthropic在博文中指出了传统Tool Calling的两个核心问题:
1. Context污染问题
传统方式中,每次工具调用的结果都会返回到LLM的context中。例如分析一个10MB的日志文件时,整个文件内容会进入context window,即使LLM只需要错误频率的摘要。
2. 推理开销与手动综合
每次工具调用都需要一次完整的模型推理。LLM必须「眼球式」地解析数据、提取相关信息、推理片段如何组合,然后决定下一步——这个过程既缓慢又容易出错。
Minion框架从设计之初就采用了一种根本不同的架构:LLM专注于规划和决策,具体执行交给代码环境。
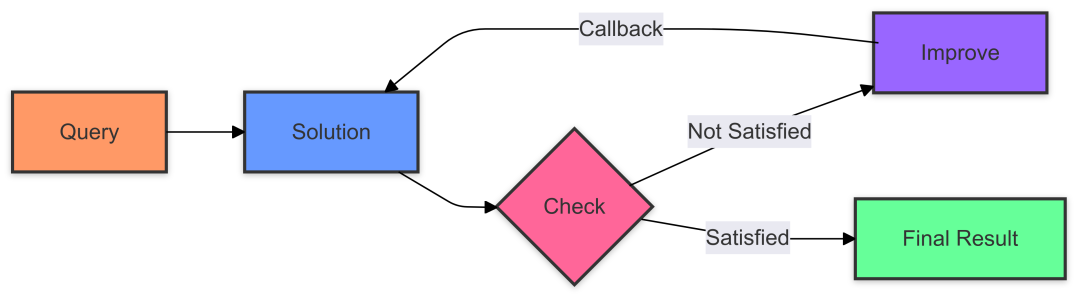
Minion的典型工作流包括:
1. LLM分析用户需求,制定执行计划;
2. LLM生成Python代码来编排工具调用;
3. 代码在隔离环境中执行,处理所有数据操作;
4. 只有最终结果返回给LLM
这正是PTC想要实现的效果,但minion将其作为基础架构而非可选特性。
Anthropic博文中的预算合规检查示例。

传统Tool Calling方式:
获取团队成员 → 20人
为每人获取Q3费用 → 20次工具调用,每次返回50-100条费用明细
获取各级别预算限额
所有数据进入context:2000+条费用记录(50KB+)
LLM手动汇总每人费用、查找预算、比较超支情况
使用PTC后:
Claude写一段Python脚本编排整个流程
脚本在Code Execution环境运行
LLM只看到最终结果:2-3个超支人员
在Minion中,这种模式是默认行为,llm会生成代码:
# Minion中的实现(伪代码)async def check_budget_compliance(): # LLM生成的计划代码 team = await get_team_members("engineering") # 并行获取所有数据 levels = list(set(m["level"] for m in team)) budgets = { level: await get_budget_by_level(level) for level in levels } # 数据处理在本地完成 exceeded = [] for member in team: expenses = await get_expenses(member["id"], "Q3") total = sum(e["amount"] for e in expenses) budget = budgets[member["level"]] if total > budget["travel_limit"]: exceeded.append({ "name": member["name"], "spent": total, "limit": budget["travel_limit"] }) return exceeded # 只返回关键结果
关键区别在于,Minion是框架的核心设计,所有复杂任务都这样处理;
而PTC需要显式启用,存在多重架构限制:
必须显式标记哪些工具允许programmatic调用(allowed_callers配置)
运行在受限的Claude容器环境中,无法自由安装任意包
文件需要通过额外的Files API上传(单文件最大500MB限制)
工具必须在容器4.5分钟不活动超时前返回结果
Web工具、MCP工具无法通过programmatic方式调用

Minion不仅实现了PTC的核心理念,还提供了更多优势:

Minion中的代码执行环境拥有完整的Python生态访问权:
# Minion可以直接使用任何Python库import pandas as pdimport numpy as npfrom sklearn.cluster import KMeans# 强大的数据处理df = pd.DataFrame(expense_data)analysis = df.groupby('category').agg({ 'amount': ['sum', 'mean', 'std'], 'count': 'size'})# 复杂的数据科学任务model = KMeans(n_clusters=3)clusters = model.fit_predict(spending_patterns)
Minion天然支持复杂的状态管理:
class BudgetAnalyzer: def __init__(self): self.cache = {} self.history = [] async def analyze_department(self, dept): # 状态在整个分析过程中保持 if dept in self.cache: return self.cache[dept] result = await self._deep_analysis(dept) self.cache[dept] = result self.history.append(result) return result
在代码中显式处理各种边界情况:
async def robust_fetch(user_id, max_retries=3): for attempt in range(max_retries): try: return await get_expenses(user_id, "Q3") except RateLimitError: await asyncio.sleep(2 ** attempt) except DataNotFoundError: return [] # 合理的默认值 raise Exception(f"Failed after {max_retries} attempts")
充分利用Python的异步能力:
async def analyze_all_departments(): departments = ["eng", "sales", "marketing", "ops"] results = await asyncio.gather(*[ analyze_department(dept) for dept in departments ]) return consolidate_results(results)
根据Anthropic的内部测试,PTC带来了显著改进:
Token节省:复杂研究任务从43,588降至27,297 tokens(减少37%)
延迟降低:消除了多次模型推理往返
准确率提升:
内部知识检索:25.6% → 28.5%
GIA基准测试:46.5% → 51.2%
在minion的生产使用中,能观察到类似甚至更好的指标,因为:
更少的模型调用:LLM只在规划阶段和最终总结时参与
更高效的资源利用:本地数据处理不消耗API tokens
更可预测的性能:代码执行路径明确,减少了LLM的不确定性
Minion的设计基于一个核心信念:
LLM擅长理解、规划和推理;Python擅长执行、处理和转换。
这种职责分离带来了清晰的架构:
用户请求 ↓[LLM:理解意图,制定计划] ↓[生成Python代码] ↓[代码执行环境:调用工具、处理数据、控制流程] ↓[返回结构化结果] ↓[LLM:解读结果,生成用户友好的响应]
这不仅仅是优化,而是一种架构级别的重新思考。

Anthropic的另一个新特性是Tool Search Tool,解决大型工具库的context消耗问题。Minion在这方面也有相应的机制:

# Minion的工具分层策略class MinionToolRegistry: def __init__(self): self.core_tools = [] # 始终加载 self.domain_tools = {} # 按需加载 self.rare_tools = {} # 搜索发现 def get_tools_for_task(self, task_description): # 智能工具选择 tools = self.core_tools.copy() # 基于任务描述添加相关工具 if "database" in task_description: tools.extend(self.domain_tools["database"]) if "visualization" in task_description: tools.extend(self.domain_tools["plotting"]) return tools
# 使用embedding的工具搜索from sentence_transformers import SentenceTransformerclass SemanticToolSearch: def __init__(self, tool_descriptions): self.model = SentenceTransformer('all-MiniLM-L6-v2') self.tool_embeddings = self.model.encode(tool_descriptions) def find_tools(self, query, top_k=5): query_embedding = self.model.encode([query]) similarities = cosine_similarity(query_embedding, self.tool_embeddings) return self.get_top_tools(similarities, top_k)
Minion框架已经在多个实际场景中证明了这种架构的价值:
金融科技公司使用minion分析数百万条交易记录,寻找异常模式:
async def detect_anomalies(): # LLM规划:需要获取数据、清洗、特征工程、异常检测 # 执行代码直接处理大数据集 transactions = await fetch_all_transactions(start_date, end_date) # 1M+ records, 但不进入LLM context df = pd.DataFrame(transactions) df = clean_data(df) features = engineer_features(df) # 使用机器学习检测异常 anomalies = detect_with_isolation_forest(features) # 只返回异常摘要给LLM return { "total_transactions": len(df), "anomalies_found": len(anomalies), "top_anomalies": anomalies.head(10).to_dict() }
结果:
处理100万条记录
LLM仅消耗~5K tokens(传统方式需要500K+)
端到端延迟:30秒(vs 传统方式的5分钟+)
SaaS公司使用minion整合来自多个API的客户数据:
async def comprehensive_customer_analysis(customer_id): # 并行获取所有数据源 crm_data, support_tickets, usage_logs, billing_history = await asyncio.gather( fetch_crm_data(customer_id), fetch_support_tickets(customer_id), fetch_usage_logs(customer_id), fetch_billing_history(customer_id) ) # 本地数据融合和分析 customer_profile = { "health_score": calculate_health_score(...), "churn_risk": predict_churn_risk(...), "upsell_opportunities": identify_opportunities(...), "support_sentiment": analyze_ticket_sentiment(support_tickets) } return customer_profile
DevOps团队使用minion自动化复杂的部署流程:
async def deploy_with_validation(): # 多步骤工作流,每步都有条件逻辑 # 1. 运行测试 test_results = await run_test_suite() if test_results.failed > 0: return {"status": "blocked", "reason": "tests failed"} # 2. 构建和推送镜像 image = await build_docker_image() await push_to_registry(image) # 3. 金丝雀部署 canary = await deploy_canary(image, percentage=10) await asyncio.sleep(300) # 监控5分钟 metrics = await get_canary_metrics(canary) if metrics.error_rate > 0.01: await rollback_canary(canary) return {"status": "rolled_back", "metrics": metrics} # 4. 完整部署 await deploy_full(image) return {"status": "success", "image": image.tag}

虽然PTC是一个重要的进步,但minion的架构设计让我们能够探索更多可能性:

在一个会话中智能切换:
if task.complexity < THRESHOLD: result = await simple_tool_call(task)else: orchestration_code = await llm.generate_code(task) result = await execute_code(orchestration_code)
智能重用中间结果:
# 记忆化的数据获取async def cached_get_user_data(user_id): return await fetch_user_data(user_id)# 增量更新而非全量重算async def update_analysis(new_data): previous_state = load_checkpoint() delta = compute_delta(previous_state, new_data) updated_state = apply_delta(previous_state, delta) return updated_state
不同模型处理不同阶段:
# 规划用强模型plan = await claude_opus.create_plan(user_request)# 代码生成用专门模型code = await codegen_model.generate(plan)# 执行和监控result = await execute_with_monitoring(code)# 用户交互用快速模型response = await claude_haiku.format_response(result)
Minion作为开源项目(300+ GitHub stars),其发展得益于社区的贡献和反馈。这种开放性带来了:
快速迭代:社区发现问题和用例,推动快速改进
多样化应用:用户在我们未曾想象的场景中使用minion
相比之下,PTC虽然强大,但:
需要显式配置(
allowed_callers,defer_loading等)依赖特定的API版本和beta功能
与Claude的生态系统紧密耦合
Minion的设计原则是provider-agnostic——你可以用任何LLM后端(Claude, GPT-4, 开源模型),架构优势依然存在。
深入比较实现细节。
# Anthropic的PTC需要特定配置{ "tools": [ { "type": "code_execution_20250825", "name": "code_execution" }, { "name": "get_team_members", "allowed_callers": ["code_execution_20250825"], ... } ]}# Claude生成工具调用{ "type": "server_tool_use", "id": "srvtoolu_abc", "name": "code_execution", "input": { "code": "team = get_team_members('engineering')\\\\\\\\n..." }}

# Minion的工具定义是标准Pythonclass MinionTools: @tool async def get_team_members(self, department: str): """Get all members of a department""" return await self.db.query(...) @tool async def get_expenses(self, user_id: str, quarter: str): """Get expense records""" return await self.expenses_api.fetch(...)# LLM生成的是完整的Python函数async def analyze_budget(): # 直接调用工具函数 team = await tools.get_team_members("engineering") # 完整的Python语言能力 expenses_by_user = { member.id: await tools.get_expenses(member.id, "Q3") for member in team } # 任意复杂度的数据处理 analysis = perform_complex_analysis(expenses_by_user) return analysis
关键区别:
PTC:工具调用通过特殊的API机制,有caller/callee关系
Minion:工具就是普通的Python async函数,LLM生成标准代码

随着AI Agent向生产环境发展,业界面临的核心挑战是:
规模:处理百万级数据,不能全塞进context
可靠性:生产系统需要确定性的错误处理
成本:token消耗直接影响商业可行性
性能:用户体验需要亚秒级响应
传统的单次工具调用模式在这些维度上都遇到瓶颈。代码编排模式(无论是PTC还是minion)提供了突破:
传统模式:LLM <-> Tool <-> LLM <-> Tool <-> LLM (慢) (贵) (脆弱)编排模式:LLM -> [Code: Tool+Tool+Tool+Processing] -> LLM (快) (省) (可靠)
经过验证的架构:PTC的发布证明了架构选择的正确性——这不是投机性的设计,而是行业领先者独立得出的结论。
先发优势:在PTC成为官方特性之前,minion已经在生产环境积累了经验和最佳实践。
更广泛的适用性:
支持多种LLM后端(Claude, GPT-4, 开源模型);
灵活的部署选项(云端、本地、混合);
丰富的Python生态系统集成。
社区和生态:300+stars代表的不仅是认可,还有潜在的用户基础和贡献者社区。
Anthropic推出PTC不是偶然——这是agent架构演进的必然方向。当你需要构建能处理复杂任务、大规模数据、多步骤流程的生产级agent时,你会自然而然地得出这样的结论:
LLM应该专注于它擅长的(理解和规划),让代码处理它擅长的(执行和转换)。
Minion从一开始就拥抱了这个理念,并将继续推动这个方向:
✅ 今天:完整的PTC式架构,生产环境验证
🚀 明天:更智能的工具发现、更高效的状态管理
🌟 未来:混合推理、增量计算、多模型协作
郑炳南,毕业于复旦大学物理系。拥有20多年软件开发经验,具有丰富的传统软件开发以及人工智能开发经验,是开源社区的活跃贡献者,参与贡献metagpt、huggingface项目smolagents、mem0、crystal等项目,为ICLR 2025 oral paper《AFlow: Automating Agentic Workflow Generation》的作者之一。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢