报告主题:链式视觉思维(CoVT)框架,让VLM看得更清,想得更准
报告日期:12月09日(周二)10:30-11:30
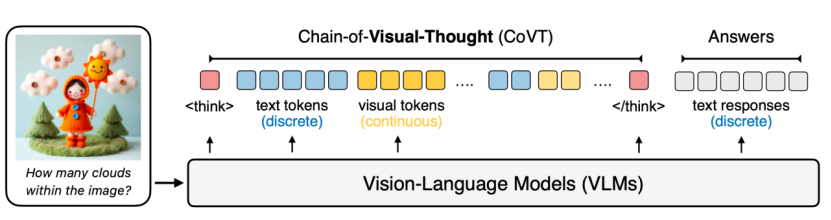
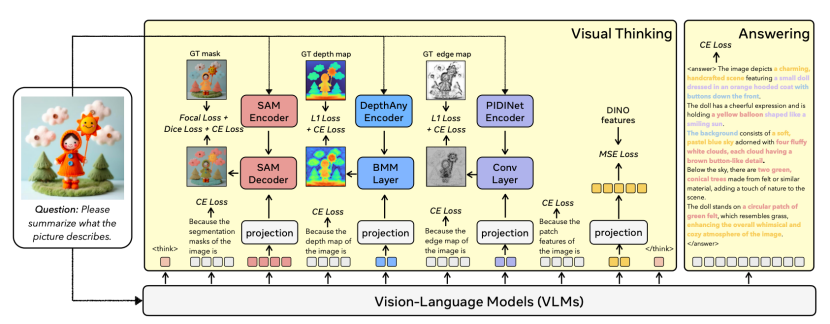
视觉-语言模型(VLM)在语言空间中的推理表现卓越,但在密集视觉的理解方面有所不足。这一局限源于当前 VLM 在跨空间维度捕获大量视觉信息的能力比较有限。为此,我们提出 Chain-of-Visual-Thought(CoVT),在标准 VLM 的自回归“下一token预测”范式上,引入一类新的连续视觉token(Continuous Visual Tokens),从而在推理链(CoT)中更直接地展示模型的视觉思维。在训练过程中,模型被要求预测这些视觉 token,再通过解码器(decoder)重建对应的视觉特征。并通过重建损失进行反向传播,使模型内部视觉理解能力对齐对应的vision encoder。为覆盖各种不同视觉场所,我们为CoVT 设计了四类视觉token,并分别由不同vision encoder“专家”做监督:- Segmentation tokens:由 SAM 监督,产生8个token作为 mask prompt。
- Depth tokens:由 DepthAnything v2 监督,产生4 个 token 用于重建深度图。
- Edge tokens:由 PIDINet 监督,产生4 个 token 用于重建边缘图。
- DINO tokens:由 DINOv2 特征监督,直接对齐DINOv2 Encoder输出的特征。
在大约 20 个 token小预算下,CoVT 从多种视觉专家(Vision Encoder)中捕捉知识,捕获二维外观、三维几何、空间布局和边缘结构等互补属性。将 CoVT 集成到 Qwen2.5-VL 和 LLaVA 等强大 VLM 中,在包括 CV-Bench、MMVP、RealWorldQA、MMStar、WorldMedQA 和 HRBench 在内的十余个多样化感知基准上进行评估表明,可稳定带来 3%–16% 的性能提升,证明紧凑的连续视觉思维能够帮助更精确、更扎实且更具可解释性的多模态智能。秦艺铭,北京大学智班 22 级本科生,师从智班22级班主任、王选计算机研究所博士生导师刘洋。此前于加州大学伯克利分校交换,在 BAIR 科研实习,师从 Trevor Darrell,与 XuDong Wang 密切合作。研究兴趣主要是 Vision-Language Models 和 Generative Models。扫码报名
更多热门报告


内容中包含的图片若涉及版权问题,请及时与我们联系删除





评论
沙发等你来抢