
药物-靶标相互作用(DTI)预测对药物重定位十分重要。现有基于序列的DTI预测模型在例如BioSNAP、BindingDB等数据集上通常会出现有偏预测,即模型依赖某一种输入进行预测而不是真正的相互作用,以往研究将有偏预测归因于“药物偏差”。本研究首次系统揭示并验证了“靶标先验偏差” (target prior bias) 是影响模型泛化能力的主要因素。该偏差源于训练数据中靶标标签分布的不平衡(即先验倾向, prior tendency),导致模型学习到虚假关联而非真实的相互作用机制。为此,本文提出干预训练去偏框架TAPB,旨在实现更稳健、可泛化的DTI预测。

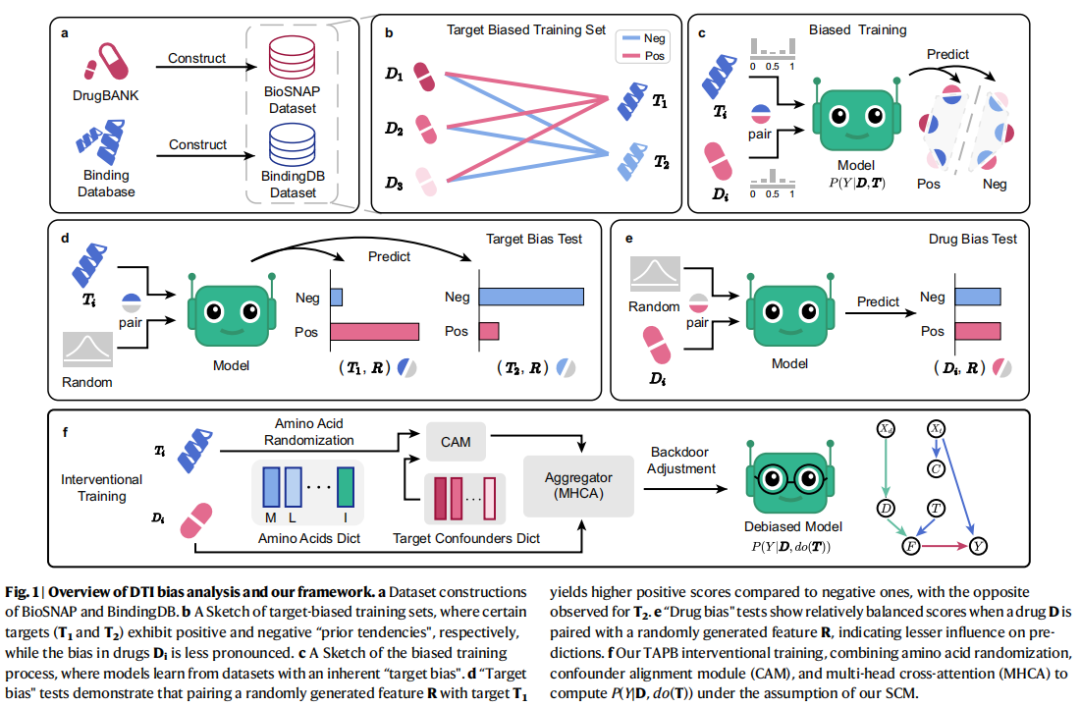
在药物-靶标相互作用预测领域,传统数据驱动模型通常采用双塔架构,分别编码药物与靶标特征后进行融合与分类。然而,如图1a所示,在广泛使用的BioSNAP与BindingDB等序列数据集上训练的模型,普遍存在预测偏倚问题,导致其泛化能力受限。先前的工作,包括TransformerCPI、DrugBAN与UdanDTI等,均将这一问题主要归因于“药物偏差”,即模型过度依赖药物特征进行判断。
与此不同,本研究通过系统性分析发现,在现有的序列数据集中,一个更根本且被忽视的偏倚来源是“靶标先验偏差”。如图1b所示,这种偏倚源于训练数据中靶标标签分布的严重不平衡(即“先验倾向”),例如特定靶标在训练集中绝大多数样本均为正相互作用或负相互作用。这种数据结构会导致模型(图1c)简单地记忆靶标的标签倾向,而非学习真实的相互作用机制。为验证这一观点,本文设计了如图1d与1e所示的可视化测试:将训练好的模型输入替换为随机特征与靶标或药物的组合。可视化的结果表明,模型对靶标特征表现出强烈的预测倾向,而对药物特征的依赖则相对均衡,从而证实了靶标偏倚的主导地位。基于此,本文提出了如图1f所示的干预去偏框架TAPB,旨在缓解靶标先验偏倚,推动DTI预测模型向更稳健、更可靠的方向发展。
DTI有偏预测的原因
Drug bias vs target bias:到底哪个更严重?
为验证哪个bias更严重,本文设计了“target bias test”和“drug bias test”。具体而言,将在各数据集上训练好的模型接收的原始药物-靶标对(D,T)替换为两种构造输入:靶标特征与随机高斯张量组合(T,R),以及药物特征与随机高斯张量组合(D,R)。随后利用t-SNE对这两种输入在训练集上产生的分类特征分布进行可视化,结果如图2所示:
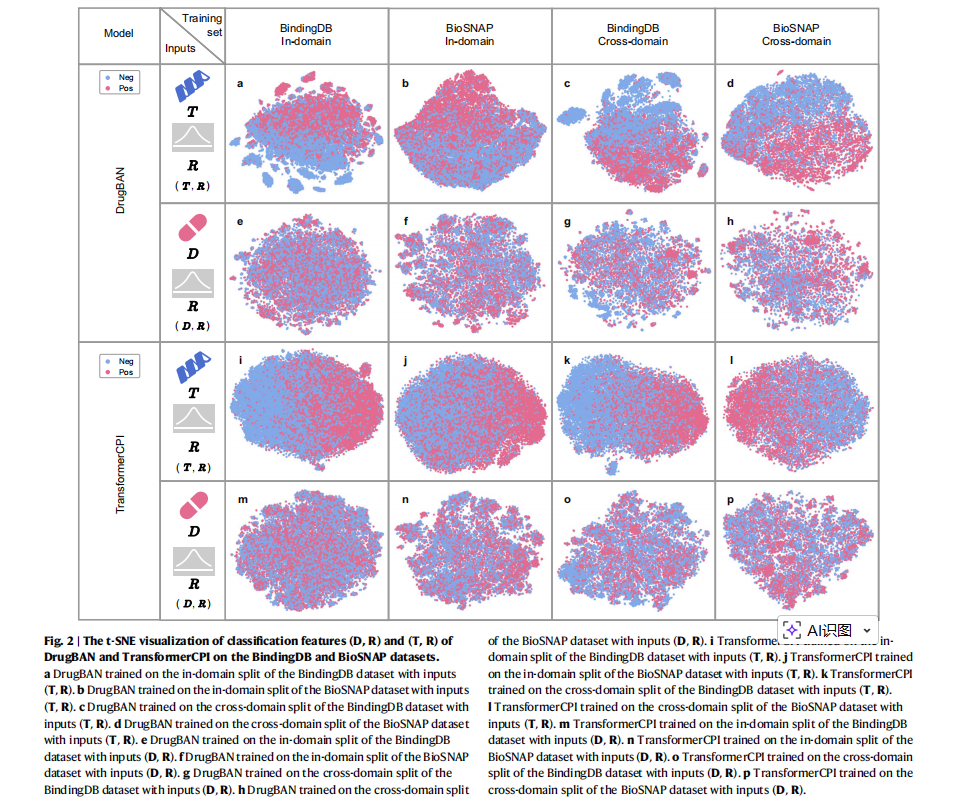
在BindingDB和BioSNAP数据集上,无论使用何种编码器或聚合器,(T,R)输入下正类样本显著聚集,而(D,R)输入下正类样本分布接近随机。这表明模型在预测时更依赖靶标特征,即存在显著的靶标先验偏差,而不是药物偏差。
先验倾向是有偏预测的根本原因
“先验倾向”(prior tendency)指在训练数据中,单个药物或靶标的正负标签分布严重不平衡。例如,某些靶标在训练集中大多为正样本,模型只需记忆靶标的标签倾向即可达到低损失,而无需学习真实的相互作用机制。
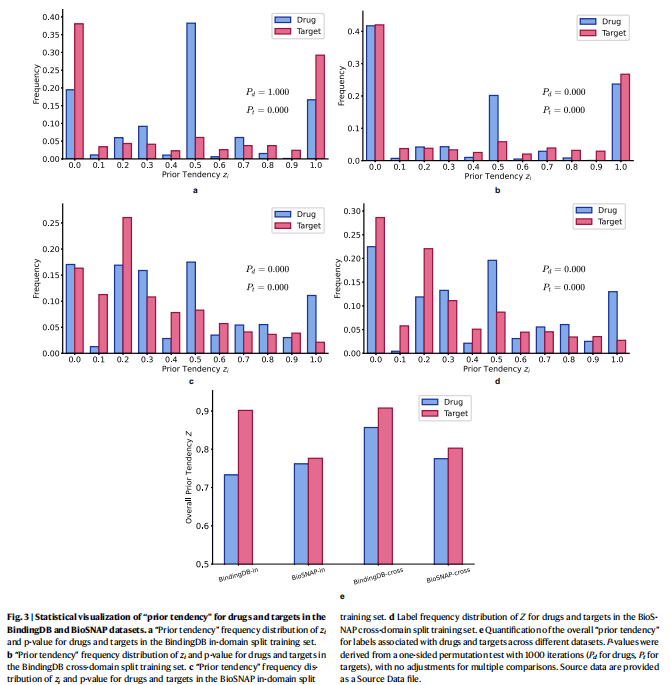
统计结果如图3所示,在BindingDB和BioSNAP数据集(包括in-domain split和cross-domain split)中,靶标的先验倾向显著高于药物,且分布呈现两极分化,进一步证实靶标偏差占主导地位。
然而两种现象同时出现不代表有因果关系。为证明先验倾向是导致偏差的原因,本文构建了重新构建了两个训练集作为对照组,并重新进行2.1的测试(具体构造方式请参考论文,数据集已公开):
药物偏差训练集:药物具有先验倾向,靶标标签分布均衡。
平衡训练集:药物和靶标均无先验倾向。
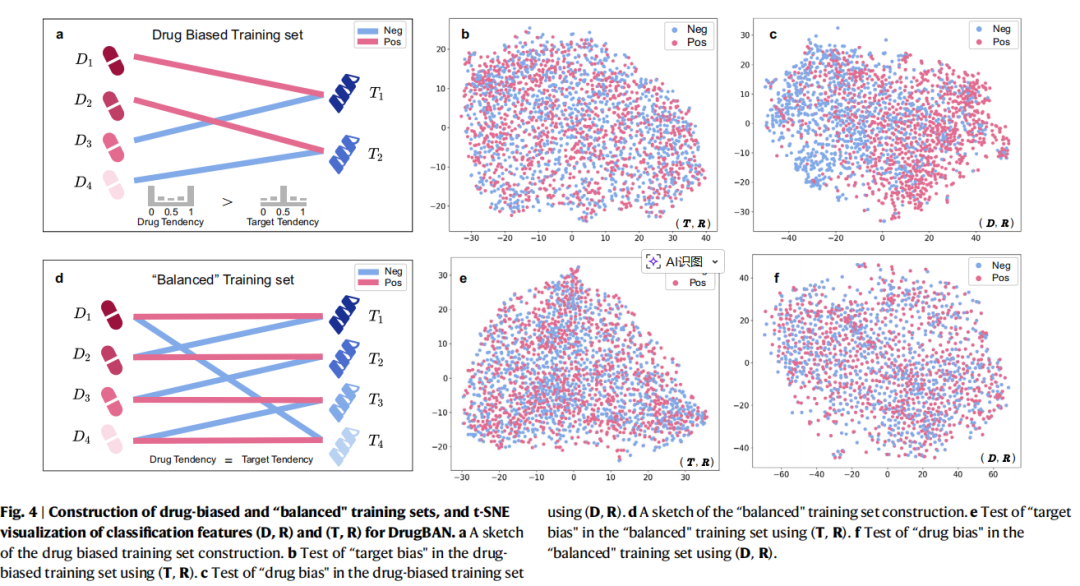
实验可视化结果如图4所示,在药物偏差训练集上,(D, R) 出现正类聚集,而 (T, R) 分布随机;在平衡训练集上,两者均无聚集现象。与图2对比可以验证prior tendency是导致模型有偏预测的根本原因。
方法概述
TAPB通过氨基酸随机化、混杂因子对齐模块(CAM)和后门调整,实现模型预测从
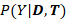 到
到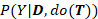 的转变,缓解靶标先验偏差。
的转变,缓解靶标先验偏差。
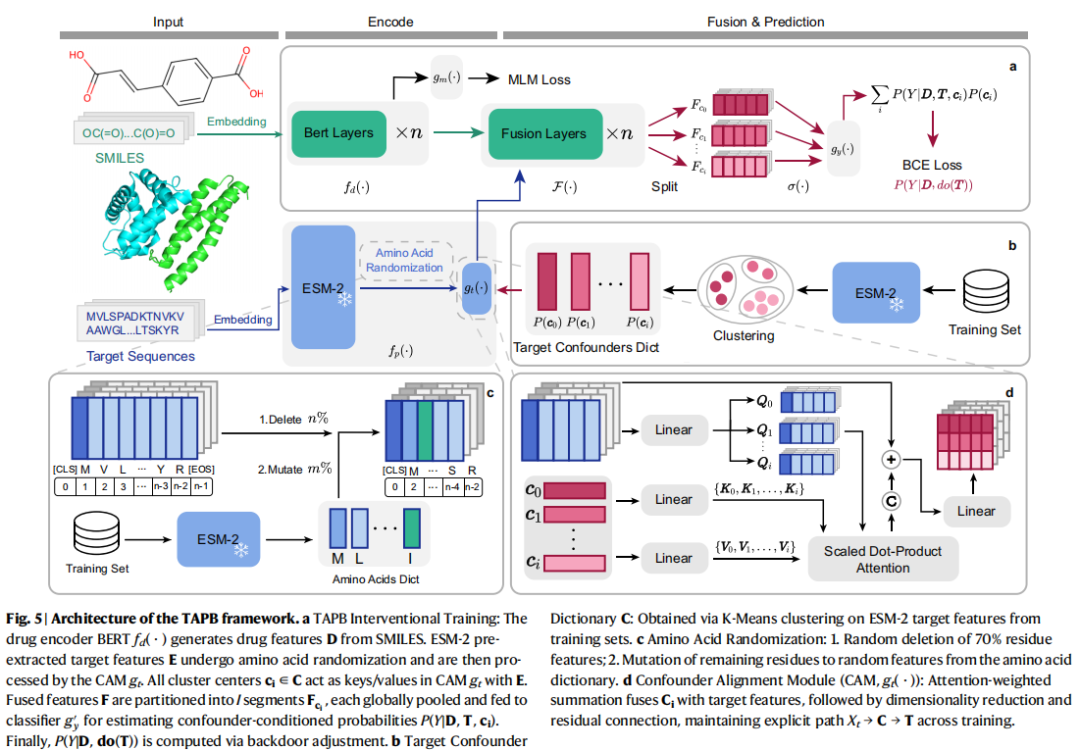
结果
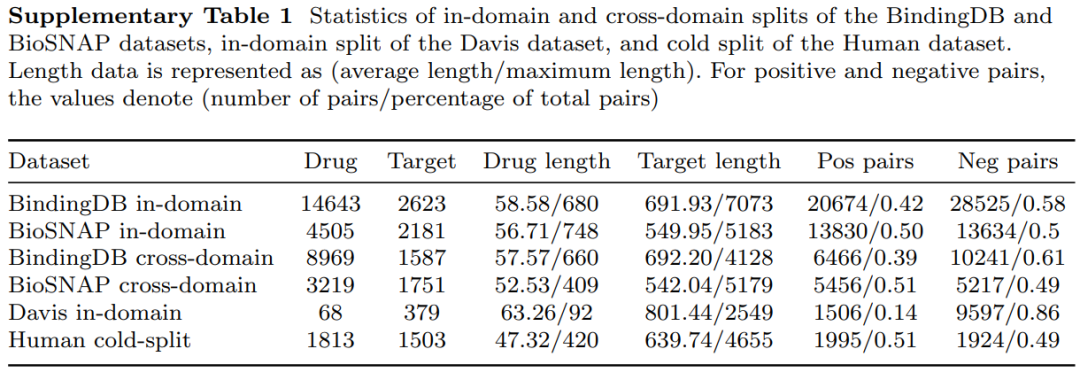
TAPB在多个数据集上进行了全面评估,包括in-domain、cross-domain和cold-split场景。数据集的基础信息统计结果如SI表1所示:
域内性能对比
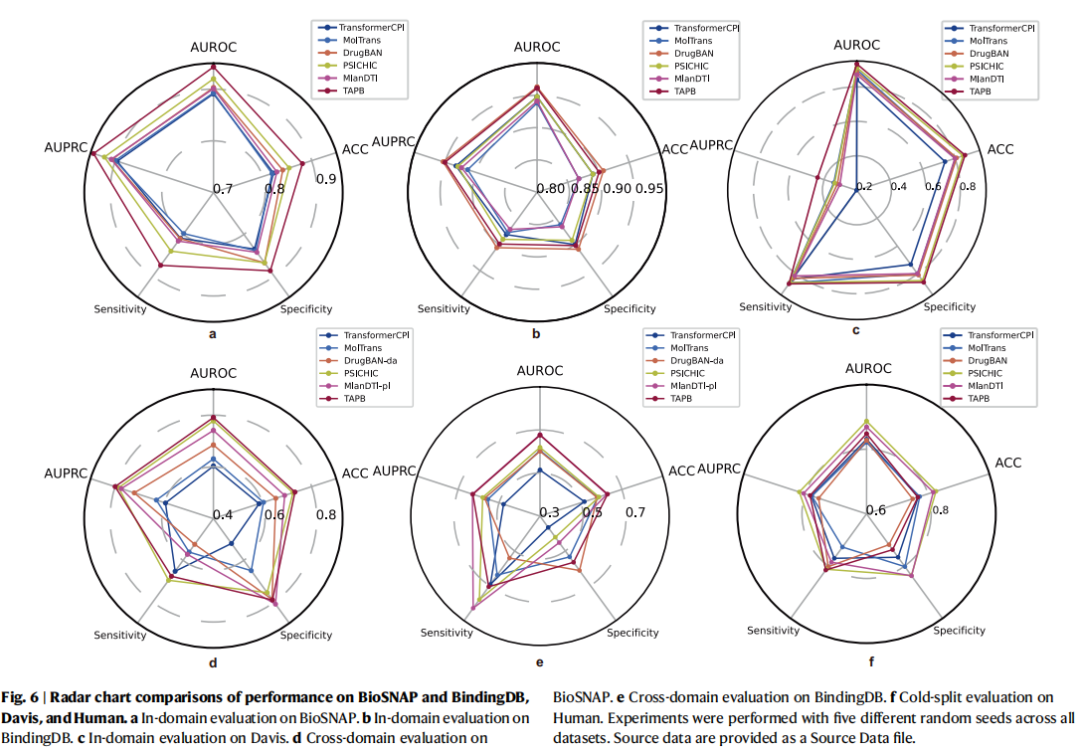
如图6所示,在BioSNAP数据集上,TAPB在所有评估指标上均展现出全面领先的优势,其AUROC和AUPRC分别提升了2.3%与2.2%。相比之下,在靶标先验偏差尤为显著的BindingDB数据集中,TAPB依然保持了强劲的竞争力,其表现与最优基线方法DrugBAN相当。而在Davis数据集的评估中,TAPB则超越了所有基线模型,其中AUPRC大幅提高了7.4%。更值得注意的是,即便在由药物偏差主导的Human数据集上,TAPB依然表现出稳健且可靠的预测性能。
跨域泛化能力
在跨域划分中,TAPB无需域适应技术也能表现出色。如图6所示,在BindingDB跨域任务中,AUROC比使用CDAN的DrugBAN高7.5%并超越其他baselinse,在BioSNAP跨域任务中显著超过4个baseline。这表明TAPB能有效避免对训练集靶标分布的依赖,即缓解了模型靠记忆靶标进行预测,提升了模型对新靶标的泛化能力。
消融实验
多种TAPB变体验证了各组件的贡献,如图7所示:
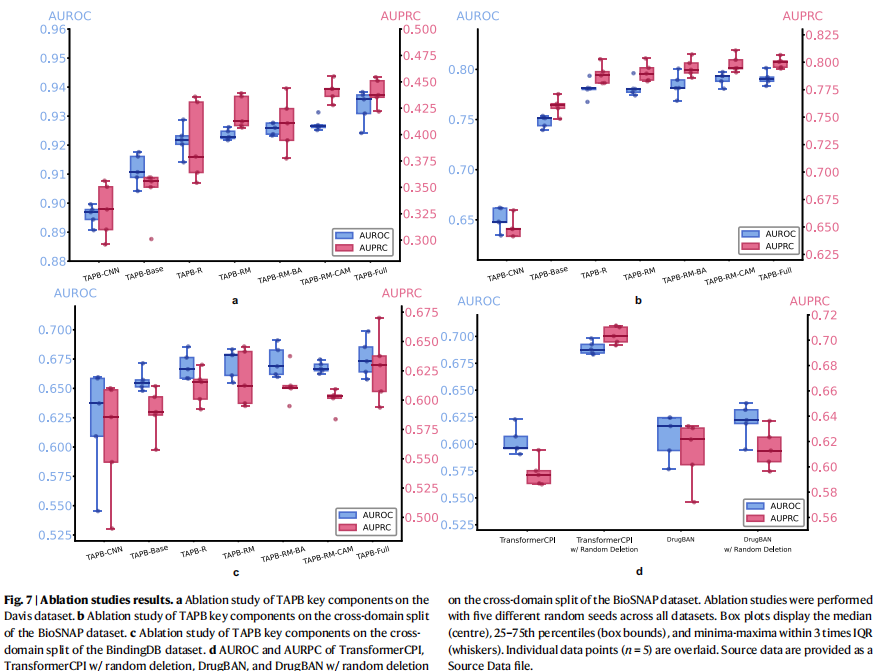
氨基酸随机化:显著提升性能,防止模型记忆靶标;
CAM与后门调整:两者缺一不可,仅使用任一模块性能均下降,符合理论;
ESM-2:替换为随机初始化CNN后性能下降,证实预训练蛋白质特征的重要性;
残基随机删除:应用于其他模型(如TransformerCPI,DrugBAN)也能提升跨域性能,说明该方法是通用的,可以缓解target bias。
讨论
本文发现并验证了DTI预测中“靶标先验偏差”的主要矛盾,提出了一种基于因果干预的去偏框架TAPB,不仅在多个数据集上达到最优或竞争性性能,还具备良好的跨域泛化能力和可解释性。
局限性
可视化结果注意力头之间的一致性较低,部分头关注噪声而非真实结合位点;对于长序列靶标,注意力权重差异不显著,可能受序列长度和Softmax归一化影响;
TAPB主要针对靶标偏差设计,在药物偏差显著的数据集上仍有提升空间;
混淆因子字典C依赖于聚类质量,C仅来源于蛋白质序列的预训练特征。真实的生物混杂机制可能涉及蛋白质三维结构、特定功能域等信息,这些是纯序列特征无法完全捕获的。这可能导致字典仅是真实不可观测的测混杂因子一个不完美的代理。
未来方向
探索更多类型的偏差(如功能基团偏差、子序列偏差);
结合多模态数据(结构、功能注释)构建更全面的混杂因子集合,将TAPB推广至其他任务,如药物-靶标亲和力预测、药物疾病预测等;
研究最优调整集选择(包括基于不同特征构建的集合),寻求在特定数据集和模型架构下的最优调整策略。
参考资料
Lin, G., Zhang, X., Ren, Z. et al. TAPB: an interventional debiasing framework for alleviating target prior bias in drug-target interaction prediction. Nat Commun (2025).
https://doi.org/10.1038/s41467-025-66915-1
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢