
简要总结: 经过五年的持续开发,huggingface_hub 发布 v1.0 正式版!这一里程碑标志着这个库的成熟与稳定。它已成为 Python 生态中支撑 20 万个依赖库 的核心组件,并提供访问超过 200 万公开模型、50 万公开数据集 和 100 万 Space 应用 的基础能力。本次更新包含为支持未来十年开源机器学习生态而做出的重大变更,由近 300 位贡献者和数百万用户共同推动发展。
🚀 强烈建议尽快升级至 v1.0,以体验更优性能和全新功能。
pip install --upgrade huggingface_hub
此次重大版本更新包括以下内容:
使用 httpx作为新后端请求库;全新设计的 hf命令行工具 (取代已弃用的huggingface-cli) ,采用 Typer 构建,功能更加丰富;文件传输全面迁移至 hf_xet,彻底淘汰旧的hf_transfer工具。
查看完整的
v1.0 发布说明 https://github.com/huggingface/huggingface_hub/releases/tag/v1.0.0
issue https://github.com/huggingface/huggingface_hub/issues/3340
每个主流库背后都有一段故事。huggingface_hub 的故事始于一个简单的想法:如果共享机器学习模型像在 GitHub 上分享代码一样容易,会怎样?
在 Hugging Face Hub 的早期阶段,研究人员和开发者常常面临一个困扰: 训练一个先进的模型不仅耗时、耗资源,而且在训练完成后,模型往往“被困”在个人电脑里,只能通过不稳定的 Google Drive 链接进行分享。 这导致社区重复造轮子,资源浪费严重,协作效率极低。
为了解决这一问题,Hugging Face Hub 应运而生。最初,它的功能很简单,只是用于共享和托管与 transformers 库兼容的模型检查点。而与 Hub 交互的全部 Python 逻辑代码,也都内置在 transformers 库中,其他库无法复用这些功能。
直到 2020 年底,我们推出了 huggingface_hub 的首个版本transformers 库中的内部逻辑独立出来,构建一个专用库,用于统一访问和共享 Hugging Face Hub 上的机器学习模型与数据集。最早的版本非常简洁,它只是一个 Git 操作的封装工具,用于下载文件和管理仓库。但五年过去,历经 35+ 个版本迭代,huggingface_hub 已远远超越最初的设想。
v0.0.1 https://github.com/huggingface/huggingface_hub/releases/tag/v0.0.1
让我们一起来回顾这段发展历程。

最初的几个版本为整个库打下了基础。 版本
0.0.8 https://github.com/huggingface/huggingface_hub/releases/tag/v0.0.8 0.0.17 https://github.com/huggingface/huggingface_hub/releases/tag/v0.0.17
2022 年 6 月,版本
从此,用户无需再安装 Git 和 Git LFS,也能直接通过 HTTP 上传文件。新推出的 create_commit() API 极大简化了上传流程,尤其适合处理大型模型文件——这些文件过去通过 Git LFS 操作起来十分繁琐。
此外,该版本还引入了支持 Git 结构感知的缓存机制。所有使用 huggingface_hub 的库 (无论是官方的 transformers,还是第三方库) 现在都能共享同一套缓存系统,具备显式的版本控制和文件去重功能。
这不仅仅是一次技术优化,更是一次理念上的飞跃。 我们不再只是为 transformers 构建 Git 工具,而是在构建一套专为机器学习模型和数据打造的基础设施,面向整个机器学习生态服务。
随着 Hugging Face Hub 从一个模型仓库逐步发展为一个完整的平台,huggingface_hub 的 API 能力也不断拓展,满足更多场景需求。
核心的仓库操作功能不断成熟,支持:
列出文件树 (list tree) 浏览引用 (refs) 与提交记录 (commits) 读取文件或同步整个文件夹 管理标签、分支和发布周期 (release cycle) 查询仓库元数据与设置 webhook,帮助团队实时响应变更
与此同时,Hub 上的huggingface_hub 也逐步实现了对 Spaces 的完整程序化管理能力,包括硬件资源申请、环境配置、密钥管理、文件上传等。
Spaces https://hf.co/docs/huggingface_hub/guides/manage-spaces
为了支持模型在生产环境中的部署,我们还集成了
Inference Endpoints https://hf.co/docs/huggingface_hub/guides/inference_endpoints Jobs API https://hf.co/docs/huggingface_hub/guides/jobs
在此过程中,社区与社交层也被提升为一等公民。现在支持:
创建和管理 Pull Requests 和评论 查询用户与组织信息 仓库点赞、关注、粉丝功能 使用 Collections 整理和分享资源合集
Pull Requests 和评论 https://hf.co/docs/huggingface_hub/guides/community Collections https://hf.co/docs/huggingface_hub/guides/collections
同时,日常使用体验也得到了显著优化:Colab 中的无缝认证、大型文件夹上传的可靠性提升、支持断点续传等功能,使开发更加高效流畅。
随后,在版本
v0.28.0 https://github.com/huggingface/huggingface_hub/releases/tag/v0.28.0 推理服务提供方生态 https://hf.co/docs/huggingface_hub/guides/inference
在版本
v0.30.0 https://github.com/huggingface/huggingface_hub/releases/tag/v0.30.0
与传统的 Git LFS (只支持文件级去重) 不同,Xet 在更精细的粒度 (每 64KB 为一块) 进行数据去重与传输优化。当你更新一个大型模型或数据文件时,系统只会上传或下载发生变更的部分,而不是整个文件。
这场
大规模迁移 https://hf.co/spaces/jsulz/ready-xet-go
一年后,超过 6,000,000 个仓库、77PB+ 的数据已成功迁移至 Xet 后端,带来了更快、更智能的上传与下载体验 🔥
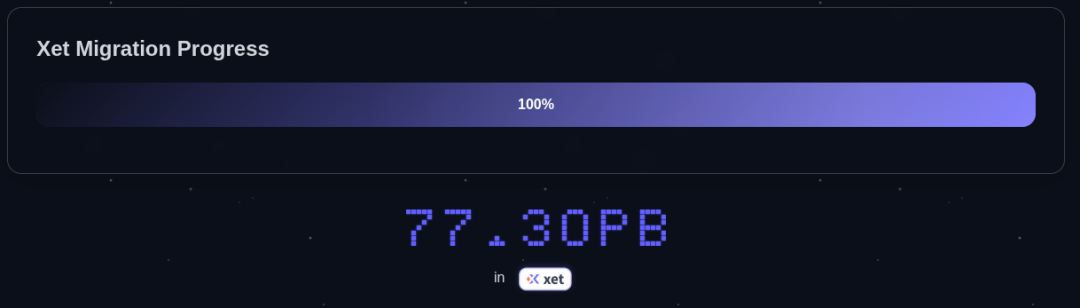
衡量一个开源库的成长和影响力并不容易,但有时,数字本身就是最好的证明:
每月下载量达 1.135 亿次,累计下载超 16 亿次 (截至 2025 年 10 月) 提供访问 200 万+ 公共模型、50 万+ 公共数据集 和 100 万+ 公共 Spaces —— 如果包括私有仓库,总量大约翻倍 每日活跃用户超过 6 万人,每月活跃用户超过 55 万人 被全球 20 万+ 企业 信赖使用,从初创公司到《财富》500 强企业
但真正体现其规模的,是整个生态的广度和深度。huggingface_hub 已成为 GitHub 上 超过 20 万个仓库 和 PyPI 上 3,000 个软件包 的 依赖核心 ,涵盖主流框架如 Keras、LangChain、PaddleOCR、ChatTTS、YOLO、Google Generative AI、Moshi、NVIDIA NeMo、Open Sora 等,还有无数小型工具与项目。Hugging Face 自家生态 (如 transformers、diffusers、datasets、sentence-transformers、gradio、peft、trl 等) 也都建立在其之上。
最令人欣慰的是,这些第三方集成大多数都是自然发生的,我们并未主动推动。这正是 Hugging Face Hub 释放力量的体现——它让整个机器学习社区能够更加开放、高效地协作与创新,而它如今的广泛使用程度,也远超我们的最初预期。
v1.0 不只是一个版本号的跃迁,它代表的是:为未来十年开放式机器学习奠定坚实基础。我们做出的破坏性更新并非随意为之,而是出于战略考虑,为了让 huggingface_hub 能够应对 AI 的高速发展,并保持全球数百万开发者所依赖的稳定性与可靠性。
v1.0 最重要的架构变更,是将底层 HTTP 请求库从 requests 迁移至
httpx https://www.python-httpx.org/
为什么选择 httpx?它带来的好处非常显著:
原生支持 HTTP/2,连接效率更高 完整的线程安全,可在多线程间安全复用连接 最关键的是:提供统一的同步与异步接口,彻底消除原先同步与异步推理客户端之间的微妙差异
此次迁移的设计尽可能做到“对用户透明”,大多数用户无需做任何修改。对于使用自定义 HTTP 后端的开发者,我们提供了清晰的迁移路径,将 configure_http_backend() 替换为 set_client_factory() 或 set_async_client_factory()。
同时,hf_xet 现已成为 Hub 上传和下载文件的默认工具包,完全取代此前的可选方案 hf_transfer,后者已被彻底移除。
在
v0.32.0 https://github.com/huggingface/huggingface_hub/releases/tag/v0.32.0
tiny-agents CLI 工具则允许你直接从 Hub 启动 Agent。你可以连接本地或远程 MCP 服务器,将任意 Gradio Space 用作工具,并构建出自然、流畅、响应迅速的对话式智能体。
MCPClient https://hf.co/docs/huggingface_hub/package_reference/mcp
所有这些,都是在我们现有的 InferenceClient 以及其支持的多家推理服务商的基础上构建的。我们坚信 Agent 是未来,而 huggingface_hub 将持续提供这些构建 AI 工具的基础模块,助力开发者快速落地创新想法。
Hugging Face 的 CLI 工具已经从一个简单的命令行工具,发展为一个 功能全面的机器学习操作接口。全新设计的 hf 命令取代了老旧的 huggingface-cli,采用现代化的“资源-动作”模式:
hf auth login:用户认证hf download和hf upload:文件上传与下载hf repo:仓库管理hf cache ls和hf cache rm:缓存管理hf jobs run:运行云端计算任务
CLI 提供了
沙箱式安装器 https://hf.co/docs/huggingface_hub/installation#install-the-hugging-face-cli
# macOS 或 Linux
curl -LsSf https://hf.co/cli/install.sh | sh
# Windows
powershell -ExecutionPolicy ByPass -c "irm https://hf.co/cli/install.ps1 | iex"
CLI 还支持命令自动补全,并在各大主流平台上都能顺利运行。如今的 Hugging Face CLI,已经具备与现代开发工具媲美的体验和易用性。
在 v1.0 中,我们移除了部分阻碍未来发展的旧功能和用法:
基于 Git 的 Repository类已被移除。HTTP 接口如 upload_file()和create_commit()变得更简洁、更稳定,也更适应现代化工作流。HfFolder的 token 管理方式已被显式的login()、logout()和get_token()函数所取代,使用方式更直观。原有的 InferenceApi类被功能更完善的InferenceClient替代。文件传输工具 hf_transfer被彻底淘汰,现已由全新的二进制工具包hf_xet完全接管。
这些变更并非仓促决策,我们在数月前就已发布弃用通知,附带清晰的迁移指引。最终目标是打造一个 更清晰、更易维护 的代码库,让我们能够集中精力开发面向未来的新特性,而不是继续兼容过时的实现方式。
我们理解,破坏性更新可能会对现有项目造成困扰。正因如此,我们投入了大量精力,尽可能让迁移过程顺畅无痛。官方的
迁移指南 https://hf.co/docs/huggingface_hub/concepts/migration
最重要的是,我们在可能的地方 保留了向后兼容性。例如 HfHubHttpError 同时继承了旧版 requests 和新版 httpx 的 HTTPError 异常类,确保原有错误处理逻辑依然生效。
从 v1.0 起,我们将全面聚焦新版的开发与维护,确保为社区提供更高性能、更丰富功能和更完善的工具。旧版 (v0.*) 仍可在 PyPI 下载,但今后只会进行安全性补丁更新,不再添加新功能。
兼容性汇总表 https://github.com/huggingface/huggingface_hub/issues/3340
感谢 280 多位为本库贡献代码、文档、翻译和社区支持的开发者们!
同时也感谢 Hugging Face 社区提供的反馈、Bug 报告与建议,这些都帮助我们不断完善产品。
最后,衷心感谢广大用户 —— 无论是独立开发者还是大型企业 —— 感谢你们信任 huggingface_hub,让它成为你们工作流程的一部分。是你们的支持激励我们不断前行。
如果你喜欢这个项目,欢迎到
GitHub 点个星 ⭐ https://github.com/huggingface/huggingface_hub
五年已过,但一切才刚刚开始!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢