

报告主题:NeurIPS 2025 Best Paper Runner-up Award|可验证奖励强化学习:拓展大语言模型推理的新路径
报告日期:12月16日(周二)10:30-11:30
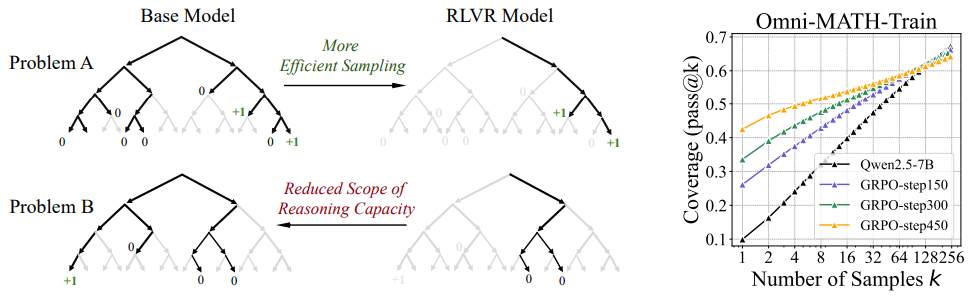
随着大型语言模型(LLMs)在数学、代码等高阶推理任务中表现日益卓越,人们寄希望于强化学习(尤其是基于可验证奖励的RLVR)进一步突破模型的推理能力边界。本次talk将聚焦对当前RLVR范式进行系统性反思,并探讨下一代范式的可能方向。首先,我们将介绍论文Limit-of-RLVR: Does ReinforcementLearning Really Incentivize Reasoning Capacity inLLMs Beyond the Base Model?,其通过系统评测发现:在当前“固定任务分布+结果奖励”的训练范式下,RLVR虽然在评估上表现优异,但很少实质性拓展模型的推理边界,其能力始终受限于base model的覆盖范围。RLVR主要作用体现在提升采样效率而非挖掘新的知识,多个主流RLVR算法在挖掘模型潜能上表现趋同且远未最优。基于此,我们将讨论潜在的原因和可能的范式变革。
✍️ 共同一作&本期TALK主讲人:乐洋
🏆 论文荣获 NeurIPS 2025 Best Paper Runner-up Award

扫码报名
更多热门报告


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢