报告主题:NeurIPS 2025 最佳论文|大语言模型、预训练、机制可解释性Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free报告日期:12月17日(周三)10:30-11:30
报告要点:
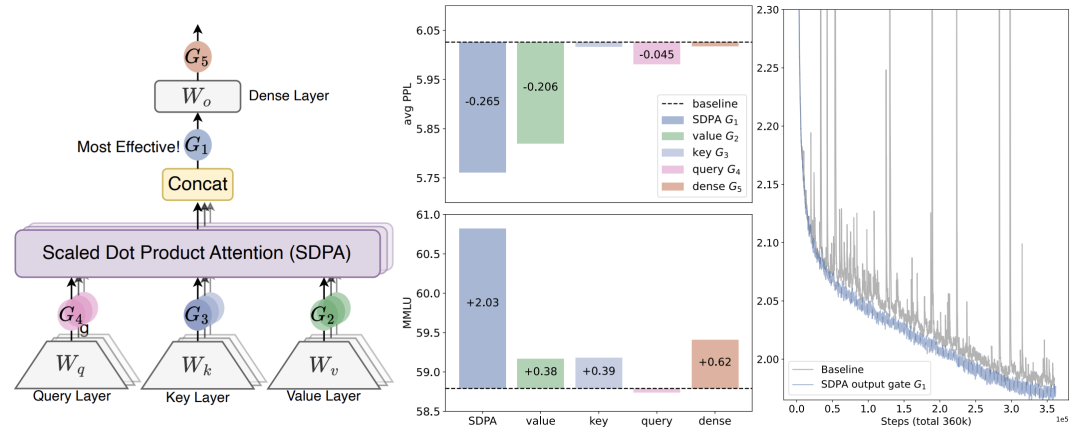
研究团队系统性地分析了门控机制对大语言模型的有效性,并通过一系列控制实验证明了门控机制的有效性来源于增强了注意力机制中的非线性与提供输入相关的稀疏性。此外团队还进一步发现了门控机制能消除注意力池(Attention Sink)和巨量激活(Massive Activation)等现象,提高模型的训练稳定性,极大程度减少了训练过程中的损失波动(loss spike)。得益于门控机制对注意力的精细控制,模型在长度外推上相比基线得到了显著的提升。团队在各个尺寸、架构、训练数据规模上验证了方法的有效性,并最终成功运用到了 Qwen3-Next 模型中。🏆 论文荣获 NeurIPS 2025 Best Paper
邱子涵本科毕业于清华大学姚班,现就职于通义千问(Qwen)预训练团队,专注于大模型架构与训练策略研究。已在 NeurIPS、ICLR、ACL、EMNLP、NAACL 等会议发表十余篇论文,其中一作论文荣获 NeurIPS 2025 最佳论文奖和 NAACL 2024 杰出论文奖。作为核心成员参与 Qwen2.5、Qwen3、Qwen3-Next 等系列模型的研发,Google Scholar 引用量逾 5000。扫码报名
更多热门报告
内容中包含的图片若涉及版权问题,请及时与我们联系删除







评论
沙发等你来抢