


Digital Discovery 是英国皇家化学会 2021 年推出的新刊,开领域之先河,乘自动化与数字化科研技术之东风,致力于成为数据驱动型科研成果的高质量发表平台。
本期推文隆重介绍 2025 年诺贝尔化学奖共同获得者、美国加州大学伯克利分校 Omar M. Yaghi 教授与团队成员在 Digital Discovery 期刊 2025 年 10 月号上发表的封面论文;作者们系统地评估了 GPT-4、Claude 和 Gemini 这三大主流大语言模型在提取金属有机框架 (MOF) 材料研究论文中的相关信息方面的表现。



Comparison of LLMs in extracting synthesis conditions and generating Q&A datasets for metal–organic frameworks
Yuang Shi, Nakul Rampal, Chengbin Zhao, Dongrong Joe Fu, Christian Borgs, Jennifer T. Chayes and Omar M. Yaghi* (加州大学伯克利分校)
Digital Discovery, 2025, 4, 2676-2683
(⬆️ 浏览器中复制打开)
研究简介
以大语言模型 (large language models, LLMs) 为代表的人工智能技术,在自然语言识别与提取方面展现出强大能力。为进一步评估不同 LLMs 从学术论文中提取信息的性能,该研究探索了 LLMs 在网格化学 (reticular chemistry) 领域的应用,重点考察了它们生成问答数据集和从科学文献中提取合成条件的有效性。
被评估的大模型包括
OpenAI 的 GPT-4 Turbo;
Anthropic 的 Claude 3 Opus;
Google 的 Gemini 1.5 Pro。

研究团队设计了严谨的评估体系,通过合成条件提取和问答数据集生成两大任务测试模型性能。
在合成条件提取任务中,研究人员设定了完整性 (completeness)、正确性 (correctness) 和表征参数识别成功性 (characterization-free compliance) 三项关键指标,其中“表征参数识别成功性”考察的是大语言模型是否未将表征时的条件参数错误地识别为合成条件参数;
在问答生成任务中,则重点关注准确性 (accuracy) 和接地性 (groundedness) 指标,其中“接地性”是指大语言模型是否根据所提供的文献回答了问题(还是脱离所给文献而是依据常识或幻觉回答问题)。
在合成条件提取方面,Claude 以 83.5% 的完整性得分领先,能够全面捕捉合成条件细节;而 Gemini 在准确性 (95.7%) 和无表征数据合规性 (同样为 95.7%) 上表现最佳。
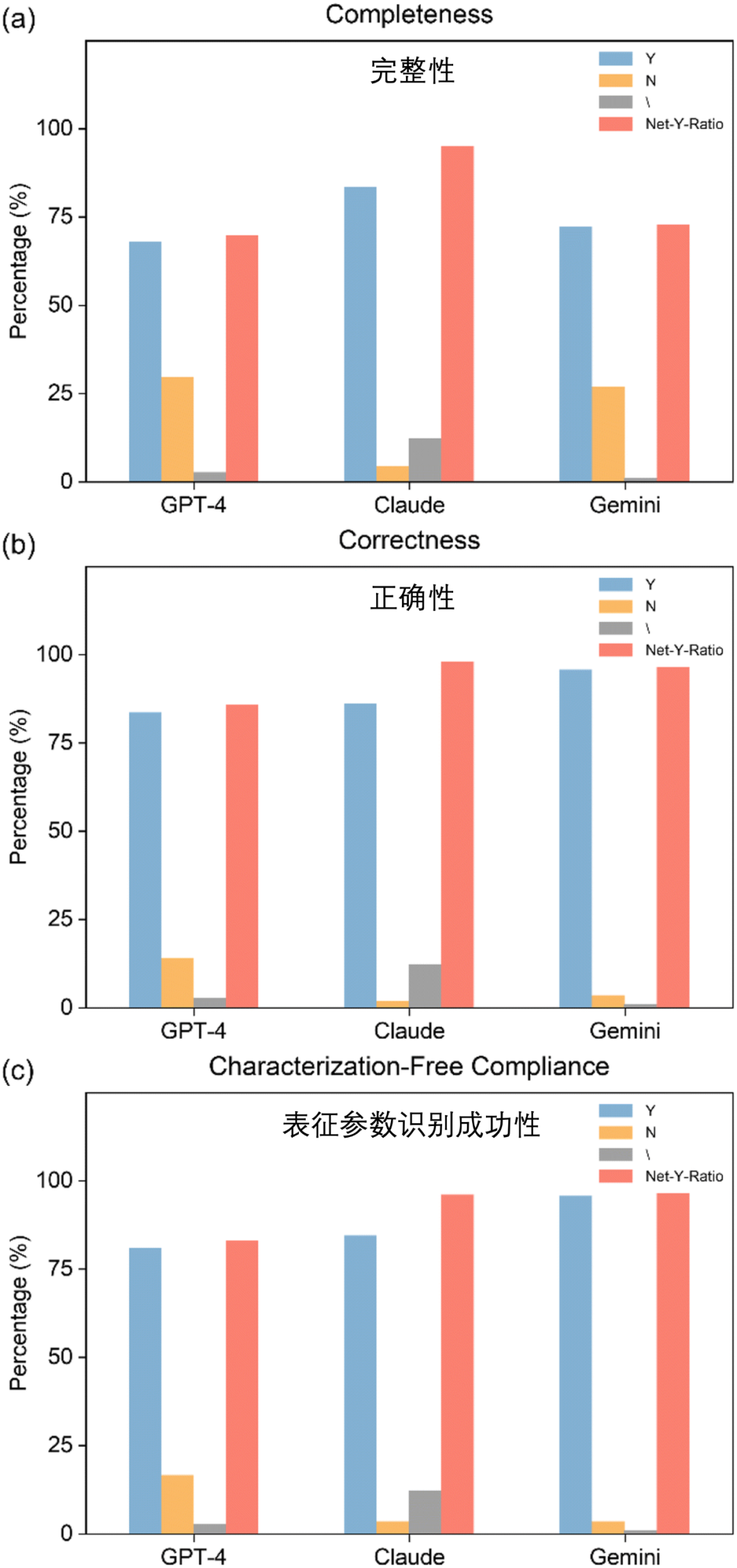
三款大语言模型 (LLMs) 在合成条件提取任务中的表现。(a) GPT-4;(b) Claude;(c) Gemini。“Y”表示成功提取信息并满足相应要求的结果百分比;“N”表示提取了信息但未能满足要求的结果百分比;“\”表示未提取合成条件的结果百分比;“Net-Y-Ratio”是Y除以(Y+N) 的计算值。
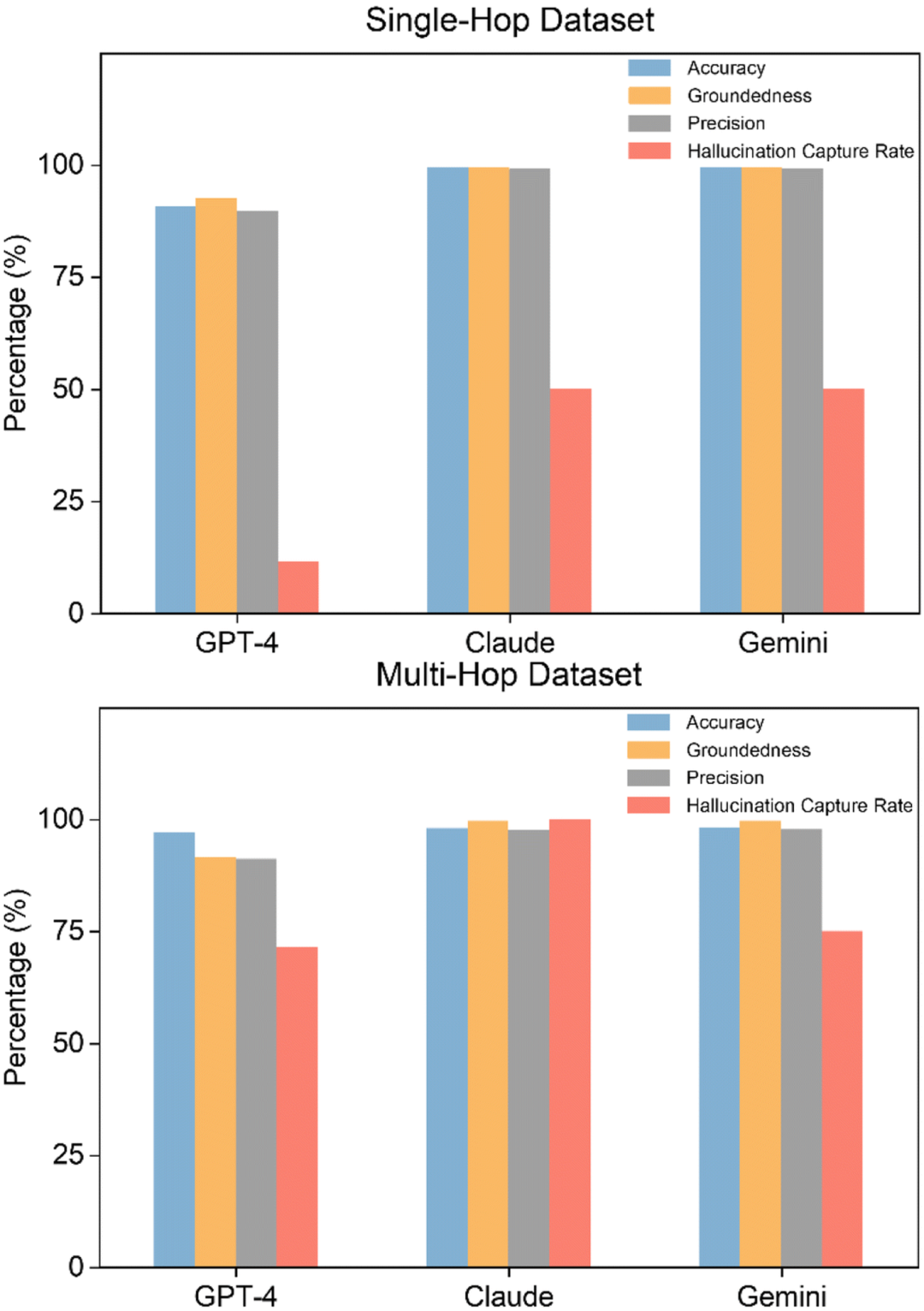
在单跳 (single-hop) 问答生成任务中,Gemini 和 Claude 的准确性率和接地性率均超过 99%,显著优于 GPT-4。同时,Gemini 和 Claude 的幻觉捕获率 (hullucination capture rate) 均为 50.0%,远超 GPT-4 的 11.4%。
另一方面,GPT-4 的准确性率和接地性率在多跳 (multi-hop) 问答中略有提升,幻觉捕获率则大幅改善。与单跳问答不同,多跳问答需要多个检索步骤来收集支持回答的多个证据片段,这也可能是 GPT-4 表现变好的原因所在。
此外,Gemini 还展现出优秀的自主结构化能力,能够主动对问题进行分类编号,极大提升了数据集的可用性。
研究中记录的多个“amazing”结果案例充分展示了 LLMs 的潜力。特别地,尽管 GPT-4 在上述定量指标上效果稍逊,但却在一些案例中展现出强大的逻辑推理和上下文推断能力。

GPT-4 的“amazing”回复一例。原本略去了 1@Y 的合成过程(描述为与 1 一致),GPT-4 成功根据上下文推理,补全了文献中未明确表述的的 1@Y 合成条件。

Claude 的“amazing”回复一例。其准确地识别出文献中描述的六次 DMF 洗涤过程。

Gemini 的“amazing”回复一例,其给出了 linker 的合成条件。作者们在提示词中明确要求给出每一种材料的合成条件,但 GPT-4 和 Claude 还是仅总结了 MOFs 的合成条件。
研究同时揭示了 LLMs 在处理数值信息时的普遍困难,包括试剂用量、温度等数据的提取准确性有待提升。

GTP-4 的完整性错误实例,所给出的答案未包含 bmtte 和 CuBr₂ 的用量。

Claude 的正确性错误实例,所给出的答案错误地将常规溶剂合成条件给出为液-液扩散。

Gemini 的正确性错误实例,所给出的答案错误地将 DMF-H₂O 混合溶剂 (v/v=1/1, 1ml) 给出为 1 ml DMF 加上 1 ml H₂O。
作者们在讨论中指出,试剂和产品名称在合成描述中通常只出现一次,这种单一性使LLMs能够准确存储而不产生混淆。相反,数值数据(如温度、浓度等)往往在多个上下文场景中重复出现,且可能带有细微差异。当相似数值数据在不同上下文中重复出现时,LLMs 的存储机制可能出现信息覆盖现象。这种“交叉污染”导致模型难以区分哪些数值属于哪个特定实验条件。这种认知不仅能帮助改进 LLMs 在科学领域的应用效果,也为优化化学信息学数据库的设计提供了重要指导。

总结而言,这些发现揭示了 LLMs 辅助科学研究的潜力,特别是在高效构建结构化数据集方面,有助于训练模型、预测并辅助新型金属有机框架 (MOFs) 材料的合成。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢