

报告主题:世界模型「空间超感知」新范式 Cambrian-S
报告日期:12月24日(周三)10:30-11:30
本期报告将由纽约大学杨澍生进行分享。
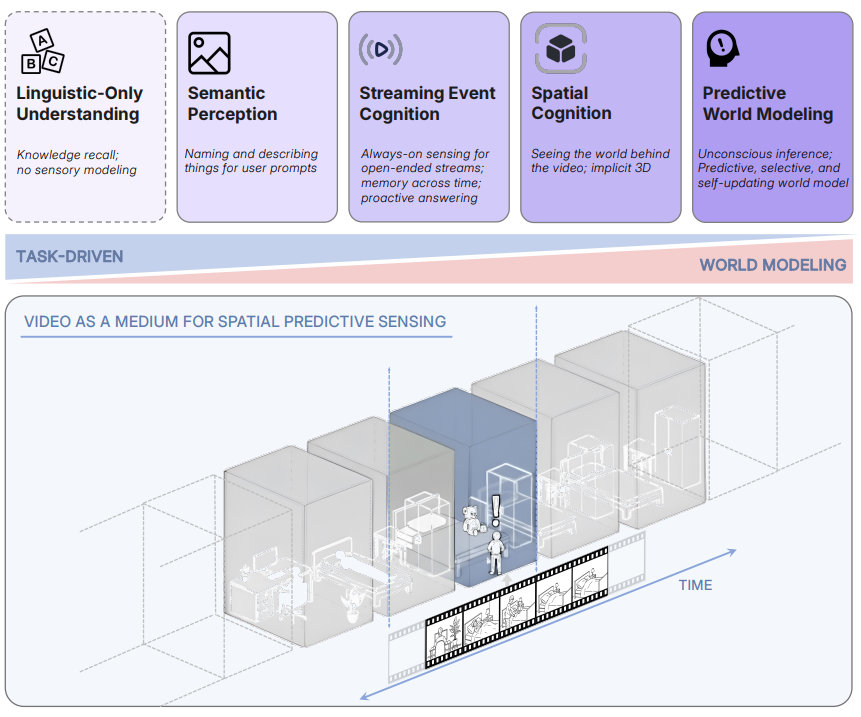
本研究旨在为多模态大语言模型(MLLM)的“空间超感知”能力建立评估基准。我们首先通过诊断实验分析现有视频问答基准,发现它们主要依赖语言先验或浅层视觉感知,缺乏对高级时空推理的深入考察。为此,研究提出了新基准VSI-SUPER,包含长时空间回忆(VSR)与持续计数(VSC)两项任务,要求模型在任意长的流式视频中进行连贯的空间信息积累与推理。实验显示,即使先进模型(如Gemini-2.5-Flash),在此类任务上也表现有限,暴露出现有MLLM范式在计算效率、泛化能力和预测性认知方面的不足。
研究进一步提出“预测感知”(predictive sensing)新范式,通过自监督的下一帧潜在特征预测来量化场景“惊讶度”(surprise),并以此驱动事件分割与记忆管理。案例表明,该方法能提升模型在VSC等任务中的表现,为构建具备内部世界模型、能适应无限视觉流的下一代MLLM提供了方向。

扫码报名
更多热门报告


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢