
在基于图像的药物发现中,准确捕捉细胞对化学扰动的表型响应,对于理解药物作用机制和预测疗效至关重要。然而,现有方法往往依赖复杂的多步骤流程,计算开销大且容易出错。
针对这一问题,澳门大学联合佛罗里达大学等机构的研究团队于2025年12月14日在《Nature Communications》上发表研究论文,题为“PhenoProfiler: advancing phenotypic learning for image-based drug discovery”。

该研究提出的PhenoProfiler采用高效的端到端深度学习框架,将内容丰富、多通道的细胞图像直接映射为低维定量表征。基于近40万张高内容图像和842万张单细胞图像的评估结果显示,PhenoProfiler在准确性和稳健性上均显著优于现有最先进方法,性能提升最高可达20%。其定制化的表型校正策略进一步强化了处理诱导的细胞变化,从而增强了对生物学意义明确且可重复信号的检测能力。通过有效解决现有方法在流程复杂性、计算成本及泛化能力方面的局限,PhenoProfiler显著推进了表型分析,为加速基于图像的药物发现提供了有力工具。
PhenoProfiler访问链接:
https://phenoprofiler.org
背景
在基于图像的药物发现中,学习稳健的图像表示对于从复杂的高通量图像数据集中提取有意义的信息至关重要。Cell Painting技术通过多种荧光染料标记细胞内不同的细胞器和组成部分,生成多通道图像,从而捕捉细胞对不同药物或扰动的表型变化。然而,Cell Painting图像的高维特性常伴随冗余和噪声,因此通常需要大量预处理步骤,如归一化、分割及伪影去除。此外,处理这类大规模数据集对计算资源要求高,而提取的形态学特征可能缺乏生物学可解释性,使得直接利用图像进行有意义的分析具有挑战性。
为应对Cell Painting图像特有的挑战,开发了包括CellProfiler、DeepProfiler、SPACe和OpenPhenom在内的专用方法,以提取细胞形态的紧凑且信息丰富的表示。尽管取得一定进展,现有形态学表示学习方法在处理高维Cell Painting图像时仍存在关键限制。首先,这些方法通常将多通道整图分解为多个子图像进行处理,这种多步骤流程不仅增加了计算开销和成本,还可能引入额外误差,例如分割不准确或特征整合错误。其次,这类方法依赖药物处理条件作为分类标签,但标签信息有限,难以全面捕捉细胞响应的多样性和复杂性。因此,基于有限标签训练的模型在不同实验条件下泛化能力较弱,降低了其可扩展性与适用性。这些局限性凸显了开发简化、高效且具有生物学可解释性的表型表示方法的必要性。
方法
PhenoProfiler能够从高通量图像中学习细胞形态表示,并提取药物处理效应引起的表型变化。与现有方法相比(图1a),PhenoProfiler被设计为端到端模型,可直接将信息量丰富的多通道图像编码为低维特征表示,无需复杂预处理步骤,如图像分割或子图像提取。
PhenoProfiler由三个核心模块组成,即梯度编码器、Transformer编码器以及整合分类、回归和对比学习的多目标学习模块(图1b)。具体而言,梯度编码器用于增强边缘信息,提高细胞形态的清晰度和对比度;随后,Transformer编码器捕捉图像中的高维依赖关系和复杂联系,从而丰富图像表示;多目标学习模块则用于实现精确的形态学表示学习。经过充分训练,PhenoProfiler构建了一个统一且稳健的特征空间,用于表征细胞形态。
在推理阶段(图1c),PhenoProfiler通过表型校正策略强调不同处理条件下的相对表型变化,从而揭示生物学相关性及处理相关的表型表示。
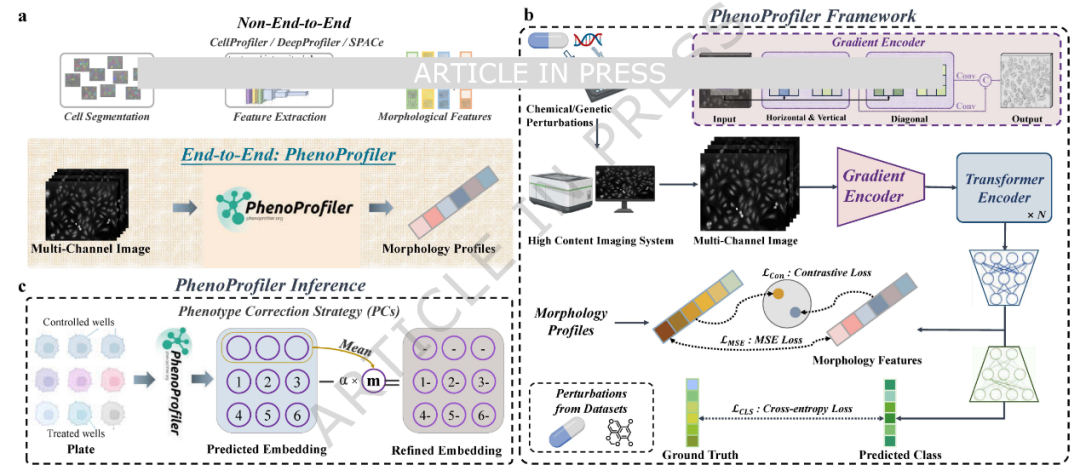
图1 PhenoProfiler框架图
结果
在生物匹配任务中性能
为了对PhenoProfiler进行全面且稳健的评估,将其与已知方法(包括DeepProfiler、OpenPhenom、ResNet50和ViT)进行对比,采用leave-perturbation-out策略。评估采用两个指标,即富集倍数(FoE)和平均精度均值(MAP)。使用三个数据集(BBBC022、CDRP-BIO-BBBC036和TAORF-BBBC037)中的超过23万张图像,涵盖231个板和4285种处理,包括化合物和基因过表达扰动。实验结果如图2所示,PhenoProfiler在三个基准数据集上均在FoE和MAP指标上超越所有竞争方法。
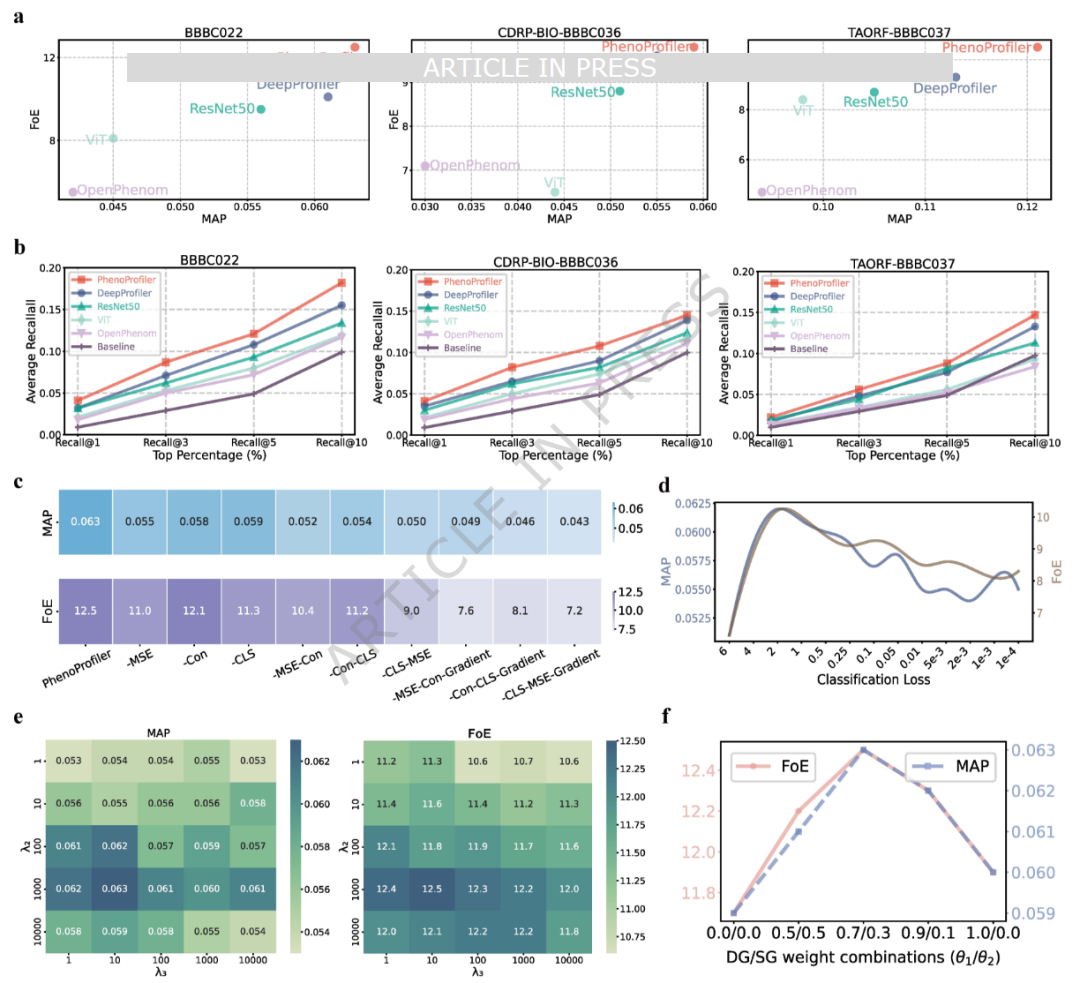
图2 在生物学匹配任务中的性能
为了进一步说明PhenoProfiler各模块的贡献,作者在BBBC022数据集上进行了消融实验(图2c)。首先,去除多目标学习模块中的回归学习组件(“-MSE”选项),仅保留分类和对比学习。结果显示,去除回归学习导致性能显著下降,FoE和MAP分别下降12.0%和12.7%。接着,测试了不同损失函数组合(“-Con”、“-CLS”、“-MSE-Con”、“-Con-CLS”和“-CLS-MSE”)。例如,同时去除回归和分类学习,FoE和MAP分别下降28.0%和20.6%。与未使用梯度编码的模型平均性能(“-MSE-Con-Gradient”、“-Con-CLS-Gradient”、“-CLS-MSE-Gradient”)相比,该修改导致FoE和MAP分别下降25.2%和11.5%,突显了基于梯度的特征编码的有效性。此外,测量指标并非随着分类损失的下降而持续改善。如图2d所示,MAP和FoE在分类损失下降初期有所提升,但最终下降。这强调了PhenoProfiler多目标学习设计的重要性。多目标学习的最优权重通过对BBBC022数据集的敏感性分析确定。图2e-2f显示了调优后的PhenoProfiler实现了最优性能。
泛化能力与适用性
为了评估PhenoProfiler的泛化能力,作者在基准数据集上进行了实验,采用leave-plates-out和leave-dataset-out评估策略。对于leave-plates-out策略,部分板作为测试集,其余板用于训练;而在leave-dataset-out策略中,一个数据集用于训练,另外两个作为测试集。在leave-plates-out 情境下(图3a),PhenoProfiler在FoE和MAP指标上均持续优于其他方法。图3b展示了leave-dataset-out情境下的性能对比,进一步突显了PhenoProfiler的优越表现。总体而言,PhenoProfiler的泛化能力优于现有方法,为药物发现中的下游任务提供了更精准的支持。
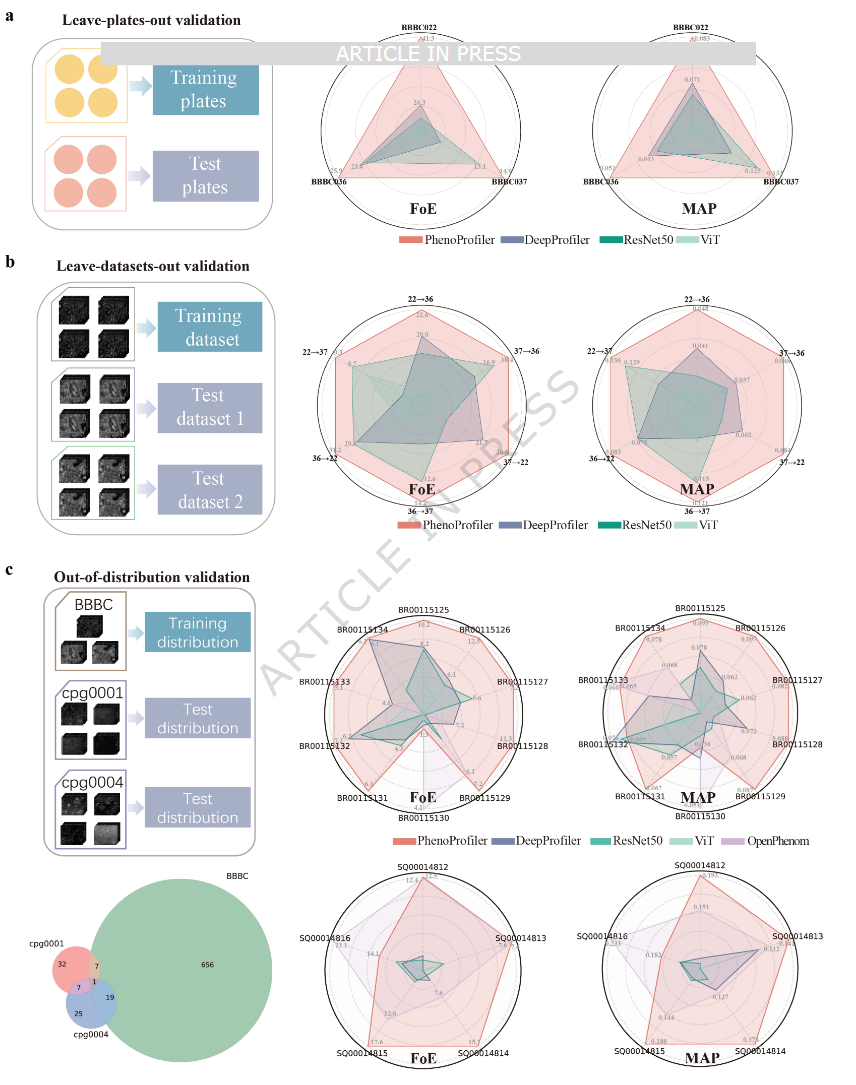
图3 泛化能力及适应性评估结果
为了进一步验证PhenoProfiler的泛化能力,对外部分布(OOD)数据进行了评估,使用来自cpg0001数据集的10个不同板(BR00115125-BR00115134),共76800张图像,涵盖83种独特处理和47个注释的作用机制(MoA)。如图3c上图所示,直接将预训练于BBBC022、BBBC036和BBBC037的PhenoProfiler模型应用于这些OOD板。PhenoProfiler在所有测试板上在FoE和MAP指标上分别比第二优模型DeepProfiler平均高45.8%和27.3%,显示出稳健的泛化能力及对OOD数据的适应性。此外,由于这些评估均来自U2OS细胞系,进一步在五个A549细胞系板(cpg0004数据集中的SQ00014812-SQ00014816,见图3c下图)上进行了评估。结果显示,PhenoProfiler在FoE和MAP上平均分别比第二优模型OpenPhenom高21.4%和20.3%,证明其在不同细胞系间的泛化能力同样稳健。
有效消除批次效应
为评估PhenoProfiler缓解批次效应的能力,作者采用反向绝对中位差(IMAD)指标来量化图像表示的离散程度。IMAD值越高,表示离散性越小,即批次效应被更好地校正。图4展示了板级的表示特征,不同颜色表示不同板,以突出批次效应。PhenoProfiler学到的表示特征分布明显更为整合(IMAD = 0.603),表明其能够在不同板间学习到协调一致的特征,有效解决批次效应,无需额外校正。这一模式在三个数据集中均一致出现,进一步验证了PhenoProfiler在生成稳健表型表示方面的可靠性。PhenoProfiler能够直接从原始数据学习协调一致的表示,不仅减少了计算密集型后处理的需求,同时确保了生物学信号的保留。
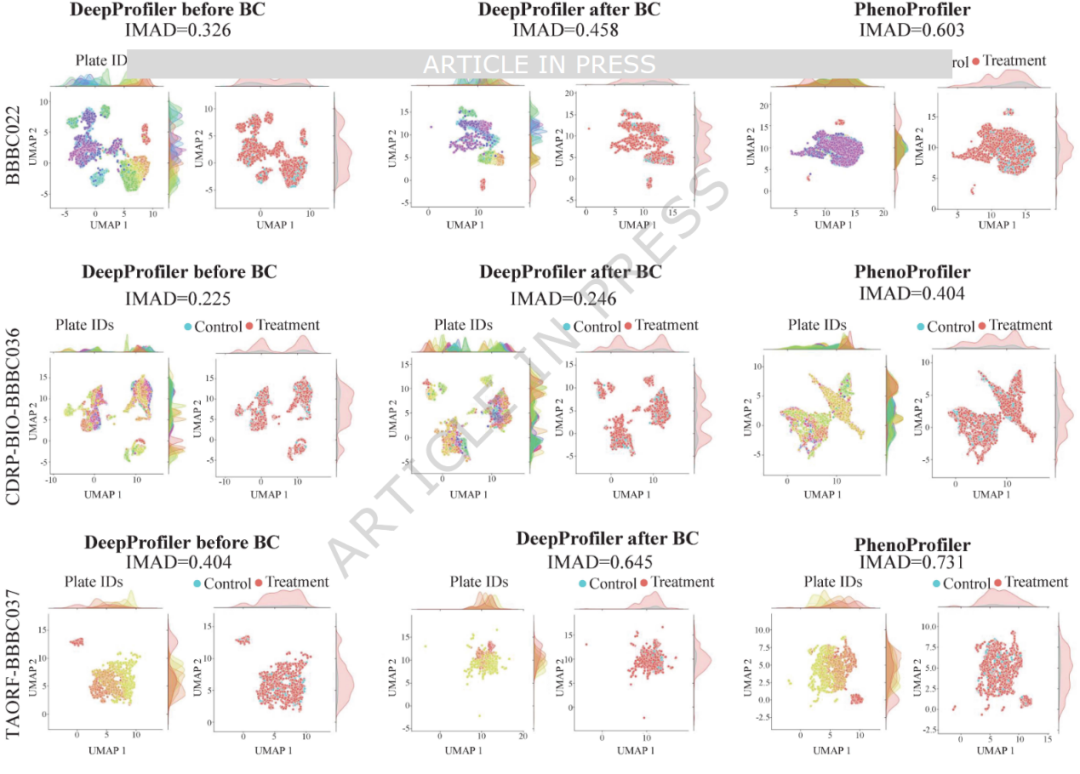
图4 不同方法特征表示的稳健性
表型校正策略提升生物学匹配
为了有效捕捉处理下的相对变化,PhenoProfiler特别设计了表型校正策略(PCs)用于优化学习到的表型表示。如图5a所示,PhenoProfiler通过利用同一板内的对照孔和处理孔,对图像表示进行校正,强调处理下细胞表型的相对变化。通过消融实验评估PCs的影响,结果表明PCs能够稳定提升FoE指标,而对MAP指标影响较小(图5b)。随后分析了在三个基准数据集中引入PCs前后的特征聚合情况。使用UMAP对孔级图像表示进行可视化,并通过IMAD指标定量衡量聚合性(图5d)。实施PCs后,不同板的表示特征显著更加集中,IMAD指标分别在三个基准数据集上显著提高51.5%、69.7%和11.6%,显示了强烈的聚合改善效果。
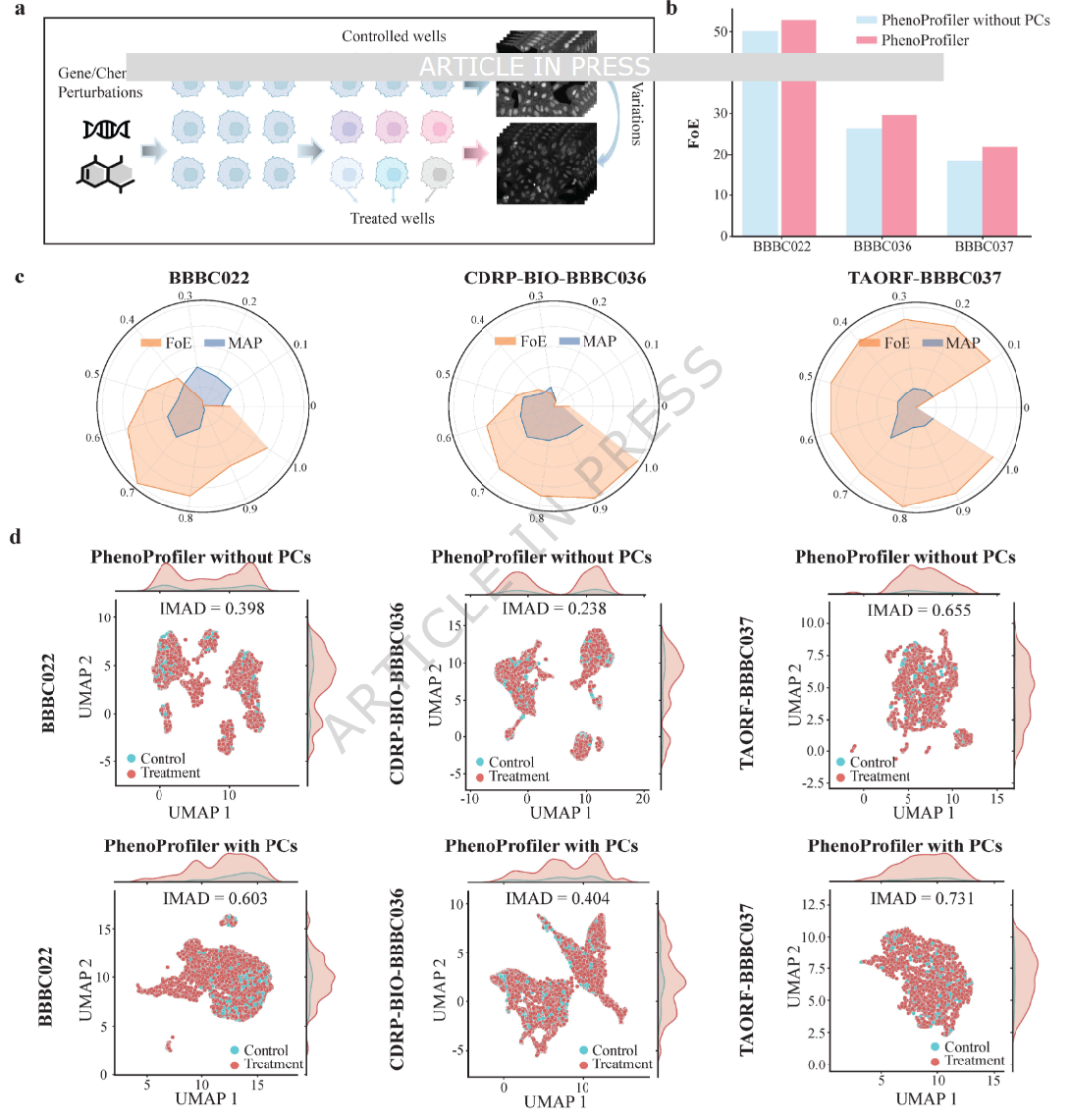
图5 表型校正策略的定量分析
高效捕捉处理效应表示
为了直观展示处理效应,作者使用PhenoProfiler在不同处理条件下获得表型表示。图6展示了PhenoProfiler在三个基准数据集上的UMAP投影,清晰展示了PhenoProfiler在非端到端(图6a)和端到端(图6b)场景下捕捉与组织生物学模式的能力。
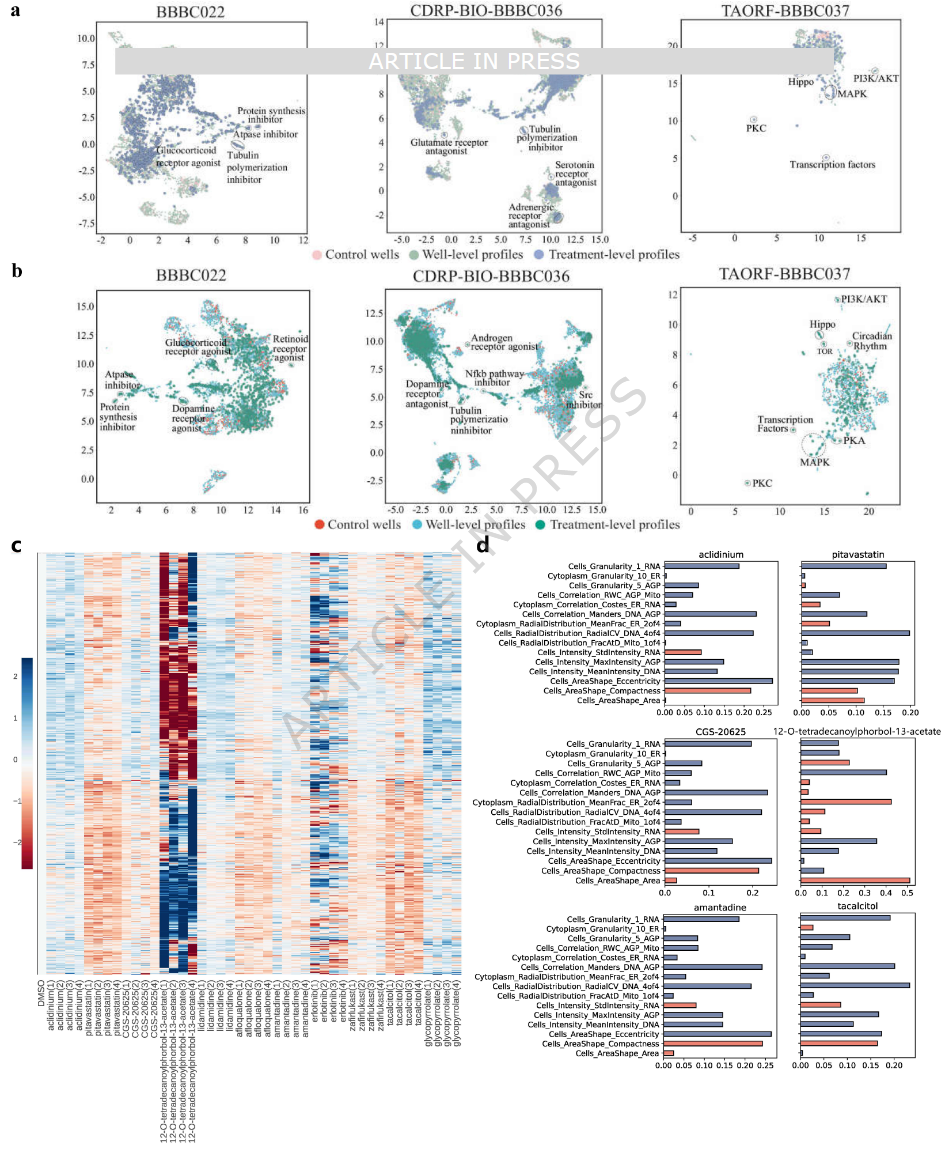
图6 处理效应特征表示的定量与定性评估
为了进一步评估PhenoProfiler在识别具有临床可操作性的表型模式同时保持生物学可解释性的能力,作者使用cpg0004-LINCS数据集进行了深入分析,该数据集包含具有明确MoA的处理。图6c显示,所有药物处理组相较DMSO对照组均表现出显著特征变化。值得注意的是,同一药物类别的四重复孔高度一致,不同药物类别间则明显分离。这些结果验证了PhenoProfiler的双重能力,即敏感检测药物诱导的表型扰动,同时精准区分药理机制。
未来方向
尽管PhenoProfiler在表型表示学习中已树立新标杆,但仍存在多个值得探索和改进的方向。
多目标学习模块优化。未来可进一步研究分类、回归与对比学习目标之间的相互关系及协同效应,理解这些目标间的依赖性可能有助于制定更统一的学习策略。目前,PhenoProfiler 采用分步训练以缓解目标冲突,未来可探索联合训练与优化方法,更高效地平衡各学习目标。
整合大规模生物医学语言模型。近期生物医学大语言模型的进展为将丰富领域知识引入计算框架提供了可能性。将这些模型的嵌入整合到PhenoProfiler中,或可进一步提升模型的泛化能力、稳健性及有效性。
多模态数据整合。未来应优先考虑将遗传信息、转录组数据及化学结构等补充数据整合到分析中。多模态数据融合可生成更全面的表征,有助于从整体上理解细胞状态及其对不同处理条件下的表型响应。
PhenoProfiler能够在多样化数据集和处理条件中持续捕捉并组织复杂生物信息,凸显其在高通量药物筛选和发现中的多功能性和实用性。通过应对表型分析中的关键挑战,如可扩展性、稳健性及可解释性,PhenoProfiler增强了对处理效应在表型层面的理解。此外,其在多模态整合分析中的潜力,将表型数据与遗传信息、转录组及化学结构等信息结合,为深入探索药物作用机制及发现新药靶点提供了新的机会。
参考链接:
https://doi.org/10.1038/s41467-025-67479-w
--------- End ---------
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢