
近年来,蛋白结构预测领域取得了突破性进展,从AlphaFold2到AlphaFold3,深度学习模型不断刷新我们对生命分子结构的认知。然而,一个更深层次的问题逐渐浮现:我们能否从"理解结构"迈向"创造结构"?
字节跳动Seed团队最新推出的SeedProteo,正是对这一问题的系统性回答。这项研究不仅展示了如何将顶尖的折叠架构转化为强大的生成设计框架,更在蛋白从头设计领域树立了新的标杆。

从折叠到生成:架构的巧妙转换
SeedProteo的核心创新在于巧妙地将AlphaFold3的折叠架构重新用于生成设计。研究人员面临一个关键挑战:折叠模型的编码器是基于序列的,但在生成任务中,序列信息是未知的。
团队提出了一个精妙的解决方案:通过引入自条件特征,将噪声坐标转化为1D序列表示,使模型能够在缺乏序列信息的情况下提取内在的几何关系。这种架构转换不仅保留了折叠模型的强大建模能力,还赋予了它创造新蛋白的能力。
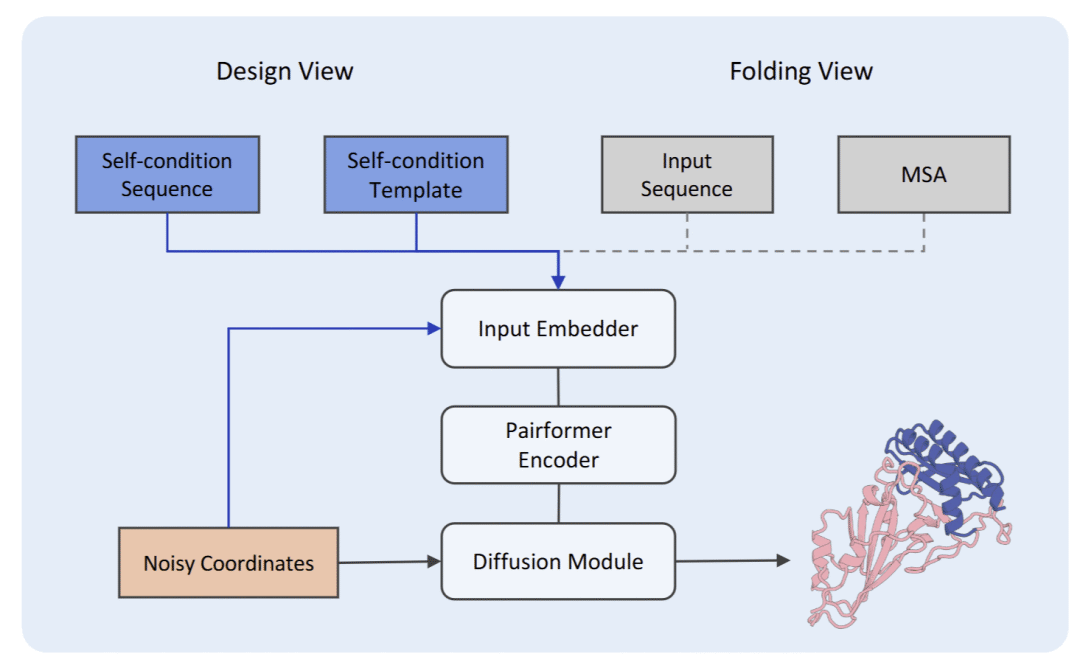
SeedProteo 框架总体概览。
三大核心技术突破
马尔可夫随机场序列解码
传统方法通过原子坐标隐式推断氨基酸类型,容易混淆结构相似的氨基酸。SeedProteo引入全局马尔可夫随机场(MRF)模块,直接建模残基间的高阶耦合关系,确保生成的序列与全局骨架拓扑自洽。
二级结构自条件引导
SeedProteo接受包含三个标准字符(H、E、L)和掩码标记(X)的二级结构序列作为输入。模型能够处理任意生成的二级结构序列,即使是包含未知片段的序列,也能自适应地将其精炼为物理上合理的二级结构。
结构模板自稳定
利用前一步的去噪结构作为结构模板进行自条件,通过将Cβ距离图转换为独热张量作为成对特征,有效稳定了结构采样轨迹。
性能全面领先:从单体生成到结合剂设计
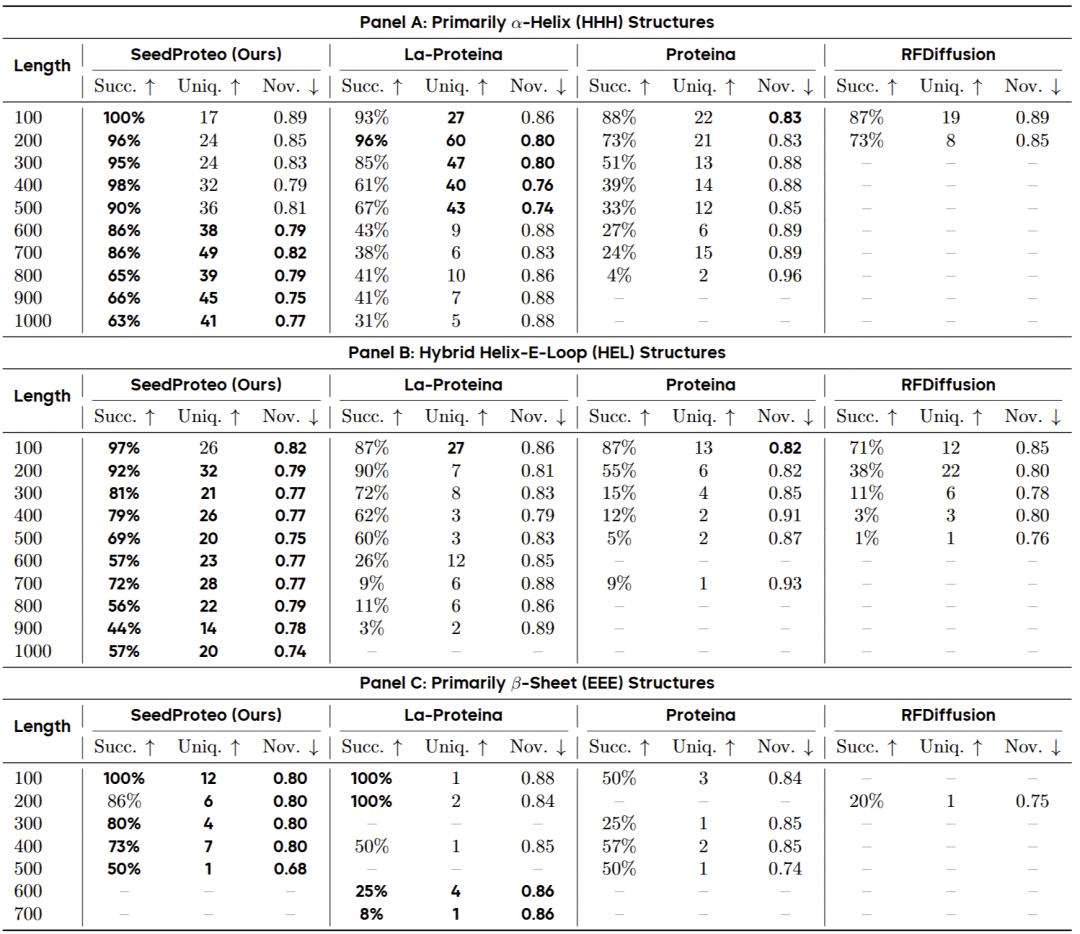
无条件单体生成:长度泛化能力突破
在无条件单体生成任务中,SeedProteo展现了卓越的长度泛化能力。当序列长度达到1000个残基时,SeedProteo仍能保持超过60%的设计成功率,而基线方法在600个残基以上时成功率已降至接近零。
更令人印象深刻的是,SeedProteo在复杂拓扑结构上的表现:
β-折叠结构:在长度500时仍保持50%以上的成功率,而其他方法在此类别中几乎完全失败;
混合拓扑结构:在长度1000时达到57%的成功率,基线方法在600以上已无法生成有效结构;
结构多样性:在所有拓扑类型中均保持最高的结构多样性和新颖性。
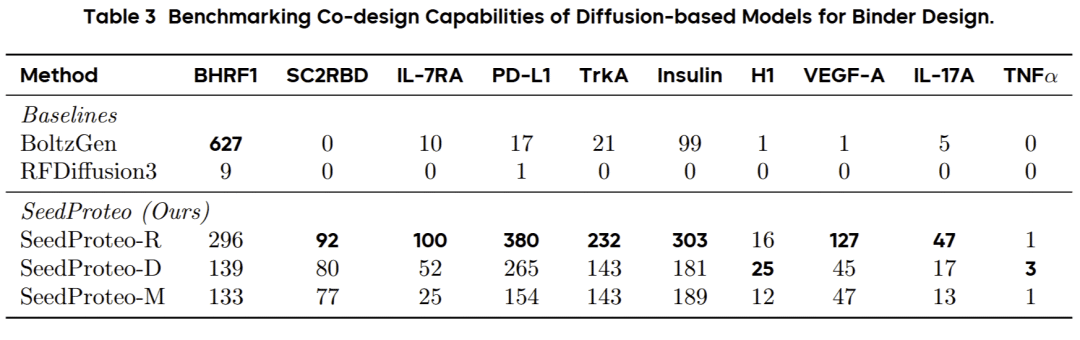
结合剂设计:开源方法的性能巅峰
在10个基准靶蛋白的结合剂设计任务中,SeedProteo展现了全面领先的性能:
两种推理模式平衡设计成功率与多样性:
SeedProteo-R(稳健模式):优先考虑更长的连续二级结构片段,实现更高的设计成功率。
SeedProteo-D(多样模式):允许更频繁的短二级结构片段,促进更复杂的拓扑结构。
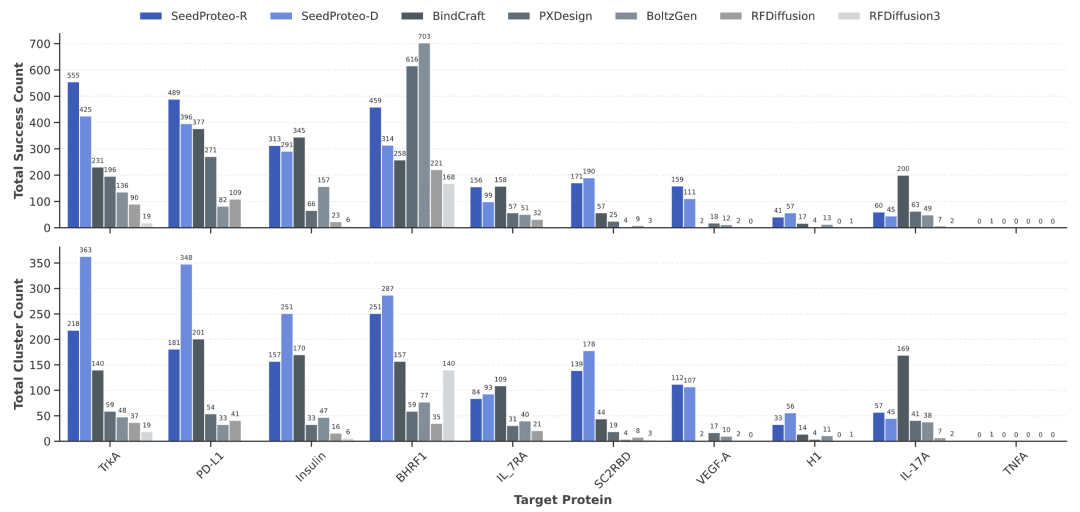
十个靶标蛋白上结合蛋白设计成功率与多样性的比较。基于 SeedFold 的 in silico 指标,对开源方法进行了基准评测。
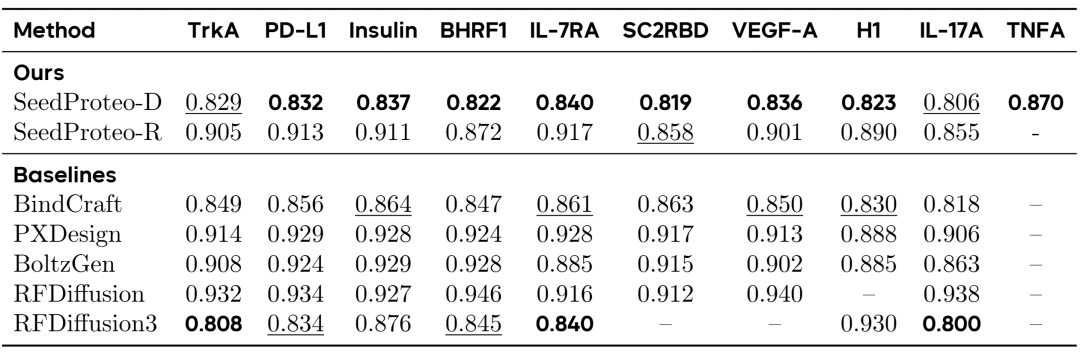
结合蛋白设计基准中的结构新颖性(↓)。
关键性能指标:
设计成功率:SeedProteo-R在总成功数上遥遥领先,特别是在SC2RBD、VEGF-A、H1和TNFα等挑战性靶点上优势明显;
结构多样性:SeedProteo-D在10个靶点中的8个上实现了最高的独特成功簇数;
新颖性:SeedProteo-D在8个靶点上获得了最佳的新颖性分数,维持在0.8范围,而大部分基线方法通常在0.9以上。
共设计策略:
传统两阶段流程(骨架生成后逆折叠)在蛋白设计基准中占据主导地位,但SeedProteo的共设计策略在复杂靶点上展现出潜在优势。
一个典型案例是TNFα靶点:基于ProteinMPNN的方法几乎全部失败(0或1个成功),而SeedProteo的共设计方法能够生成有效的结合剂。这表明逆折叠模型倾向于陷入"安全"的局部最小值,而共设计能够学习更复杂的序列模式,突破结构瓶颈。
意义与展望
SeedProteo的意义不仅在于"又一个更强的蛋白设计模型",而在于它揭示了蛋白生成设计的深层原则:
架构可转换性:顶尖的折叠架构可以有效地重新用于生成任务;
自条件的重要性:通过精心设计的自条件特征,可以显著提升生成质量;
共设计的潜力:同时生成序列和结构的方法在复杂任务上具有独特优势。
这项工作为未来的蛋白基础模型、药物发现和生物技术应用提供了重要参考。随着蛋白设计从"理解自然"迈向"创造自然",SeedProteo展示了一条清晰的技术路径:不仅要更大,还要更统一。

参考资料
https://seedfold.github.io/
https://arxiv.org/abs/2512.24192
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢