

报告主题:Parallel-R1:基于强化学习实现大语言模型并行思考
报告日期:01月09日(周五)10:30-11:30
本期报告将由马里兰大学郑童进行分享。
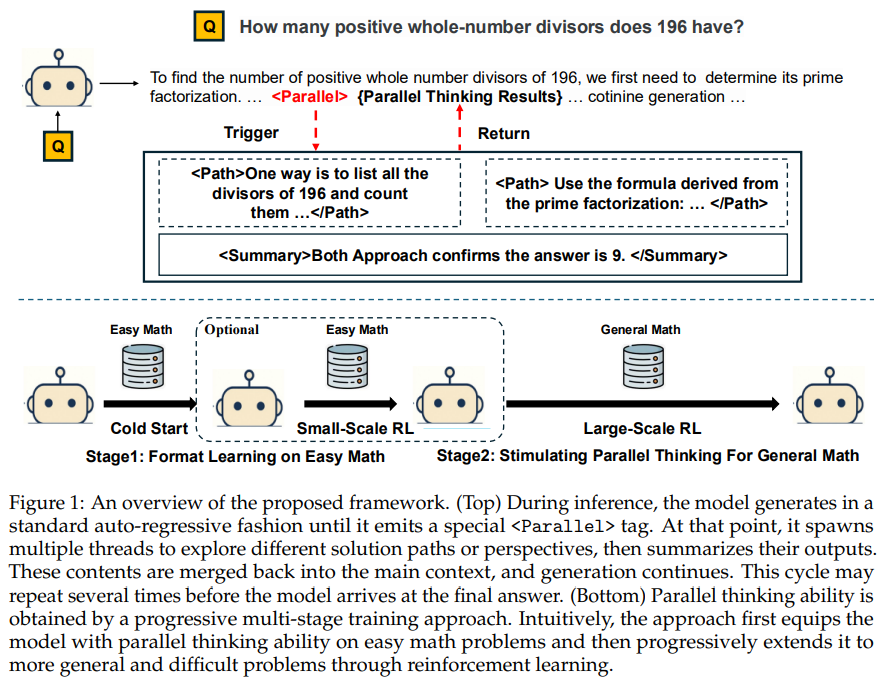
并行思维作为一种新方法,通过同时探索多个推理路径来增强大语言模型(LLMs)的推理能力。然而,目前主要依赖于在合成数据上的监督微调(SFT)来激活这种能力,这种方式鼓励的是强制模仿教师模型的行为,而非探索和泛化能力的培养,因此通过训练实现并行思维仍具有挑战性。与现有方法不同,我们提出了\textbf{Parallel-R1},这是首个用于复杂现实世界推理任务的并行思维强化学习(RL)框架。我们的框架采用了一种渐进式的课程学习策略,明确解决了使用强化学习训练并行思维时面临的冷启动问题。我们首先在较简单任务生成的提示轨迹上进行监督微调,以初步掌握并行思维能力,随后过渡到强化学习阶段,在更具挑战性的问题上进一步探索和拓展这一能力。
在包括MATH、AMC23和AIME在内的多个数学基准测试中进行的实验表明,Parallel-R1成功地培养了并行思维能力,相比直接在复杂任务上使用强化学习训练的顺序思维模型,准确率提升了8.4%。进一步分析显示,模型的思维行为发生了明显转变:在训练初期,并行思维主要作为探索策略被使用;而在后期,则更多地用于从多个角度进行验证。最重要的是,我们将并行思维验证为一种\textbf{中期训练的探索支架},这种临时性的探索阶段在强化学习后期释放出了更高的性能上限,在AIME25上相比基线模型提升了42.9%。我们的模型、数据和代码将开源,地址为 https://github.com/zhengkid/Parallel-R1。

扫码报名
更多热门报告


内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢