


关键词:基于测量的量子计算,分布式量子计算

导 读
本文为 HPCA 2026(IEEE International Symposium on High-Performance Computer Architecture)会议接收论文 DC-MBQC: A Distributed Compilation Framework for Measurement-Based Quantum Computing 的解读。该工作由北京大学计算机学院李彤阳课题组完成。论文第一作者薛烨诚是北京大学计算机学院博士生,合作者包括北京大学计算机学院博士生杨睿以及香港中文大学助理教授梁之鼎博士。
论文提出了首个面向基于测量的量子计算(measurement based quantum computing, MBQC)的分布式编译框架 DC-MBQC。该框架通过自适应图划分与层次调度算法,在多量子处理单元(QPU)系统中实现了计算任务的高效映射,显著降低了对光子寿命的硬件需求,为光量子计算的分布式扩展提供了重要的系统级解决方案。

↑扫码跳转论文
论文地址:
http://arxiv.org/abs/2601.00214
01
问题介绍
当前,量子计算硬件在超导、离子阱、中性原子等多个技术路线上均取得了显著进展。光量子计算凭借其高达 99.7% 以上的保真度和 MHz 级别的时钟频率[1][2],也成为实现容错量子计算极具竞争力的物理平台。与超导、离子阱等采用量子电路模型、通过对静态量子比特执行逻辑门序列来完成计算的平台不同,光子作为“飞行的量子比特”,具有难以长期静止存储、但易于传输和测量的物理特性。
这种特性使得基于测量的量子计算(MBQC)成为了光量子平台最自然、最高效的计算范式。在 MBQC 中,计算不再依赖逻辑门的按序演化,而是通过在动态生成的纠缠态(图态)上进行单量子比特测量来驱动。可以说,MBQC 是光量子硬件扬长避短、发挥性能的最佳拍档。
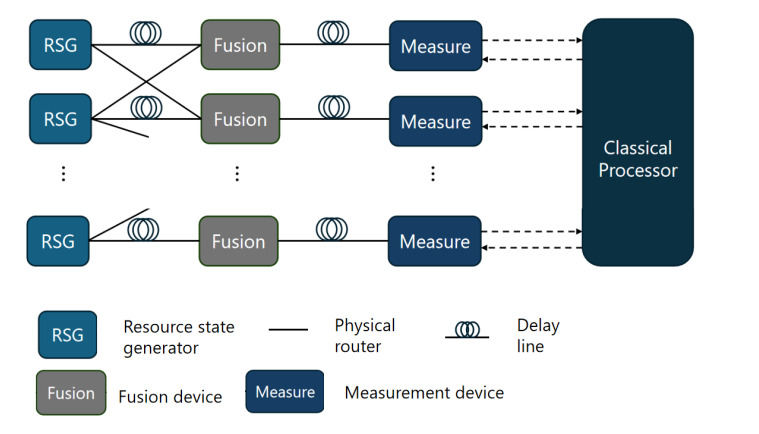
图1. 光量子计算平台上的 MBQC 实现方案。小型图态由资源态生成器(RSG)生成,通过部分光子的聚合(Fusion)操作聚合为大型图态作为计算资源,并通过确定基底(由经典处理器计算)的单量子比特测量驱动计算过程。
尽管 MBQC 完美契合了光子的特性,但在实际系统中,光子仍需在光纤延迟线(Delay Line)中暂存,以等待与其他光子进行同步(如聚合操作)或等待前序测量结果的反馈。这是一个极其严苛的物理限制:随着计算规模的扩大和程序复杂度的提升,光子需要在延迟线中存储的时间(即所需光子寿命)显著增加。由于光纤中的光子丢失率随时间呈指数级上升,过长的存储时间会直接导致计算保真度的崩溃。
分布式量子计算(DQC)是解决扩展性问题的必经之路。然而,MBQC 的计算模式与量子电路模型截然不同,现有的分布式编译器无法直接应用。如何针对 MBQC 模型设计分布式编译框架,有效平衡负载和实现通信同步,是光量子计算迈向大规模扩展的关键难题。
02
主要结果
本文提出了 DC-MBQC,这是首个专为 MBQC 设计的分布式编译框架。该框架以最小化“所需光子寿命”为核心优化目标,系统性地解决了上述挑战。
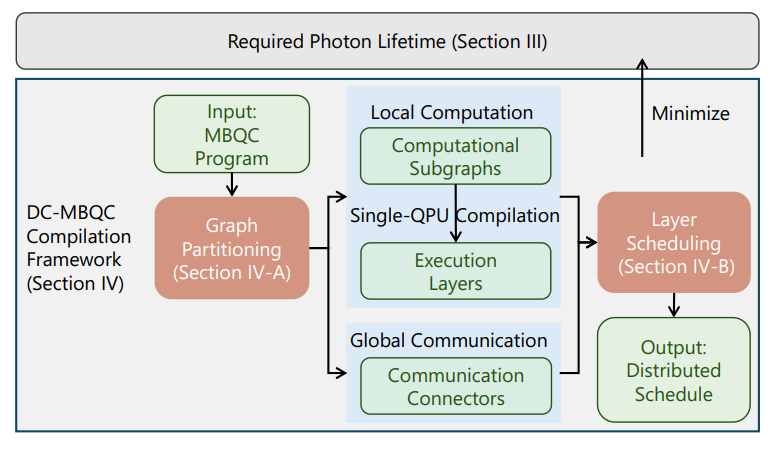
图2. DC-MBQC 框架流程图,包含自适应图划分、单 QPU 编译及层调度三个核心阶段。
核心贡献包括:
1. 提出关键物理指标“所需光子寿命”: 首次将延迟线中的光子存储来源统一量化为“所需光子寿命”,作为评估编译器性能的物理感知指标。
2. 构建 DC-MBQC 分布式编译框架: 提出基于“连接层”的架构抽象,利用时间维度的路由能力实现了单 QPU 编译与全局通信约束的解耦。从而,复杂的 MBQC 分布式编译问题可被解耦为负载划分、通信与同步两方面。进一步地,我们首次将 MBQC 分布式编译的通信同步问题形式化为“层调度”问题并证明了其 HP-hardness,并针对该难题设计并实现了瓶颈驱动的迭代调度算法。
3. 大幅度的性能提升:在 8 个全互连 QPU 的设置下,DC-MBQC 相比于单 QPU 编译器(OneQ[3],OneAdapt[4])展现了显著的分布式优势:所需光子寿命优化 7.46 倍,大幅降低了对延迟线硬件质量的严苛要求;执行速度提升 6.82 倍,极大提高了运行效率。
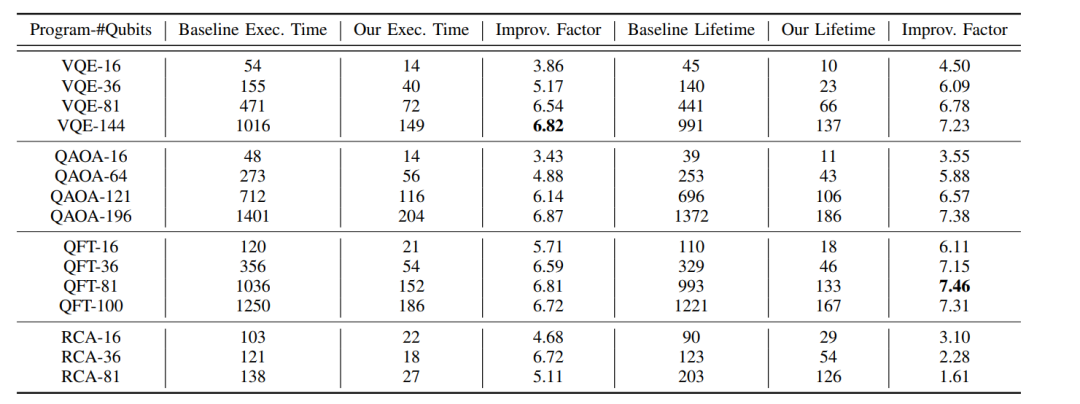
图3. DC-MBQC 与单 QPU 编译器(OneQ)的性能对比。
03
技术贡献:物理建模与系统抽象
本文的核心贡献在于跨越了光量子物理特性与计算机系统设计之间的鸿沟。通过提出全新的度量指标与分布式抽象,DC-MBQC 成功将底层的物理噪声和通信细节转化为上层的编译优化问题。
1. 核心度量:从“执行时间”到“所需光子寿命”
在量子计算中,如何在有限的相干时间内完成计算是保证保真度的关键。对于光量子平台,这一挑战的一个重要方面是光子的存储问题。光子作为飞行的量子比特,等待同步时必须在光纤延迟线中存储。由于光子在光纤中的丢失概率随时间呈指数级上升,存储时间的长短直接决定了计算的物理保真度。
现有的编译器通常以优化程序逻辑层面的“执行时间”为目标,忽略了物理层面光子存储的实际代价。为了弥补这一缺失,本文定义了“所需光子寿命”作为核心优化指标。在 MBQC 计算中,光子的同步等待需求可归纳为两个来源:
待聚合光子:为利用 RSG 产生的小型图态生成计算所需的大型图态,需要将来自不同小型图态的光子在同一聚合设备当中进行聚合。其中,较早产生的光子必须在延迟线中等待,直至其配对光子产生并到达聚合设备。
待测量光子:为纠正测量不确定性的影响,MBQC 中的单光子测量为自适应的,存在依赖关系的光子必须等待前序测量的经典结果反馈以确定当前的测量基。
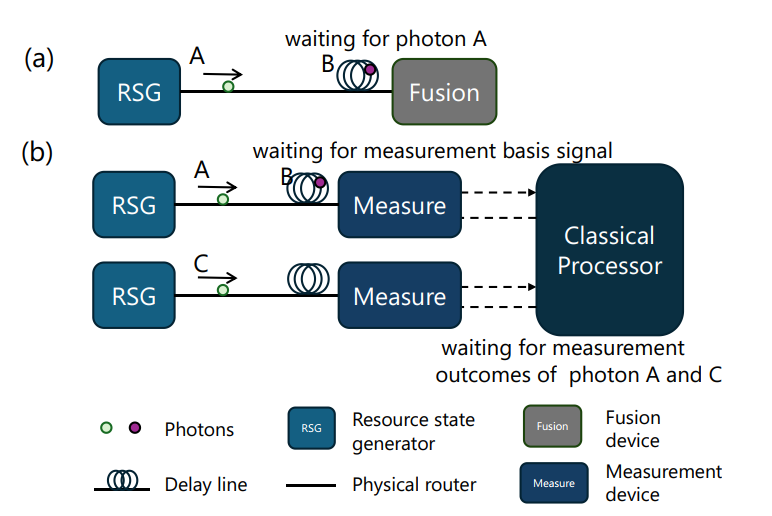
图4. 光子等待需求图解。在图(a)中,光子 B 需等待与其配对的光子 B 到达聚合设备,此后聚合操作方可执行。在图(b)中,光子 B 的测量基底依赖于光子 A 和 C 的测量结果,此时仍需等待经典处理器反馈以确定测量基底。
“所需光子寿命”这一度量将这些不同的等待需求统一量化,使得编译器能够直接针对硬件物理瓶颈进行优化。
2. 架构设计:基于“连接层”的编译-通信解耦
在分布式量子计算中,MBQC 面临着与量子电路模型截然不同的编译挑战。电路模型的分布式编译主要关注如何在多个处理器间分配逻辑量子比特,以最小化昂贵的远程门操作(如 Teledata 或 Telegate)。而在 MBQC 模型中,计算由基于大规模纠缠图态的单比特测量驱动,跨芯片互连通过不同芯片上的光子聚合实现。由于不同量子比特上操作的可交换性,MBQC 模型中的单 QPU 计算和跨 QPU 互连天然具有解耦的特性。这为 MBQC 模型的分布式架构设计提供了全新的可能。
分布式 MBQC 架构设计的基本问题是如何处理跨芯片的纠缠连接具体如何实现,即如何将逻辑计算图中被分配到不同 QPU 而需要聚合的光子(Connector)通过路由引导至同一聚合设备。一种直观的方案是在芯片边缘预留固定的物理区域专门用于通信,所有 Connector 全部编译至恰当的边缘位置并与其他 QPU 连接。然而,这种设计将通信功能与空间位置强行绑定,形成了一种僵化的空间约束,严重限制了单芯片编译器对逻辑计算子图进行全局布局优化的自由度。
为突破这一空间束缚,DC-MBQC 框架利用 MBQC 计算固有的三维(2D 空间 + 1D 时间)资源网格特性,提出了一种基于“连接层”的架构抽象:
时间维度的分层设计:在三维资源网格中,动态地插入专门用于处理通信的“连接层”。其他层设置专门执行本地计算任务的“执行层”,不处理跨芯片连接问题。
时空路由机制:位于执行层中的 Connector 不需要在当前层的二维空间内长途跋涉至芯片边缘。相反,它们通过层间聚变被“垂直”路由至时间轴上相邻的连接层,并在连接层中被路由至通信端口。
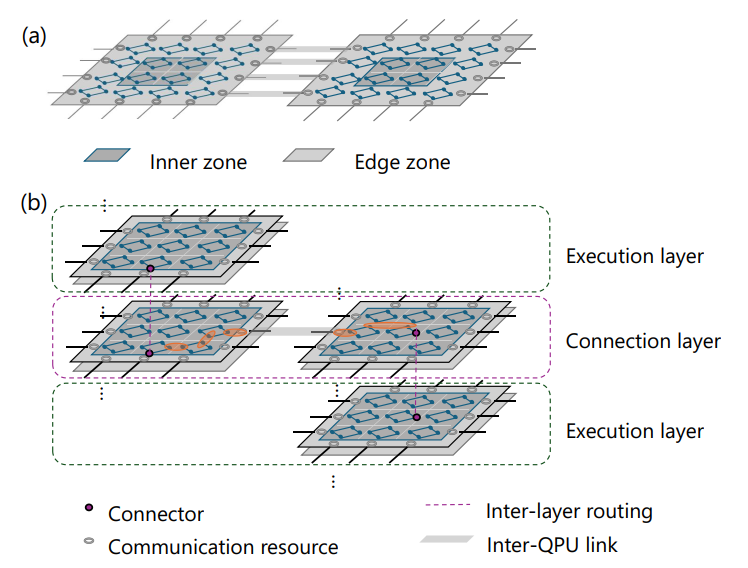
图5. 跨芯片连接方法图解。图(a)展示了预留边缘区域的方法,在此方法中,单 QPU 编译器必须将对应的 Connector 路由至特定的边缘位置。图(b)为本文提出的“连接层”方法。
这一抽象将单 QPU 上的编译与跨 QPU 的纠缠连接彻底解耦,利用时间维度的路由能力,彻底消除了物理通信端口位置对单 QPU 编译的空间约束。这一解耦使得单芯片编译器可以专注于本地逻辑计算图的优化,无需感知复杂的全局通信约束;而所有的跨芯片通信需求则被统一卸载到连接层进行处理。
基于此架构,复杂的分布式路由问题可被解耦为负载划分、通信与同步两方面。负载划分部分主要考虑通信切口最小化,而通信与同步方面主要考虑连接层的调度问题。
在负载划分方面,本文利用“模块度”这一概念提出了自适应的图划分算法,在利用多级 k-路图划分算法[5]均衡负载、最小化通信的同时,以模块度作为核心评价指标在负载均衡性与逻辑计算图子图完整性之间寻找最优权衡,为后续单 QPU 的编译工作降低复杂度。
在通信与同步方面,本文基于“连接层”这一架构抽象,将跨芯片的路由问题形式化为“层调度问题”,提供了其数学定义与 NP-hardness 的证明。这一抽象将单个光量子(Connector)的计算布局映射转化为了“执行层”与“连接层”的任务调度,实现了原有问题的极大简化。针对这一问题,本文设计了瓶颈驱动的迭代优化算法(BDIR)。在列表优先级调度给出的初始调度方案上,该算法采用全局视角的启发式策略进行优化:
定位瓶颈:首先识别出当前导致最大所需光子寿命的关键任务。
计算平衡点:以最小化所需光子寿命为目标,计算该任务在时间轴上的最佳位置。
动态重排:将瓶颈任务固定在平衡点,使用列表优先级调度算法调整其他任务。这种方法可以在满足问题约束的前提下大致保持原有的任务顺序,避免原有优良结构的大幅度破坏。
这种策略有效地减少了因同步等待产生的长所需光子寿命,实现了通信开销的最小化。
04
致 谢
特别感谢佐治亚理工学院的宋旨欣同学为本研究所做的的实质性贡献,包括他在研究过程的频繁讨论中深刻而富有启发性的建议,以及在论文文献综述、图表绘制和引言起草过程中提供的实质性帮助。同时,感谢匿名评审专家热情、细致和富有建设性的意见,这些意见给我们很大的鼓励和帮助。
参考文献
[1] "A manufacturable platform for photonic quantum computing." Nature 641, no. 8064 (2025): 876-883.
[2] Aghaee Rad, H., T. Ainsworth, R. N. Alexander, B. Altieri, M. F. Askarani, R. Baby, L. Banchi et al. "Scaling and networking a modular photonic quantum computer." Nature 638, no. 8052 (2025): 912-919.
[3] Zhang, Hezi, Anbang Wu, Yuke Wang, Gushu Li, Hassan Shapourian, Alireza Shabani, and Yufei Ding. "Oneq: A compilation framework for photonic one-way quantum computation." In Proceedings of the 50th Annual International Symposium on Computer Architecture, pp. 1-14. 2023.
[4] Zhang, Hezi, Jixuan Ruan, Dean Tullsen, Yufei Ding, Ang Li, and Travis S. Humble. "OneAdapt: Adaptive Compilation for Resource-Constrained Photonic One-Way Quantum Computing." arXiv preprint arXiv:2504.17116 (2025).
[5] Karypis, George, and Vipin Kumar. "Multilevel k-way hypergraph partitioning." In Proceedings of the 36th annual ACM/IEEE design automation conference, pp. 343-348. 1999.

图文 | 薛烨诚
PKU QUARK Lab
关于量子算法实验室
量子算法实验室 QUARK Lab (Laboratory for Quantum Algorithms: Theory and Practice) 由李彤阳博士于2021年创立。该实验室专注于研究量子计算机上的算法,主要探讨机器学习、优化、统计学、数论、图论等方向的量子算法及其相对于经典计算的量子加速;也包括近期 NISQ (Noisy, Intermediate-Scale Quantum Computers) 量子计算机上的量子算法。
实验室新闻:#PKU QUARK
实验室公众号:
课题组近期动态

NeurIPS 2025 | 计算一般形式多玩家博弈的相关均衡的近最优量子算法
NeurIPS 2025 | QCircuitBench: 面向大模型驱动的量子算法设计的基准测试

— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

点击“阅读原文”转论文链接
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢