报告主题:腾讯微信高效并行推理|基于因果注意力重构扩散语言模型
报告日期:1月15日(周四)10:30-11:30
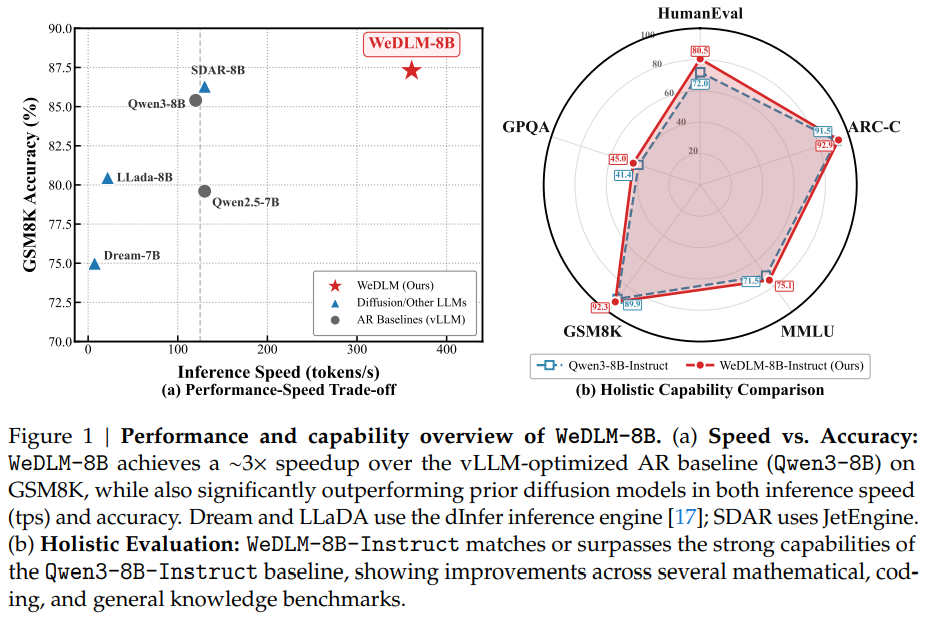
大语言模型(LLM)的自回归生成方式受限于逐词解码,推理效率面临瓶颈。虽然扩散语言模型(DLLM)支持并行生成,但由于依赖双向注意力机制,破坏了 KV Cache 的复用性,导致在实际部署中难以超越经过优化的自回归引擎(如 vLLM)。本次报告将介绍 WeDLM,这是一种基于标准因果注意力重构的扩散解码框架。我们通过拓扑重排机制,在保持严格因果掩码的同时实现了全上下文感知,使得并行生成能够完美兼容 KV Cache。结合流式并行解码策略,WeDLM 能够在保证生成质量的同时,实现超越 vLLM 部署的 AR 模型 的推理速度(在复杂推理任务上加速近 3 -10倍),为大模型的高效部署提供了全新的范式。刘瑷玮博士现任腾讯微信 AI(WeChat AI)研究员,主要从事大语言基座模型的研究工作。他于 2025 年 6 月获得清华大学软件学院博士学位,导师是闻立杰副教授;此前于 2020 年本科毕业于南京大学。在学术研究期间,他曾作为访问学者在伊利诺伊大学芝加哥分校(UIC)师从 Philip S. Yu 教授(ACM/IEEE Fellow),以及在香港中文大学(CUHK)师从 Irwin King 教授(ACM/IEEE Fellow)进行研究。
他在 ACL、ICLR、EMNLP、SIGKDD 等顶级会议及期刊上发表多篇论文,是开源工具包 MarkLLM 的项目负责人,并曾获 2025 年北京市优秀毕业生荣誉。
扫码报名
更多热门报告


内容中包含的图片若涉及版权问题,请及时与我们联系删除





评论
沙发等你来抢