

Transformers v5 https://hf.co/blog/transformers-v5 分词器的重构 https://github.com/huggingface/transformers/pull/40936/files
在深入 v5 的变更之前,我们先快速了解一下什么是分词,以及各个组件如何协同工作。
语言模型不能直接读取原始文本,它们只能处理一串整数 (通常叫做 token ID 或 input ID) 。分词就是将原始文本转换为这些 token ID 的过程。 (你可以在这个
在线演示 https://hf.co/spaces/Xenova/the-tokenizer-playground
分词 (Tokenization) 是自然语言处理和文本处理中的一个广泛概念。本文重点聚焦于大语言模型 (LLM) 中的分词过程,并主要基于
transformers https://github.com/huggingface/transformers tokenizers https://github.com/huggingface/tokenizers
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM3-3B")
text = "Hello world"
tokens = tokenizer(text)
print(tokens["input_ids"])
# [9906, 1917]
print(tokenizer.convert_ids_to_tokens(tokens["input_ids"]))
# ['Hello', 'Ġworld']
Token (词元) 是模型看到的最小单位,可以是单个字符、词、或词的一部分,例如 "play" 或 "##ing" ("##" 是一种表示方法,现在不懂没关系 🤗) 。词表 (vocab) 是一个映射表,记录每个唯一 token 对应的 ID。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM3-3B")
print(tokenizer.vocab)
# {'ÎĹÎľ': 106502, 'ĠPeel': 89694, '.languages': 91078, ...}
一个优秀的分词器能够将文本 压缩 为尽可能少的 token。token 越少,模型在不增加体积的前提下可利用的上下文就越多。训练分词器的核心,就是为你的数据集找到最佳的压缩规则。例如,如果你处理的是中文语料,可能会有
令人惊喜的结果 😉 https://x.com/suchenzang/status/1697862650053660721
分词是一个多阶段的过程,每个阶段都对文本进行一次转换:
| Normalizer | "HELLO World""hello world" | |
| Pre-tokenizer | "hello world"["hello", " world"] | |
| Model | ["hello", " world"][9906, 1917] | |
| Post-processor | [9906, 1917][1, 9906, 1917, 2] | |
| Decoder | [9906, 1917]"hello world" |
这些组件 彼此独立,你可以随意替换
normalizer https://hf.co/docs/tokenizers/en/api/normalizers 算法模型 https://hf.co/docs/tokenizers/en/api/models
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google/gemma-3-270m-it")
print(f"{tokenizer._tokenizer.normalizer=}")
# Replace(...)
print(f"{tokenizer._tokenizer.pre_tokenizer=}")
# Split(...)
print(f"{tokenizer._tokenizer.model=}")
# BPE(...)
print(f"{tokenizer._tokenizer.post_processor=}")
# TemplateProcessing(...)
print(f"{tokenizer._tokenizer.decoder=}")
# Sequence(decoders=[Replace(...), ByteFallback(), Fuse()])
目前主流的大模型分词器主要使用以下几种算法:
BPE (Byte Pair Encoding) :通过迭代地合并最常出现的字符对来进行分词。该算法具有确定性,结果可复现,因而被广泛使用。 阅读 BPE 详情 https://hf.co/learn/llm-course/en/chapter6/5
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")
print(tokenizer._tokenizer.model)
# BPE(...)
Unigram:采用概率模型,从大词表中选择最可能的切分方式,比 BPE 更灵活。 阅读 Unigram 详情 https://hf.co/learn/llm-course/en/chapter6/7
tokenizer = AutoTokenizer.from_pretrained("google-t5/t5-base")
print(tokenizer._tokenizer.model)
# Unigram(...)
WordPiece:与 BPE 类似,但使用基于概率的合并标准。 阅读 WordPiece 详情 https://hf.co/learn/llm-course/en/chapter6/6
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
print(tokenizer._tokenizer.model)
# WordPiece(...)
tokenizers https://github.com/huggingface/tokenizers
比如,当你直接用 tokenizers 库处理
SmolLM3-3B http://hf.co/HuggingFaceTB/SmolLM3-3B
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained("HuggingFaceTB/SmolLM3-3B")
encodings = tokenizer.encode("Hello world")
print(encodings.ids) # [9906, 1917]
print(encodings.tokens) # ['Hello', 'Ġworld']
这只是“裸分词”,只返回 ID 和对应的 token 字符串,没有其它功能。
但现在我们来看看缺失了什么。SmolLM3-3B 是一个 对话模型。当你与它交互时,通常会把输入组织成一段有“角色”的对话,比如 "user" 和 "assistant"。模型需要通过特殊的格式化 token 来识别这些角色和对话结构。而原始的 tokenizers 库并不了解这些语义,它只处理字符和 token ID 的转换,对对话格式一无所知。
这个问题由 transformers 库解决。虽然它主要是一个模型定义工具,但它也提供了一个分词器抽象层,封装了底层的 tokenizers 引擎,并加入了“模型感知”的功能。
下面是使用 transformers 封装后的分词示例:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM3-3B")
# Format a conversation using the model's chat template
prompt = "Give me a brief explanation of gravity in simple terms."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
print(text)
# <|im_start|>system
# ...
# <|im_start|>user
# Give me a brief explanation of gravity in simple terms.<|im_end|>
# <|im_start|>assistant
model_inputs = tokenizer([text], add_special_tokens=False, return_tensors="pt")
你可以看到,在分词之前,像 <|im_start|> 和 <|im_end|> 这样的特殊 token 已经被插入到了提示词中。这有助于模型识别每段对话的开始和结束位置,对理解对话结构非常重要。
transformers 分词器弥补了原始 tokenizers 库所缺失的功能,包括:
对话模板支持:通过 apply_chat_template方法,将对话内容格式化成模型需要的样式,并自动插入正确的特殊标记和分隔符;自动添加特殊 token:如起始 (BOS) 和结束 (EOS) 标记,会自动插入到模型期望的位置; 自动截断支持:指定 truncation=True,分词器会自动限制输入长度,不超过模型的最大上下文窗口;批量编码与自动填充:处理多个输入时,可自动使用正确的 padding token 进行对齐; 多种返回格式:你可以选择返回 PyTorch 张量 ( return_tensors="pt") 、NumPy 数组等格式,方便后续处理。
transformers 库为分词器设计了一套清晰的类层级结构。最上层是通用的基类,负责定义所有分词器的通用接口; 下面是不同的后端实现类,使用不同的引擎来执行实际的分词操作; 最底层是针对特定模型的分词器类,在在后端的基础上进行配置,适配各个具体模型的需求。
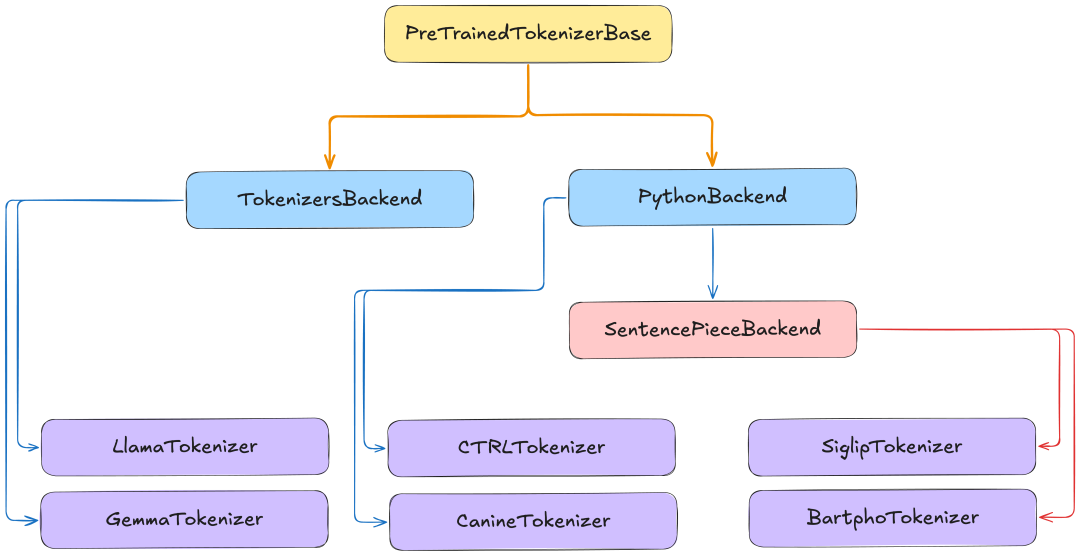 |
|---|
PreTrainedTokenizerBase https://github.com/huggingface/transformers/blob/7f52a2a4ea8ab49b7f069df7fac58a5b280d4919/src/transformers/tokenization_utils_base.py#L964C7
这个基类主要负责那些与具体分词后端无关的通用功能,包括:
特殊 token 属性:定义了如 bos_token(序列开始) 、eos_token(序列结束) 、pad_token(填充) 、unk_token(未知) 等属性,模型通过这些 token 识别序列边界或处理未知输入;编码接口:包括 __call__、encode和encode_plus方法,接收文本输入,返回 token ID、attention mask 等相关信息;解码接口: decode和batch_decode方法用于将 token ID 转换回原始文本;序列化功能: save_pretrained和from_pretrained方法用于将分词器保存到本地,或从预训练模型中加载分词器。它们负责下载所需文件、读取配置、管理本地存储等操作。对话模板支持: apply_chat_template方法也定义在这里,用于根据分词器配置中存储的 Jinja 模板格式化多轮对话内容。
transformers 中的每一个分词器最终都继承自 PreTrainedTokenizerBase,这个基类保证了所有分词器在行为和接口上的一致性,无论底层用的是哪种分词引擎。
PreTrainedTokenizerBase,并封装了 Rust 编写的 tokenizers 库。
TokenizersBackend https://github.com/huggingface/transformers/blob/7f52a2a4ea8ab49b7f069df7fac58a5b280d4919/src/transformers/tokenization_utils_tokenizers.py#L80C7
这个类内部保存了 Rust 分词器对象:
class TokenizersBackend(PreTrainedTokenizerBase):
def __init__(self, tokenizer_object, ...):
self._tokenizer = tokenizer_object # The Rust tokenizer
...
当你在一个继承自 TokenizersBackend 的分词器上调用编码方法时,实际的分词操作会被委托给底层的 Rust 分词器引擎来完成:
def _batch_encode_plus(self, batch_text_or_text_pairs, ...):
encodings = self._tokenizer.encode_batch(batch_text_or_text_pairs, ...)
计算密集型的任务由 Rust 后端执行,而 Python 封装则在此基础上添加与具体模型相关的功能。
很多模型专属的分词器都继承自 TokenizersBackend,例如:
LlamaTokenizerGemmaTokenizer
这些模型专属的分词器类会根据各自模型的需求,对后端进行配置,包括正确的词表、合并规则、特殊 token,以及标准化设置等,确保分词行为与模型训练时保持一致。
PreTrainedTokenizerBase。这个类的别名是
PythonBackend https://github.com/huggingface/transformers/blob/7f52a2a4ea8ab49b7f069df7fac58a5b280d4919/src/transformers/tokenization_python.py#L400 PreTrainedTokenizer https://github.com/huggingface/transformers/blob/7f52a2a4ea8ab49b7f069df7fac58a5b280d4919/src/transformers/tokenization_python.py#L1400C1
纯 Python 实现的分词器后端存在的原因主要有以下几点:
自定义分词逻辑:某些模型需要特殊的分词方式,这些方式无法通过标准的 tokenizers流程实现;兼容旧版本:一些老模型依赖于 Python 实现中的特定行为,需要保持兼容性。
继承自 PythonBackend (或其别名 PreTrainedTokenizer) 的模型分词器通常是一些较旧或特殊的模型,例如:
CTRLTokenizerCanineTokenizer
PythonBackend,专门用于支持那些使用 SentencePiece 的模型,尤其是许多由 Google 训练的模型。
SentencePieceBackend https://github.com/huggingface/transformers/blob/7f52a2a4ea8ab49b7f069df7fac58a5b280d4919/src/transformers/tokenization_utils_sentencepiece.py#L46 SentencePiece https://github.com/google/sentencepiece
该后端封装了一个 SentencePiece 分词器实例:
class SentencePieceBackend(PythonBackend):
def __init__(self, vocab_file, ...):
self.sp_model = spm.SentencePieceProcessor()
self.sp_model.Load(vocab_file)
...
使用 SentencePiece 分词的模型会继承自这个后端类,常见的例子包括:
SiglipTokenizerBartphoTokenizer
SentencePieceBackend 之所以继承自 PythonBackend,而不是直接继承 PreTrainedTokenizerBase,是因为它在接口设计以及填充 (padding) 和截断 (truncation) 逻辑方面,与 PythonBackend 有大量共通之处。
AutoTokenizer https://github.com/huggingface/transformers/blob/7f52a2a4ea8ab49b7f069df7fac58a5b280d4919/src/transformers/models/auto/tokenization_auto.py#L531
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
在幕后,AutoTokenizer 会自动执行以下几个步骤:
下载分词器配置文件:通过 from_pretrained方法,从 Hugging Face Hub (或本地目录) 获取tokenizer_config.json文件;识别模型类型:配置文件中包含元数据,用于 标明模型类型 https://hf.co/openai-community/gpt2/blob/main/config.json#L12 (例如 "gpt2"、"llama"、"bert") ;查找对应的分词器类: AutoTokenizer维护了一个名为TOKENIZER_MAPPING_NAMES https://github.com/huggingface/transformers/blob/7f52a2a4ea8ab49b7f069df7fac58a5b280d4919/src/transformers/models/auto/tokenization_auto.py#L64 的映射表,用于将模型类型对应到具体的分词器类名:
TOKENIZER_MAPPING_NAMES = {
"gpt2": "GPT2Tokenizer",
"llama": "LlamaTokenizer",
"bert": "BertTokenizer",
...
}
实例化正确的分词器类: AutoTokenizer会导入并调用对应分词器类的from_pretrained方法;返回配置好的分词器:最终返回一个已完成初始化、与指定模型完全匹配的分词器实例,可直接使用。
整个 transformers 的分词器系统是一个分层架构,具体如下:
| 入口层 | AutoTokenizer | |
| 模型专用层 | LlamaTokenizerGPT2Tokenizer 等 | |
| 后端层 | TokenizersBackendPythonBackend、SentencePieceBackend | |
| 基础层 | PreTrainedTokenizerBase | |
| 底层引擎 | tokenizers |
Transformers v5 最重要的更新,是在设计理念上的转变:现在的分词器,就像 PyTorch 中的 nn.Module 一样,先定义架构,再加载参数。
在 v4 中,分词器是一个“黑盒”,和预训练好的词表强绑定在一起。如果你加载 LlamaTokenizerFast,你无法轻易回答这些基本问题:
它是 BPE 还是 Unigram? 它是如何标准化文本的? 使用了哪种预分词策略? 它有哪些特殊 token?这些 token 的位置是固定的吗?
在以前的版本中,__init__ 方法完全不会透露这些信息。你必须深入查看序列化文件,或者查阅外部文档,才能弄清楚这个分词器到底是如何工作的。
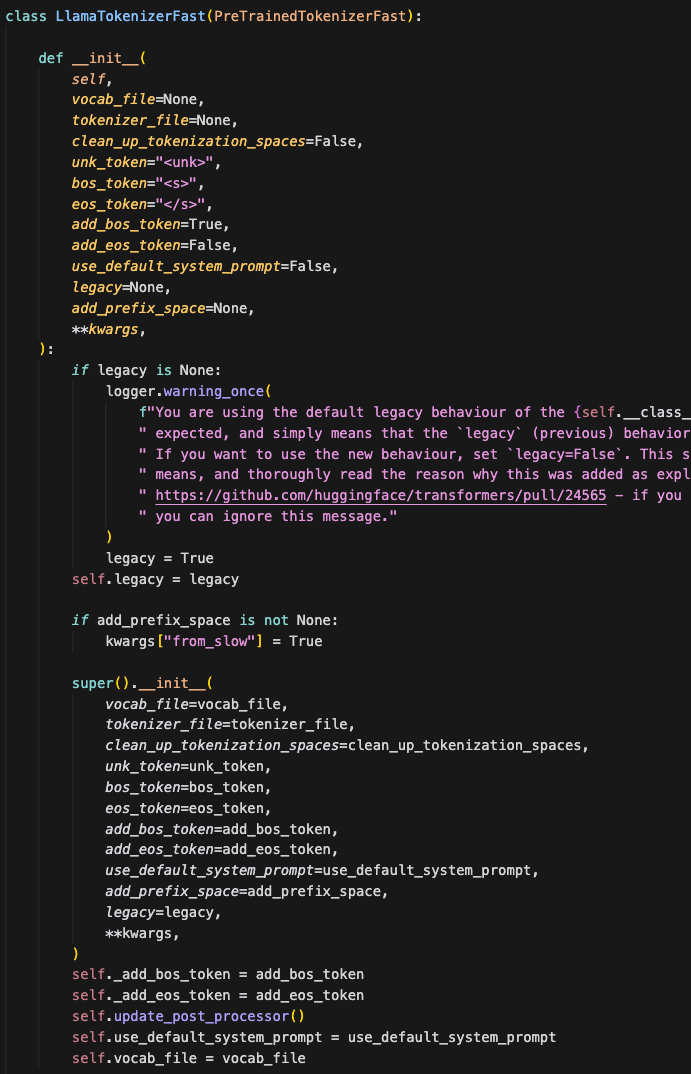 |
|---|
LlamaTokenizerFast,结构隐藏在文件内部 |
此外,v4 中每个模型都维护两份分词器代码:
一个“慢速”的纯 Python 分词器 (如 LlamaTokenizer,继承自PreTrainedTokenizer) ;一个“快速”的 Rust 实现 (如 LlamaTokenizerFast,继承自PreTrainedTokenizerFast) 。
这就意味着:
每个模型需要维护两个分词器文件 (例如: tokenization_llama.py和tokenization_llama_fast.py)大量重复代码,分散在数百个模型中 快慢版本行为不一致,容易引发隐蔽的 bug 测试代码不断膨胀,专门用来验证 slow 和 fast 分词器输出是否一致 用户混淆:不知道什么时候该用哪一个分词器版本
最糟糕的是,你无法创建一个空的分词器架构。如果你想用自己的数据训练一个 LLaMA 风格的分词器,没有简单的方法可以初始化一个“空白”的 LLaMA 分词器并填入自定义的词表和合并规则。在旧版本中,分词器只能作为已训练好的 checkpoint 存在,而不是一个可配置、可定制的模板。
在 v5 中,分词器的架构 (包括 normalizer、pre-tokenizer、分词算法模型、post-processor、decoder) 与训练得到的参数 (如词表、合并规则) 被明确分离开来。这种设计方式就像 PyTorch 将模型结构与权重参数分开一样。
在 PyTorch 中,使用 nn.Module 时,通常是先定义网络结构:
from torch import nn
model = nn.Sequential(
nn.Embedding(vocab_size, embed_dim),
nn.Linear(embed_dim, hidden_dim),
)
# Architecture defined; weights initialized randomly or loaded later
v5 的分词器遵循了同样的模式:
from transformers import LlamaTokenizer
# Instantiate the architecture
tokenizer = LlamaTokenizer()
# Train on your own data to fill in vocab and merges
tokenizer.train(files=["my_corpus.txt"])
现在,分词器类会明确声明自己的结构。在 v5 中查看 LlamaTokenizer,你可以一眼看出它的分词行为:
它使用的是 BPE 分词模型 它可能会在文本前添加一个 前缀空格 它的特殊 token (如 unk、bos、eos) 位于词表中的固定位置它 不会对文本进行标准化 它的解码器 会将特殊的▁字符还原为空格
它使用的是 BPE 分词模型 https://github.com/huggingface/transformers/blob/0a8465420eecbac1c6d7dd9f45c08dd96b8c5027/src/transformers/models/llama/tokenization_llama.py#L92 它不会对文本进行标准化 https://github.com/huggingface/transformers/blob/0a8465420eecbac1c6d7dd9f45c08dd96b8c5027/src/transformers/models/llama/tokenization_llama.py#L121 它的解码器 https://github.com/huggingface/transformers/blob/0a8465420eecbac1c6d7dd9f45c08dd96b8c5027/src/transformers/models/llama/tokenization_llama.py#L122
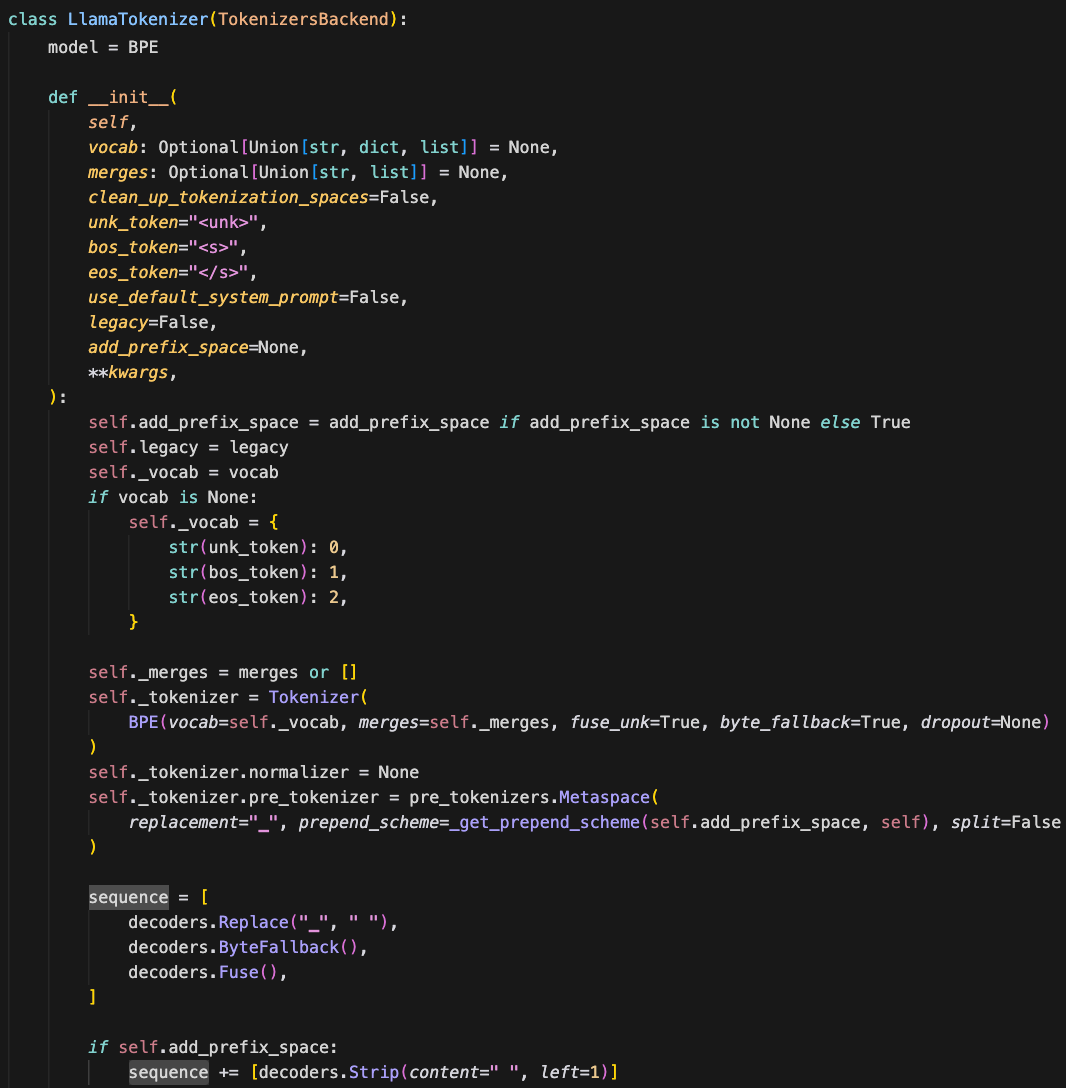 |
|---|
LlamaTokenizer:结构一目了然 |
这些关键信息在 v4 中是隐藏在序列化文件中的,根本无法直接看到。
v5 将原本的“双文件系统” 统一为每个模型只需一个分词器文件。以 LlamaTokenizer 为例,它现在继承自 TokenizersBackend,这个类封装了基于 Rust 的分词器实现 (之前作为 “fast” 版本存在) ,并且现在成为默认实现。
而原本的“慢速”Python 实现则被明确地封装在 PythonBackend 中;对于使用 SentencePiece 的模型,仍然使用 SentencePieceBackend。但整体而言,基于 Rust 的分词器现在是官方推荐的默认选项。
这样就消除了:
快速和慢速版本的重复代码; Tokenizer与TokenizerFast令人困惑的命名;用于验证两者输出一致性的庞大测试代码;
现在,用户只需通过一个统一的入口即可使用分词器。对于有高级自定义需求的用户,仍然可以访问底层组件进行调整;但整个库不再强制大家在两个平行的实现 (慢速和快速) 之间反复切换。
假设你想训练一个行为与 LLaMA 完全一致的分词器:使用相同的标准化方式、预分词策略、BPE 分词模型,但在特定领域的语料上 (如医学、法律或新语言) 进行训练。 在 v4 中,这样的需求需要你从底层 tokenizers 库拼接整个 pipeline,过程繁琐。 而在 v5 中,只需直接实例化分词器架构并调用 train 即可完成训练:
from transformers import LlamaTokenizer
from datasets import load_dataset
# Initialize blank tokenizer
tokenizer = LlamaTokenizer()
dataset = load_dataset("wikitext", "wikitext-2-raw-v1", split="train")
def get_training_corpus():
batch = 1000
for i in range(0, len(dataset), batch):
yield dataset[i : i + batch]["text"]
trained_tokenizer = tokenizer.train_new_from_iterator(
text_iterator=get_training_corpus(),
vocab_size=32000,
length=len(dataset),
show_progress=True,
)
trained_tokenizer.push_to_hub("my_custom_tokenizer")
tokenizer = LlamaTokenizer.from_pretrained("my_custom_tokenizer")
最终得到的分词器将拥有你自定义的词表和合并规则,但在处理文本时的行为将与标准的 LLaMA 分词器完全一致:空格处理、特殊 token 规则、解码行为都相同。
tokenization_X.py 和 tokenization_X_fast.py) | tokenization_X.py) | |
TokenizersBackend) | ||
tokenizer.train(...) | ||
tokenizer.normalizer) | ||
PreTrainedTokenizerPreTrainedTokenizerFast | TokenizersBackendSentencePieceBackend, PythonBackend) |
从“只能加载训练好的分词器”到“可以像构建模型一样配置分词器架构”,这一转变让整个库变得更加模块化、透明,也更符合开发者在构建机器学习系统时的思维方式。
Transformers v5 带来了三大分词器方面的改进:
每个模型只有一个分词器文件,不再区分 slow / fast 实现 架构可视化:你可以轻松查看分词器的结构,包括 normalizer、预分词器、解码器等 支持从零训练:现在你可以根据任意模型风格,训练出专属分词器
而且,transformers 对 tokenizers 库的封装依然保留,它为模型增加了上下文长度处理、对话模板支持、特殊 token 管理等功能。这些是原始分词器不具备的。v5 的变化只是让这个封装层变得更加清晰、可配置。
如果你想深入学习分词器,这些资源非常值得一看:
一起手动实现 GPT 分词器 每个开发者都应了解的分词器陷阱 Chat 模板深入解读 社区收集的一系列分词器资源
一起手动实现 GPT 分词器 https://youtu.be/zduSFxRajkE?si=ZAfCjZjpyPHsnyfF 每个开发者都应了解的分词器陷阱 https://hf.co/blog/qgallouedec/gotchas-in-tokenizer-behavior Chat 模板深入解读 https://hf.co/blog/chat-templates 社区收集的一系列分词器资源 https://x.com/ariG23498/status/1999058214906888237
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢