

今天,智谱联合华为开源新一代图像生成模型GLM-Image,模型基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成从数据到训练的全流程,是首个在国产芯片上完成全程训练的SOTA多模态模型。
GLM-Image采用自主创新的「自回归+扩散解码器」混合架构,实现了图像生成与语言模型的联合,是我们面向以Nano Banana Pro为代表的新一代「认知型生成」技术范式的一次重要探索。
核心亮点如下:
- 架构革新,面向「认知型生成」的技术探索:采用创新的「自回归 + 扩散编码器」混合架构,兼顾全局指令理解与局部细节刻画,克服了海报、PPT、科普图等知识密集型场景生成难题,向探索以Nano Banana Pro为代表的新一代“知识+推理”的认知型生成模型迈出了重要一步。
- 首个在国产芯片完成全程训练的SOTA模型:模型自回归结构基座基于昇腾Atlas 800T A2设备与昇思MindSpore AI框架,完成了从数据预处理到大规模训练的全流程构建,验证了在国产全栈算力底座上训练前沿模型的可行性。
- 文字渲染开源SOTA:在CVTG-2K(复杂视觉文本生成)和LongText-Bench(长文本渲染)榜单获得开源第一,尤其擅长汉字生成任务。
- 高性价比与速度优化:API调用模式下,生成一张图片仅需0.1元,速度优化版本即将更新。
架构创新:读懂指令,写对文字
近期,以Nano Banana Pro为代表的闭源图像生成模型正在推动图像生成与大语言模型的深度融合。技术范式正从单一的图像生成,进化为兼具世界知识与推理能力的「认知型生成」。这些模型在海报、PPT、科普图等知识密集型场景及高保真细节呈现上表现惊艳,展现了这一技术范式的优势。
GLM-Image正是我们面向「认知型生成」技术范式一次重要探索。这是首个开源的工业表现级离散自回归图像生成模型,我们希望借此与开源社区分享我们在这一前沿方向的技术路径与实践思考。
- 创新架构让模型读懂写对:面对传统模型在“理解复杂指令”与“精准绘制文字”上难以兼顾的问题,GLM-Image 引入了「自回归+扩散解码器」混合架构,创新地融合了9B大小的自回归模型与7B大小的DiT扩散解码器。前者利用其语言模型的底座优势,专注于提升对指令的语义理解和画面的全局构图;后者配合Glyph Encoder的文本编码器,专注于还原图像的高频细节和文字笔画,以此改善模型“提笔忘字”的现象。
- 多分辨率自适应:通过改进Tokenizer策略,GLM-Image能够自适应处理多种分辨率,原生支持从1024x1024到2048×2048尺寸的任意比例图像的生成任务,无需重新训练。
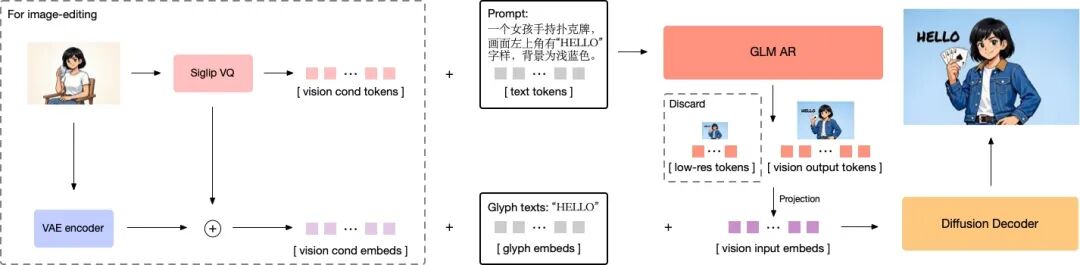
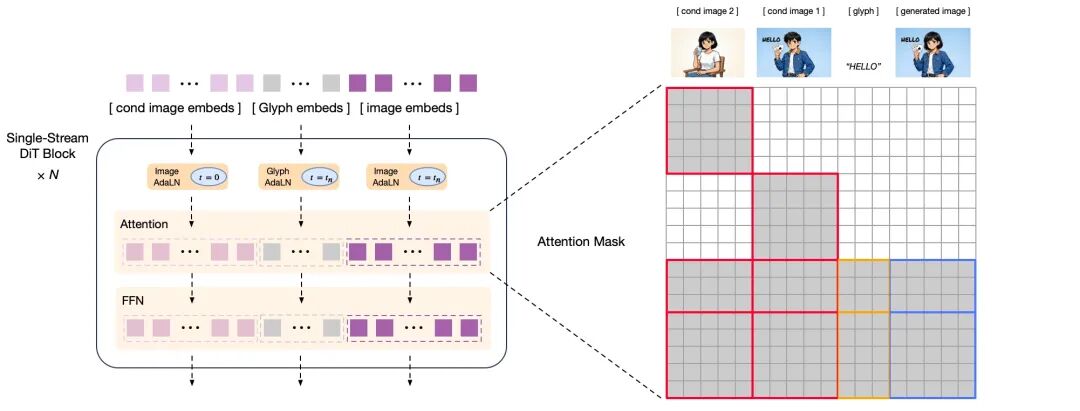
解码器结构示意图
GLM-Image技术报告:https://z.ai/blog/glm-image
开源SOTA:更擅长文字密集生成任务
基于上述架构创新,GLM-Image在文字渲染的权威榜单中达到开源SOTA水平。
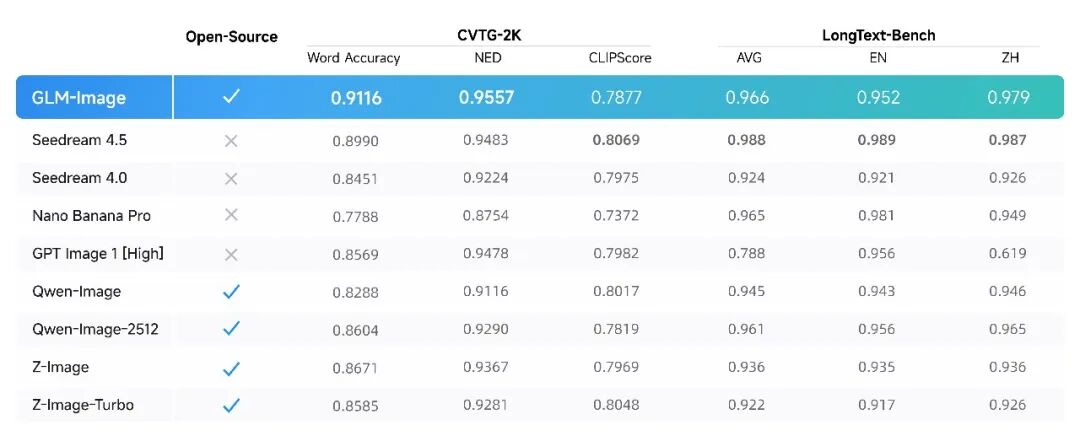
- CVTG-2K(复杂视觉文字生成)榜单核心考察模型在图像中同时生成多处文字的准确性。在多区域文字生成准确率上,GLM-Image凭借0.9116的Word Accuracy(文字准确率)成绩,位列开源模型第一。在NED(归一化编辑距离)指标上,GLM-Image同样以0.9557领先,表明其生成的文字与目标文字高度一致,错字、漏字情况更少。
- LongText-Bench(长文本渲染)榜单考察模型渲染长文本、多行文字的准确性,覆盖招牌、海报、PPT、对话框等8种文字密集场景,并分设中英双语测试,GLM-Image以英文0.952、中文0.979的成绩位列开源模型第一。
首个国产芯片训练出的SOTA模型
GLM-Image是我们对国产计算生态的一次深度探索与验证。其自回归结构基座从早期的数据预处理到最终的大规模预训练,全流程均在昇腾Atlas 800T A2设备上完成。
依托昇腾NPU和昇思MindSpore AI框架,使用动态图多级流水下发、高性能融合算子、多流并行等特性,我们自研了模型训练套件,全面优化数据预处理、预训练、SFT和RL的端到端流程。通过动态图的多级流水优化机制,将Host侧算子下发的关键阶段流水化并高度重叠,消除下发瓶颈;通过多流并行策略,通信和计算互掩,打破文本梯度同步、图像特征广播等操作的通信墙,极致优化性能;使用AdamW EMA、COC、RMS Norm等昇腾亲和的高性能融合算子,同步提升训练的稳定性和性能。
GLM-Image是首个在国产芯片上完成全流程训练的SOTA多模态模型,验证了在国产全栈算力底座上训练高性能多模态生成模型的可行性。我们希望这一实践能为社区挖掘国产算力潜力提供有价值的参考。

demo
让我们来看看GLM-Image在实际的复杂图文任务中的表现。
场景一:科普插画
GLM-Image 更擅长绘制包含复杂逻辑流程与文字说明的科普插画及原理示意图。
点击查看大图
场景二:多格图画
在生成电商图、漫画等多格图画时,GLM-Image能够保持风格和主体的一致性,并保障多处文字生成的准确率。

场景三:社交媒体图文封面
GLM-Image 适用于制作社交媒体封面及内容等排版复杂的图片,让您的创作更自由丰富。



点击查看大图
场景四:商业海报
GLM-Image 能够生成构图富有设计感、文字嵌入准确的节日海报与商业宣传图。



点击查看大图
场景五:写实摄影
在文字渲染以外,GLM-Image也同样擅长生成各种景别和尺寸的人像、宠物、风景、静物。

开源与在线体验
在线体验
开放平台:https://bigmodel.cn/trialcenter/modeltrial/image
即将上线Z.ai、智谱清言
API接入
- 开放平台:https://docs.bigmodel.cn/cn/guide/models/image-generation/glm-image
- GLM Coding Plan后续将接入GLM-Image MCP,现有订阅用户可直接使用。
开源部署
- GitHub:https://github.com/zai-org/GLM-Image
- Hugging Face:https://huggingface.co/zai-org/GLM-Image
- 魔搭社区:https://modelscope.cn/models/ZhipuAI/GLM-Image
GLM-Image技术报告:https://z.ai/blog/glm-image
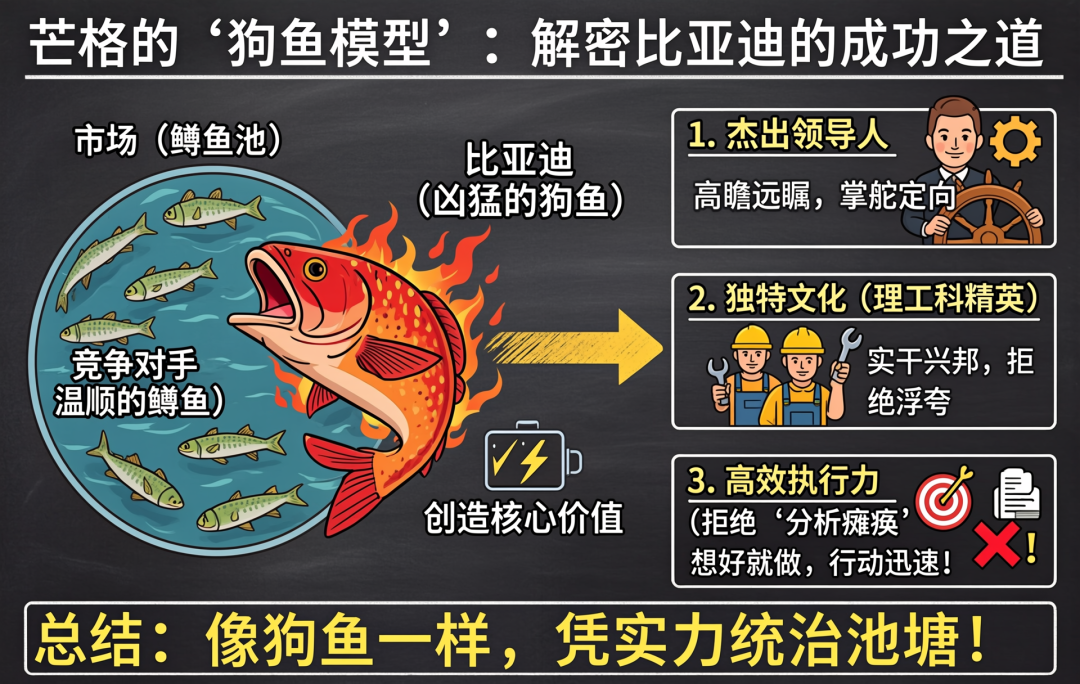
最后,我们用GLM-Image生成的一张图总结一下模型的核心要点。

我们期待GLM-Image能成为您创意的得力助手,也欢迎社区广大用户和开发者提出宝贵建议,共同推动国产开源图像生成模型的发展。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢